 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReviewGrounder: Improving Review Substantiveness with Rubric-Guided, Tool-Integrated Agents
Apr 15, 2026The rapid rise in AI conference submissions has driven increasing exploration of large language models (LLMs) for peer review support. However, LLM-based reviewers often generate superficial, formulaic comments lacking substantive, evidence-grounded feedback. We attribute this to the underutilization of two key components of human reviewing: explicit rubrics and contextual grounding in existing work. To address this, we introduce REVIEWBENCH, a benchmark evaluating review text according to paper-specific rubrics derived from official guidelines, the paper's content, and human-written reviews. We further propose REVIEWGROUNDER, a rubric-guided, tool-integrated multi-agent framework that decomposes reviewing into drafting and grounding stages, enriching shallow drafts via targeted evidence consolidation. Experiments on REVIEWBENCH show that REVIEWGROUNDER, using a Phi-4-14B-based drafter and a GPT-OSS-120B-based grounding stage, consistently outperforms baselines with substantially stronger/larger backbones (e.g., GPT-4.1 and DeepSeek-R1-670B) in both alignment with human judgments and rubric-based review quality across 8 dimensions. The code is available \href{https://github.com/EigenTom/ReviewGrounder}{here}.
Orbital Transformers for Predicting Wavefunctions in Time-Dependent Density Functional Theory
Mar 03, 2026We aim to learn wavefunctions simulated by time-dependent density functional theory (TDDFT), which can be efficiently represented as linear combination coefficients of atomic orbitals. In real-time TDDFT, the electronic wavefunctions of a molecule evolve over time in response to an external excitation, enabling first-principles predictions of physical properties such as optical absorption, electron dynamics, and high-order response. However, conventional real-time TDDFT relies on time-consuming propagation of all occupied states with fine time steps. In this work, we propose OrbEvo, which is based on an equivariant graph transformer architecture and learns to evolve the full electronic wavefunction coefficients across time steps. First, to account for external field, we design an equivariant conditioning to encode both strength and direction of external electric field and break the symmetry from SO(3) to SO(2). Furthermore, we design two OrbEvo models, OrbEvo-WF and OrbEvo-DM, using wavefunction pooling and density matrix as interaction method, respectively. Motivated by the central role of the density functional in TDDFT, OrbEvo-DM encodes the density matrix aggregated from all occupied electronic states into feature vectors via tensor contraction, providing a more intuitive approach to learn the time evolution operator. We adopt a training strategy specifically tailored to limit the error accumulation of time-dependent wavefunctions over autoregressive rollout. To evaluate our approach, we generate TDDFT datasets consisting of 5,000 different molecules in the QM9 dataset and 1,500 molecular configurations of the malonaldehyde molecule in the MD17 dataset. Results show that our OrbEvo model accurately captures quantum dynamics of excited states under external field, including time-dependent wavefunctions, time-dependent dipole moment, and optical absorption spectra.
Tensor Decomposition Networks for Fast Machine Learning Interatomic Potential Computations
Jul 01, 2025$\rm{SO}(3)$-equivariant networks are the dominant models for machine learning interatomic potentials (MLIPs). The key operation of such networks is the Clebsch-Gordan (CG) tensor product, which is computationally expensive. To accelerate the computation, we develop tensor decomposition networks (TDNs) as a class of approximately equivariant networks whose CG tensor products are replaced by low-rank tensor decompositions, such as the CANDECOMP/PARAFAC (CP) decomposition. With the CP decomposition, we prove (i) a uniform bound on the induced error of $\rm{SO}(3)$-equivariance, and (ii) the universality of approximating any equivariant bilinear map. To further reduce the number of parameters, we propose path-weight sharing that ties all multiplicity-space weights across the $O(L^3)$ CG paths into a single path without compromising equivariance, where $L$ is the maximum angular degree. The resulting layer acts as a plug-and-play replacement for tensor products in existing networks, and the computational complexity of tensor products is reduced from $O(L^6)$ to $O(L^4)$. We evaluate TDNs on PubChemQCR, a newly curated molecular relaxation dataset containing 105 million DFT-calculated snapshots. We also use existing datasets, including OC20, and OC22. Results show that TDNs achieve competitive performance with dramatic speedup in computations.
Efficient Prediction of SO(3)-Equivariant Hamiltonian Matrices via SO(2) Local Frames
Jun 11, 2025We consider the task of predicting Hamiltonian matrices to accelerate electronic structure calculations, which plays an important role in physics, chemistry, and materials science. Motivated by the inherent relationship between the off-diagonal blocks of the Hamiltonian matrix and the SO(2) local frame, we propose a novel and efficient network, called QHNetV2, that achieves global SO(3) equivariance without the costly SO(3) Clebsch-Gordan tensor products. This is achieved by introducing a set of new efficient and powerful SO(2)-equivariant operations and performing all off-diagonal feature updates and message passing within SO(2) local frames, thereby eliminating the need of SO(3) tensor products. Moreover, a continuous SO(2) tensor product is performed within the SO(2) local frame at each node to fuse node features, mimicking the symmetric contraction operation. Extensive experiments on the large QH9 and MD17 datasets demonstrate that our model achieves superior performance across a wide range of molecular structures and trajectories, highlighting its strong generalization capability. The proposed SO(2) operations on SO(2) local frames offer a promising direction for scalable and symmetry-aware learning of electronic structures. Our code will be released as part of the AIRS library https://github.com/divelab/AIRS.
Mitigating Spurious Correlations in LLMs via Causality-Aware Post-Training
Jun 11, 2025While large language models (LLMs) have demonstrated remarkable capabilities in language modeling, recent studies reveal that they often fail on out-of-distribution (OOD) samples due to spurious correlations acquired during pre-training. Here, we aim to mitigate such spurious correlations through causality-aware post-training (CAPT). By decomposing a biased prediction into two unbiased steps, known as \textit{event estimation} and \textit{event intervention}, we reduce LLMs' pre-training biases without incurring additional fine-tuning biases, thus enhancing the model's generalization ability. Experiments on the formal causal inference benchmark CLadder and the logical reasoning dataset PrOntoQA show that 3B-scale language models fine-tuned with CAPT can outperform both traditional SFT and larger LLMs on in-distribution (ID) and OOD tasks using only 100 ID fine-tuning samples, demonstrating the effectiveness and sample efficiency of CAPT.
NeurIPS 2024 ML4CFD Competition: Results and Retrospective Analysis
Jun 10, 2025The integration of machine learning (ML) into the physical sciences is reshaping computational paradigms, offering the potential to accelerate demanding simulations such as computational fluid dynamics (CFD). Yet, persistent challenges in accuracy, generalization, and physical consistency hinder the practical deployment of ML models in scientific domains. To address these limitations and systematically benchmark progress, we organized the ML4CFD competition, centered on surrogate modeling for aerodynamic simulations over two-dimensional airfoils. The competition attracted over 240 teams, who were provided with a curated dataset generated via OpenFOAM and evaluated through a multi-criteria framework encompassing predictive accuracy, physical fidelity, computational efficiency, and out-of-distribution generalization. This retrospective analysis reviews the competition outcomes, highlighting several approaches that outperformed baselines under our global evaluation score. Notably, the top entry exceeded the performance of the original OpenFOAM solver on aggregate metrics, illustrating the promise of ML-based surrogates to outperform traditional solvers under tailored criteria. Drawing from these results, we analyze the key design principles of top submissions, assess the robustness of our evaluation framework, and offer guidance for future scientific ML challenges.
A Two-Phase Deep Learning Framework for Adaptive Time-Stepping in High-Speed Flow Modeling
Jun 09, 2025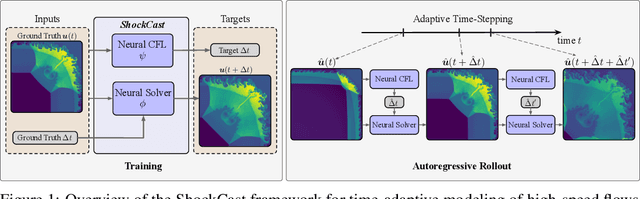

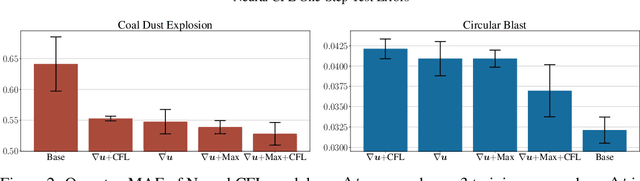
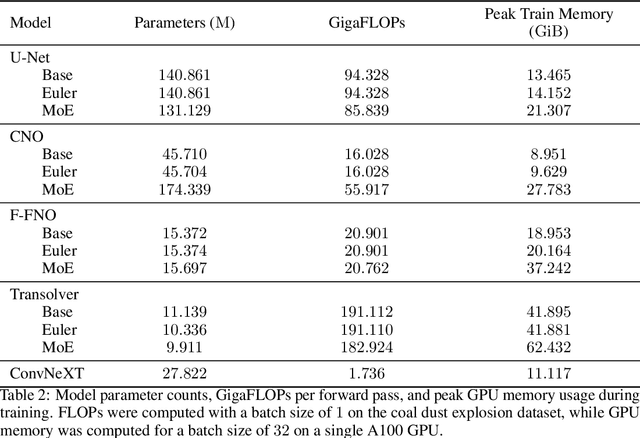
We consider the problem of modeling high-speed flows using machine learning methods. While most prior studies focus on low-speed fluid flows in which uniform time-stepping is practical, flows approaching and exceeding the speed of sound exhibit sudden changes such as shock waves. In such cases, it is essential to use adaptive time-stepping methods to allow a temporal resolution sufficient to resolve these phenomena while simultaneously balancing computational costs. Here, we propose a two-phase machine learning method, known as ShockCast, to model high-speed flows with adaptive time-stepping. In the first phase, we propose to employ a machine learning model to predict the timestep size. In the second phase, the predicted timestep is used as an input along with the current fluid fields to advance the system state by the predicted timestep. We explore several physically-motivated components for timestep prediction and introduce timestep conditioning strategies inspired by neural ODE and Mixture of Experts. As ShockCast is the first framework for learning high-speed flows, we evaluate our methods by generating two supersonic flow datasets, available at https://huggingface.co/datasets/divelab. Our code is publicly available as part of the AIRS library (https://github.com/divelab/AIRS).
Curriculum Reinforcement Learning from Easy to Hard Tasks Improves LLM Reasoning
Jun 07, 2025We aim to improve the reasoning capabilities of language models via reinforcement learning (RL). Recent RL post-trained models like DeepSeek-R1 have demonstrated reasoning abilities on mathematical and coding tasks. However, prior studies suggest that using RL alone to improve reasoning on inherently difficult tasks is less effective. Here, we draw inspiration from curriculum learning and propose to schedule tasks from easy to hard (E2H), allowing LLMs to build reasoning skills gradually. Our method is termed E2H Reasoner. Empirically, we observe that, although easy tasks are important initially, fading them out through appropriate scheduling is essential in preventing overfitting. Theoretically, we establish convergence guarantees for E2H Reasoner within an approximate policy iteration framework. We derive finite-sample complexity bounds and show that when tasks are appropriately decomposed and conditioned, learning through curriculum stages requires fewer total samples than direct learning. Experiments across multiple domains show that E2H Reasoner significantly improves the reasoning ability of small LLMs (1.5B to 3B), which otherwise struggle when trained with vanilla RL alone, highlighting the effectiveness of our method.
Toward Greater Autonomy in Materials Discovery Agents: Unifying Planning, Physics, and Scientists
Jun 05, 2025We aim at designing language agents with greater autonomy for crystal materials discovery. While most of existing studies restrict the agents to perform specific tasks within predefined workflows, we aim to automate workflow planning given high-level goals and scientist intuition. To this end, we propose Materials Agent unifying Planning, Physics, and Scientists, known as MAPPS. MAPPS consists of a Workflow Planner, a Tool Code Generator, and a Scientific Mediator. The Workflow Planner uses large language models (LLMs) to generate structured and multi-step workflows. The Tool Code Generator synthesizes executable Python code for various tasks, including invoking a force field foundation model that encodes physics. The Scientific Mediator coordinates communications, facilitates scientist feedback, and ensures robustness through error reflection and recovery. By unifying planning, physics, and scientists, MAPPS enables flexible and reliable materials discovery with greater autonomy, achieving a five-fold improvement in stability, uniqueness, and novelty rates compared with prior generative models when evaluated on the MP-20 data. We provide extensive experiments across diverse tasks to show that MAPPS is a promising framework for autonomous materials discovery.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.