 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Model Editing for LLM Personalization
Dec 15, 2025Personalization is becoming indispensable for LLMs to align with individual user preferences and needs. Yet current approaches are often computationally expensive, data-intensive, susceptible to catastrophic forgetting, and prone to performance degradation in multi-turn interactions or when handling implicit queries. To address these challenges, we conceptualize personalization as a model editing task and introduce Personalization Editing, a framework that applies localized edits guided by clustered preference representations. This design enables precise preference-aligned updates while preserving overall model capabilities. In addition, existing personalization benchmarks frequently rely on persona-based dialogs between LLMs rather than user-LLM interactions, or focus primarily on stylistic imitation while neglecting information-seeking tasks that require accurate recall of user-specific preferences. We introduce User Preference Question Answering (UPQA), a short-answer QA dataset constructed from in-situ user queries with varying levels of difficulty. Unlike prior benchmarks, UPQA directly evaluates a model's ability to recall and apply specific user preferences. Across experimental settings, Personalization Editing achieves higher editing accuracy and greater computational efficiency than fine-tuning, while outperforming prompting-based baselines in multi-turn conversations and implicit preference questions settings.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.
AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents
Apr 13, 2025



A/B testing experiment is a widely adopted method for evaluating UI/UX design decisions in modern web applications. Yet, traditional A/B testing remains constrained by its dependence on the large-scale and live traffic of human participants, and the long time of waiting for the testing result. Through formative interviews with six experienced industry practitioners, we identified critical bottlenecks in current A/B testing workflows. In response, we present AgentA/B, a novel system that leverages Large Language Model-based autonomous agents (LLM Agents) to automatically simulate user interaction behaviors with real webpages. AgentA/B enables scalable deployment of LLM agents with diverse personas, each capable of navigating the dynamic webpage and interactively executing multi-step interactions like search, clicking, filtering, and purchasing. In a demonstrative controlled experiment, we employ AgentA/B to simulate a between-subject A/B testing with 1,000 LLM agents Amazon.com, and compare agent behaviors with real human shopping behaviors at a scale. Our findings suggest AgentA/B can emulate human-like behavior patterns.
Learning with Less: Knowledge Distillation from Large Language Models via Unlabeled Data
Nov 12, 2024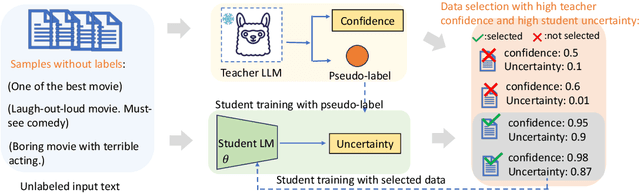


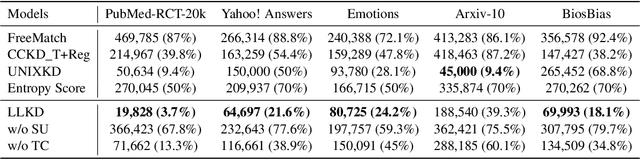
In real-world NLP applications, Large Language Models (LLMs) offer promising solutions due to their extensive training on vast datasets. However, the large size and high computation demands of LLMs limit their practicality in many applications, especially when further fine-tuning is required. To address these limitations, smaller models are typically preferred for deployment. However, their training is hindered by the scarcity of labeled data. In contrast, unlabeled data is often readily which can be leveraged by using LLMs to generate pseudo-labels for training smaller models. This enables the smaller models (student) to acquire knowledge from LLMs(teacher) while reducing computational costs. This process introduces challenges, such as potential noisy pseudo-labels. Selecting high-quality and informative data is therefore critical to enhance model performance while improving the efficiency of data utilization. To address this, we propose LLKD that enables Learning with Less computational resources and less data for Knowledge Distillation from LLMs. LLKD is an adaptive sample selection method that incorporates signals from both the teacher and student. Specifically, it prioritizes samples where the teacher demonstrates high confidence in its labeling, indicating reliable labels, and where the student exhibits a high information need, identifying challenging samples that require further learning. Our comprehensive experiments show that LLKD achieves superior performance across various datasets with higher data efficiency.
Exploring Query Understanding for Amazon Product Search
Aug 05, 2024



Online shopping platforms, such as Amazon, offer services to billions of people worldwide. Unlike web search or other search engines, product search engines have their unique characteristics, primarily featuring short queries which are mostly a combination of product attributes and structured product search space. The uniqueness of product search underscores the crucial importance of the query understanding component. However, there are limited studies focusing on exploring this impact within real-world product search engines. In this work, we aim to bridge this gap by conducting a comprehensive study and sharing our year-long journey investigating how the query understanding service impacts Amazon Product Search. Firstly, we explore how query understanding-based ranking features influence the ranking process. Next, we delve into how the query understanding system contributes to understanding the performance of a ranking model. Building on the insights gained from our study on the evaluation of the query understanding-based ranking model, we propose a query understanding-based multi-task learning framework for ranking. We present our studies and investigations using the real-world system on Amazon Search.
Exploring the Deceptive Power of LLM-Generated Fake News: A Study of Real-World Detection Challenges
Apr 08, 2024Recent advancements in Large Language Models (LLMs) have enabled the creation of fake news, particularly in complex fields like healthcare. Studies highlight the gap in the deceptive power of LLM-generated fake news with and without human assistance, yet the potential of prompting techniques has not been fully explored. Thus, this work aims to determine whether prompting strategies can effectively narrow this gap. Current LLM-based fake news attacks require human intervention for information gathering and often miss details and fail to maintain context consistency. Therefore, to better understand threat tactics, we propose a strong fake news attack method called conditional Variational-autoencoder-Like Prompt (VLPrompt). Unlike current methods, VLPrompt eliminates the need for additional data collection while maintaining contextual coherence and preserving the intricacies of the original text. To propel future research on detecting VLPrompt attacks, we created a new dataset named VLPrompt fake news (VLPFN) containing real and fake texts. Our experiments, including various detection methods and novel human study metrics, were conducted to assess their performance on our dataset, yielding numerous findings.
Hierarchical Query Classification in E-commerce Search
Mar 09, 2024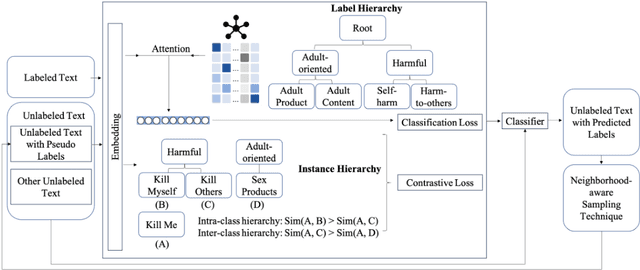

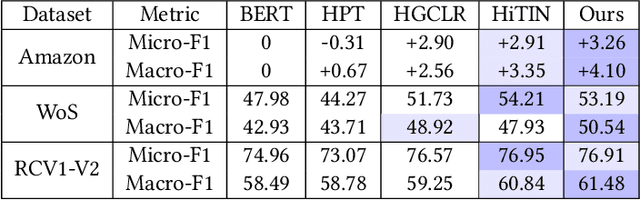
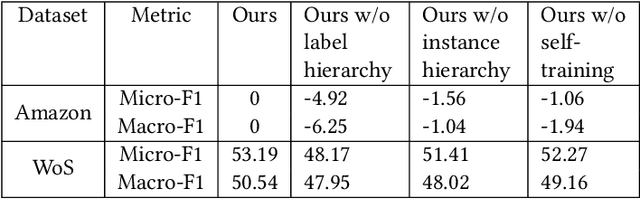
E-commerce platforms typically store and structure product information and search data in a hierarchy. Efficiently categorizing user search queries into a similar hierarchical structure is paramount in enhancing user experience on e-commerce platforms as well as news curation and academic research. The significance of this task is amplified when dealing with sensitive query categorization or critical information dissemination, where inaccuracies can lead to considerable negative impacts. The inherent complexity of hierarchical query classification is compounded by two primary challenges: (1) the pronounced class imbalance that skews towards dominant categories, and (2) the inherent brevity and ambiguity of search queries that hinder accurate classification. To address these challenges, we introduce a novel framework that leverages hierarchical information through (i) enhanced representation learning that utilizes the contrastive loss to discern fine-grained instance relationships within the hierarchy, called ''instance hierarchy'', and (ii) a nuanced hierarchical classification loss that attends to the intrinsic label taxonomy, named ''label hierarchy''. Additionally, based on our observation that certain unlabeled queries share typographical similarities with labeled queries, we propose a neighborhood-aware sampling technique to intelligently select these unlabeled queries to boost the classification performance. Extensive experiments demonstrate that our proposed method is better than state-of-the-art (SOTA) on the proprietary Amazon dataset, and comparable to SOTA on the public datasets of Web of Science and RCV1-V2. These results underscore the efficacy of our proposed solution, and pave the path toward the next generation of hierarchy-aware query classification systems.
A Unified Framework of Graph Information Bottleneck for Robustness and Membership Privacy
Jun 14, 2023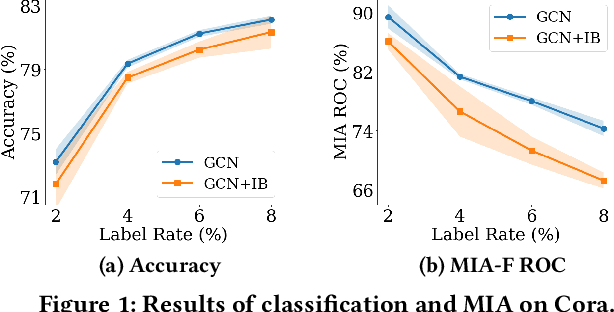
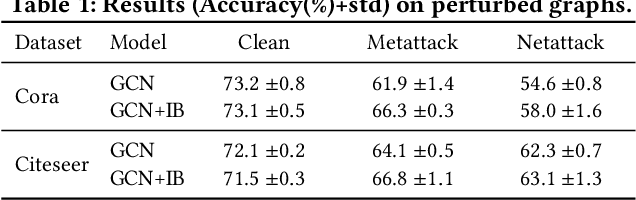
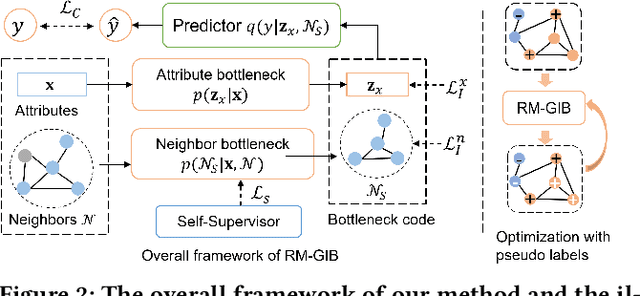
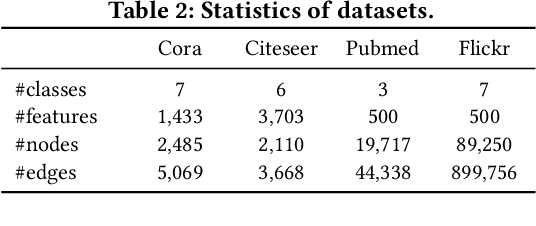
Graph Neural Networks (GNNs) have achieved great success in modeling graph-structured data. However, recent works show that GNNs are vulnerable to adversarial attacks which can fool the GNN model to make desired predictions of the attacker. In addition, training data of GNNs can be leaked under membership inference attacks. This largely hinders the adoption of GNNs in high-stake domains such as e-commerce, finance and bioinformatics. Though investigations have been made in conducting robust predictions and protecting membership privacy, they generally fail to simultaneously consider the robustness and membership privacy. Therefore, in this work, we study a novel problem of developing robust and membership privacy-preserving GNNs. Our analysis shows that Information Bottleneck (IB) can help filter out noisy information and regularize the predictions on labeled samples, which can benefit robustness and membership privacy. However, structural noises and lack of labels in node classification challenge the deployment of IB on graph-structured data. To mitigate these issues, we propose a novel graph information bottleneck framework that can alleviate structural noises with neighbor bottleneck. Pseudo labels are also incorporated in the optimization to minimize the gap between the predictions on the labeled set and unlabeled set for membership privacy. Extensive experiments on real-world datasets demonstrate that our method can give robust predictions and simultaneously preserve membership privacy.
Cross-lingual COVID-19 Fake News Detection
Oct 14, 2021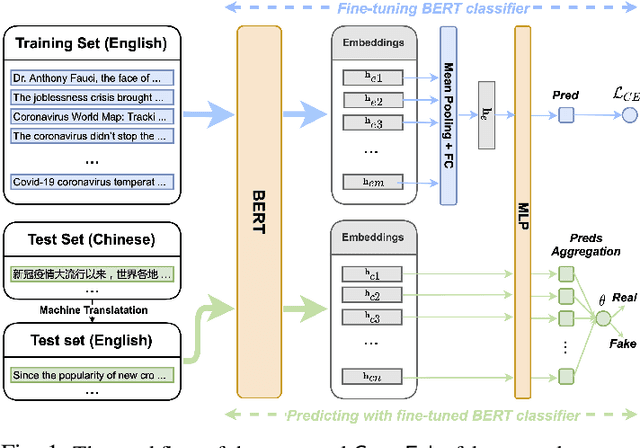

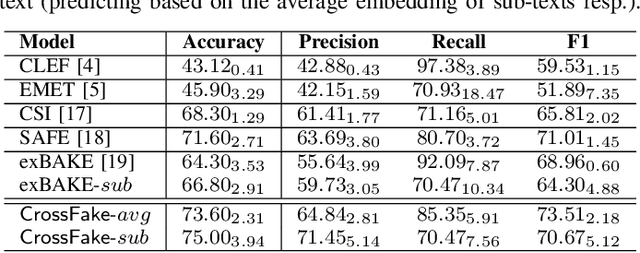
The COVID-19 pandemic poses a great threat to global public health. Meanwhile, there is massive misinformation associated with the pandemic which advocates unfounded or unscientific claims. Even major social media and news outlets have made an extra effort in debunking COVID-19 misinformation, most of the fact-checking information is in English, whereas some unmoderated COVID-19 misinformation is still circulating in other languages, threatening the health of less-informed people in immigrant communities and developing countries. In this paper, we make the first attempt to detect COVID-19 misinformation in a low-resource language (Chinese) only using the fact-checked news in a high-resource language (English). We start by curating a Chinese real&fake news dataset according to existing fact-checking information. Then, we propose a deep learning framework named CrossFake to jointly encode the cross-lingual news body texts and capture the news content as much as possible. Empirical results on our dataset demonstrate the effectiveness of CrossFake under the cross-lingual setting and it also outperforms several monolingual and cross-lingual fake news detectors. The dataset is available at https://github.com/YingtongDou/CrossFake.
CoAID: COVID-19 Healthcare Misinformation Dataset
May 22, 2020
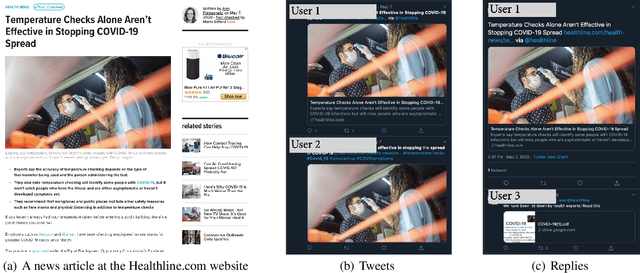
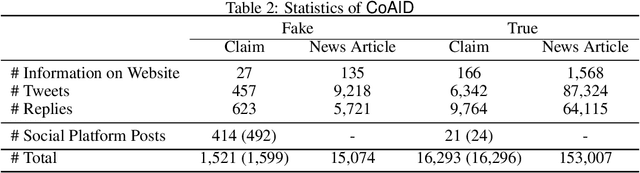
As the COVID-19 virus quickly spreads around the world, unfortunately, misinformation related to COVID-19 also gets created and spreads like wild fire. Such misinformation has caused confusion among people, disruptions in society, and even deadly consequences in health problems. To be able to understand, detect, and mitigate such COVID-19 misinformation, therefore, has not only deep intellectual values but also huge societal impacts. To help researchers combat COVID-19 health misinformation, therefore, we present CoAID (Covid-19 heAlthcare mIsinformation Dataset), with diverse COVID-19 healthcare misinformation, including fake news on websites and social platforms, along with users' social engagement about such news. CoAID includes 1,896 news, 183,564 related user engagements, 516 social platform posts about COVID-19, and ground truth labels. The dataset is available at: https://github.com/cuilimeng/CoAID.