 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving
Jan 29, 2026End-to-end autonomous driving increasingly leverages self-supervised video pretraining to learn transferable planning representations. However, pretraining video world models for scene understanding has so far brought only limited improvements. This limitation is compounded by the inherent ambiguity of driving: each scene typically provides only a single human trajectory, making it difficult to learn multimodal behaviors. In this work, we propose Drive-JEPA, a framework that integrates Video Joint-Embedding Predictive Architecture (V-JEPA) with multimodal trajectory distillation for end-to-end driving. First, we adapt V-JEPA for end-to-end driving, pretraining a ViT encoder on large-scale driving videos to produce predictive representations aligned with trajectory planning. Second, we introduce a proposal-centric planner that distills diverse simulator-generated trajectories alongside human trajectories, with a momentum-aware selection mechanism to promote stable and safe behavior. When evaluated on NAVSIM, the V-JEPA representation combined with a simple transformer-based decoder outperforms prior methods by 3 PDMS in the perception-free setting. The complete Drive-JEPA framework achieves 93.3 PDMS on v1 and 87.8 EPDMS on v2, setting a new state-of-the-art.
MVeLMA: Multimodal Vegetation Loss Modeling Architecture for Predicting Post-fire Vegetation Loss
Oct 31, 2025Understanding post-wildfire vegetation loss is critical for developing effective ecological recovery strategies and is often challenging due to the extended time and effort required to capture the evolving ecosystem features. Recent works in this area have not fully explored all the contributing factors, their modalities, and interactions with each other. Furthermore, most research in this domain is limited by a lack of interpretability in predictive modeling, making it less useful in real-world settings. In this work, we propose a novel end-to-end ML pipeline called MVeLMA (\textbf{M}ultimodal \textbf{Ve}getation \textbf{L}oss \textbf{M}odeling \textbf{A}rchitecture) to predict county-wise vegetation loss from fire events. MVeLMA uses a multimodal feature integration pipeline and a stacked ensemble-based architecture to capture different modalities while also incorporating uncertainty estimation through probabilistic modeling. Through comprehensive experiments, we show that our model outperforms several state-of-the-art (SOTA) and baseline models in predicting post-wildfire vegetation loss. Furthermore, we generate vegetation loss confidence maps to identify high-risk counties, thereby helping targeted recovery efforts. The findings of this work have the potential to inform future disaster relief planning, ecological policy development, and wildlife recovery management.
SemiETPicker: Fast and Label-Efficient Particle Picking for CryoET Tomography Using Semi-Supervised Learning
Oct 25, 2025Cryogenic Electron Tomography (CryoET) combined with sub-volume averaging (SVA) is the only imaging modality capable of resolving protein structures inside cells at molecular resolution. Particle picking, the task of localizing and classifying target proteins in 3D CryoET volumes, remains the main bottleneck. Due to the reliance on time-consuming manual labels, the vast reserve of unlabeled tomograms remains underutilized. In this work, we present a fast, label-efficient semi-supervised framework that exploits this untapped data. Our framework consists of two components: (i) an end-to-end heatmap-supervised detection model inspired by keypoint detection, and (ii) a teacher-student co-training mechanism that enhances performance under sparse labeling conditions. Furthermore, we introduce multi-view pseudo-labeling and a CryoET-specific DropBlock augmentation strategy to further boost performance. Extensive evaluations on the large-scale CZII dataset show that our approach improves F1 by 10% over supervised baselines, underscoring the promise of semi-supervised learning for leveraging unlabeled CryoET data.
Collaborative LLM Numerical Reasoning with Local Data Protection
Apr 01, 2025Numerical reasoning over documents, which demands both contextual understanding and logical inference, is challenging for low-capacity local models deployed on computation-constrained devices. Although such complex reasoning queries could be routed to powerful remote models like GPT-4, exposing local data raises significant data leakage concerns. Existing mitigation methods generate problem descriptions or examples for remote assistance. However, the inherent complexity of numerical reasoning hinders the local model from generating logically equivalent queries and accurately inferring answers with remote guidance. In this paper, we present a model collaboration framework with two key innovations: (1) a context-aware synthesis strategy that shifts the query domains while preserving logical consistency; and (2) a tool-based answer reconstruction approach that reuses the remote-generated problem-solving pattern with code snippets. Experimental results demonstrate that our method achieves better reasoning accuracy than solely using local models while providing stronger data protection than fully relying on remote models. Furthermore, our method improves accuracy by 16.2% - 43.6% while reducing data leakage by 2.3% - 44.6% compared to existing data protection approaches.
Optimizing Product Provenance Verification using Data Valuation Methods
Feb 21, 2025Determining and verifying product provenance remains a critical challenge in global supply chains, particularly as geopolitical conflicts and shifting borders create new incentives for misrepresentation of commodities, such as hiding the origin of illegally harvested timber or stolen agricultural products. Stable Isotope Ratio Analysis (SIRA), combined with Gaussian process regression-based isoscapes, has emerged as a powerful tool for geographic origin verification. However, the effectiveness of these models is often constrained by data scarcity and suboptimal dataset selection. In this work, we introduce a novel data valuation framework designed to enhance the selection and utilization of training data for machine learning models applied in SIRA. By prioritizing high-informative samples, our approach improves model robustness and predictive accuracy across diverse datasets and geographies. We validate our methodology with extensive experiments, demonstrating its potential to significantly enhance provenance verification, mitigate fraudulent trade practices, and strengthen regulatory enforcement of global supply chains.
Chasing the Timber Trail: Machine Learning to Reveal Harvest Location Misrepresentation
Feb 19, 2025


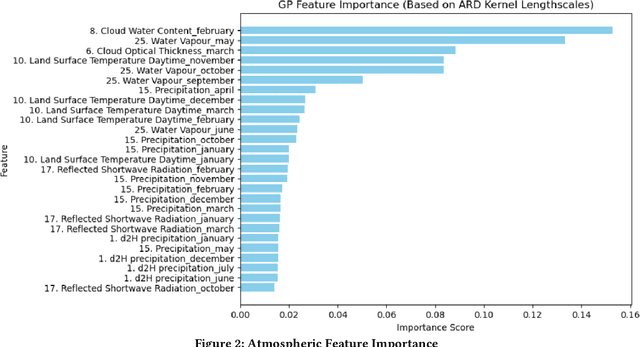
Illegal logging poses a significant threat to global biodiversity, climate stability, and depresses international prices for legal wood harvesting and responsible forest products trade, affecting livelihoods and communities across the globe. Stable isotope ratio analysis (SIRA) is rapidly becoming an important tool for determining the harvest location of traded, organic, products. The spatial pattern in stable isotope ratio values depends on factors such as atmospheric and environmental conditions and can thus be used for geographical identification. We present here the results of a deployed machine learning pipeline where we leverage both isotope values and atmospheric variables to determine timber harvest location. Additionally, the pipeline incorporates uncertainty estimation to facilitate the interpretation of harvest location determination for analysts. We present our experiments on a collection of oak (Quercus spp.) tree samples from its global range. Our pipeline outperforms comparable state-of-the-art models determining geographic harvest origin of commercially traded wood products, and has been used by European enforcement agencies to identify illicit Russian and Belarusian timber entering the EU market. We also identify opportunities for further advancement of our framework and how it can be generalized to help identify the origin of falsely labeled organic products throughout the supply chain.
Downscaling Precipitation with Bias-informed Conditional Diffusion Model
Dec 19, 2024

Climate change is intensifying rainfall extremes, making high-resolution precipitation projections crucial for society to better prepare for impacts such as flooding. However, current Global Climate Models (GCMs) operate at spatial resolutions too coarse for localized analyses. To address this limitation, deep learning-based statistical downscaling methods offer promising solutions, providing high-resolution precipitation projections with a moderate computational cost. In this work, we introduce a bias-informed conditional diffusion model for statistical downscaling of precipitation. Specifically, our model leverages a conditional diffusion approach to learn distribution priors from large-scale, high-resolution precipitation datasets. The long-tail distribution of precipitation poses a unique challenge for training diffusion models; to address this, we apply gamma correction during preprocessing. Additionally, to correct biases in the downscaled results, we employ a guided-sampling strategy to enhance bias correction. Our experiments demonstrate that the proposed model achieves highly accurate results in an 8 times downscaling setting, outperforming previous deterministic methods. The code and dataset are available at https://github.com/RoseLV/research_super-resolution
Exposing LLM Vulnerabilities: Adversarial Scam Detection and Performance
Dec 01, 2024



Can we trust Large Language Models (LLMs) to accurately predict scam? This paper investigates the vulnerabilities of LLMs when facing adversarial scam messages for the task of scam detection. We addressed this issue by creating a comprehensive dataset with fine-grained labels of scam messages, including both original and adversarial scam messages. The dataset extended traditional binary classes for the scam detection task into more nuanced scam types. Our analysis showed how adversarial examples took advantage of vulnerabilities of a LLM, leading to high misclassification rate. We evaluated the performance of LLMs on these adversarial scam messages and proposed strategies to improve their robustness.
Rethinking the Uncertainty: A Critical Review and Analysis in the Era of Large Language Models
Oct 26, 2024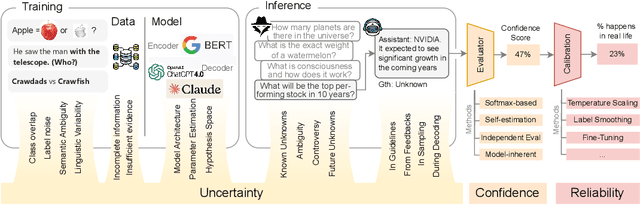
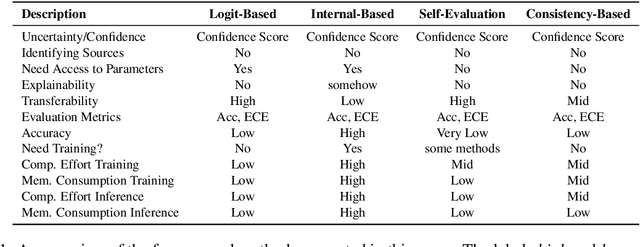
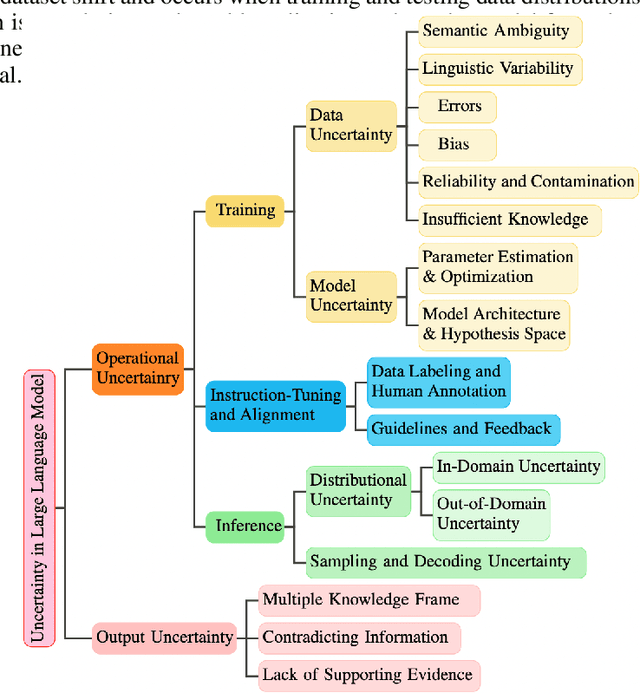
In recent years, Large Language Models (LLMs) have become fundamental to a broad spectrum of artificial intelligence applications. As the use of LLMs expands, precisely estimating the uncertainty in their predictions has become crucial. Current methods often struggle to accurately identify, measure, and address the true uncertainty, with many focusing primarily on estimating model confidence. This discrepancy is largely due to an incomplete understanding of where, when, and how uncertainties are injected into models. This paper introduces a comprehensive framework specifically designed to identify and understand the types and sources of uncertainty, aligned with the unique characteristics of LLMs. Our framework enhances the understanding of the diverse landscape of uncertainties by systematically categorizing and defining each type, establishing a solid foundation for developing targeted methods that can precisely quantify these uncertainties. We also provide a detailed introduction to key related concepts and examine the limitations of current methods in mission-critical and safety-sensitive applications. The paper concludes with a perspective on future directions aimed at enhancing the reliability and practical adoption of these methods in real-world scenarios.
Can We Trust the Performance Evaluation of Uncertainty Estimation Methods in Text Summarization?
Jun 25, 2024Text summarization, a key natural language generation (NLG) task, is vital in various domains. However, the high cost of inaccurate summaries in risk-critical applications, particularly those involving human-in-the-loop decision-making, raises concerns about the reliability of uncertainty estimation on text summarization (UE-TS) evaluation methods. This concern stems from the dependency of uncertainty model metrics on diverse and potentially conflicting NLG metrics. To address this issue, we introduce a comprehensive UE-TS benchmark incorporating 31 NLG metrics across four dimensions. The benchmark evaluates the uncertainty estimation capabilities of two large language models and one pre-trained language model on three datasets, with human-annotation analysis incorporated where applicable. We also assess the performance of 14 common uncertainty estimation methods within this benchmark. Our findings emphasize the importance of considering multiple uncorrelated NLG metrics and diverse uncertainty estimation methods to ensure reliable and efficient evaluation of UE-TS techniques.