 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Metadata for Better Retrieval-Augmented Generation
Jan 17, 2026Retrieval-Augmented Generation systems depend on retrieving semantically relevant document chunks to support accurate, grounded outputs from large language models. In structured and repetitive corpora such as regulatory filings, chunk similarity alone often fails to distinguish between documents with overlapping language. Practitioners often flatten metadata into input text as a heuristic, but the impact and trade-offs of this practice remain poorly understood. We present a systematic study of metadata-aware retrieval strategies, comparing plain-text baselines with approaches that embed metadata directly. Our evaluation spans metadata-as-text (prefix and suffix), a dual-encoder unified embedding that fuses metadata and content in a single index, dual-encoder late-fusion retrieval, and metadata-aware query reformulation. Across multiple retrieval metrics and question types, we find that prefixing and unified embeddings consistently outperform plain-text baselines, with the unified at times exceeding prefixing while being easier to maintain. Beyond empirical comparisons, we analyze embedding space, showing that metadata integration improves effectiveness by increasing intra-document cohesion, reducing inter-document confusion, and widening the separation between relevant and irrelevant chunks. Field-level ablations show that structural cues provide strong disambiguating signals. Our code, evaluation framework, and the RAGMATE-10K dataset are publicly hosted.
Optimizing Product Provenance Verification using Data Valuation Methods
Feb 21, 2025Determining and verifying product provenance remains a critical challenge in global supply chains, particularly as geopolitical conflicts and shifting borders create new incentives for misrepresentation of commodities, such as hiding the origin of illegally harvested timber or stolen agricultural products. Stable Isotope Ratio Analysis (SIRA), combined with Gaussian process regression-based isoscapes, has emerged as a powerful tool for geographic origin verification. However, the effectiveness of these models is often constrained by data scarcity and suboptimal dataset selection. In this work, we introduce a novel data valuation framework designed to enhance the selection and utilization of training data for machine learning models applied in SIRA. By prioritizing high-informative samples, our approach improves model robustness and predictive accuracy across diverse datasets and geographies. We validate our methodology with extensive experiments, demonstrating its potential to significantly enhance provenance verification, mitigate fraudulent trade practices, and strengthen regulatory enforcement of global supply chains.
Chasing the Timber Trail: Machine Learning to Reveal Harvest Location Misrepresentation
Feb 19, 2025


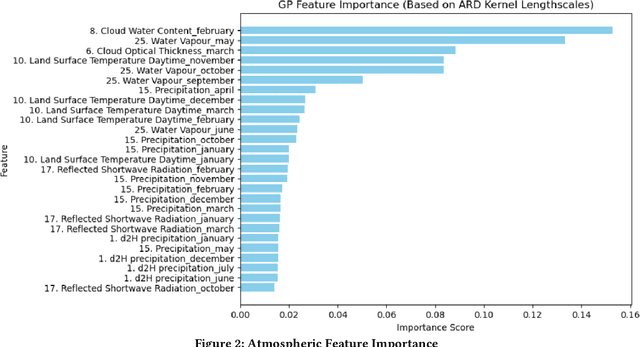
Illegal logging poses a significant threat to global biodiversity, climate stability, and depresses international prices for legal wood harvesting and responsible forest products trade, affecting livelihoods and communities across the globe. Stable isotope ratio analysis (SIRA) is rapidly becoming an important tool for determining the harvest location of traded, organic, products. The spatial pattern in stable isotope ratio values depends on factors such as atmospheric and environmental conditions and can thus be used for geographical identification. We present here the results of a deployed machine learning pipeline where we leverage both isotope values and atmospheric variables to determine timber harvest location. Additionally, the pipeline incorporates uncertainty estimation to facilitate the interpretation of harvest location determination for analysts. We present our experiments on a collection of oak (Quercus spp.) tree samples from its global range. Our pipeline outperforms comparable state-of-the-art models determining geographic harvest origin of commercially traded wood products, and has been used by European enforcement agencies to identify illicit Russian and Belarusian timber entering the EU market. We also identify opportunities for further advancement of our framework and how it can be generalized to help identify the origin of falsely labeled organic products throughout the supply chain.
LLM Augmentations to support Analytical Reasoning over Multiple Documents
Nov 25, 2024
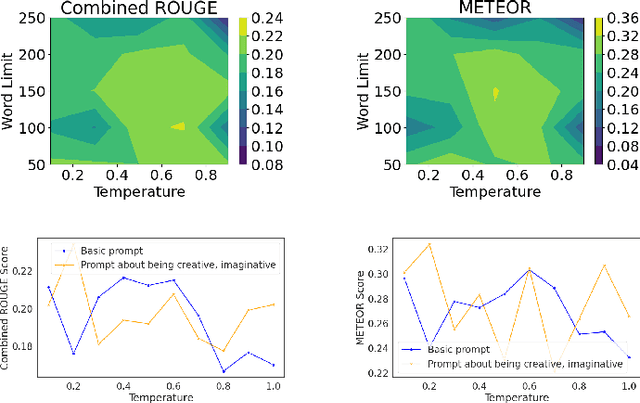
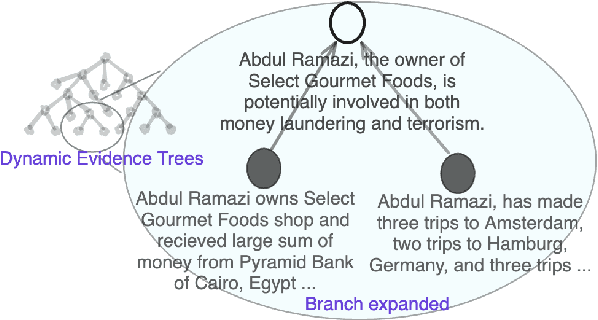

Building on their demonstrated ability to perform a variety of tasks, we investigate the application of large language models (LLMs) to enhance in-depth analytical reasoning within the context of intelligence analysis. Intelligence analysts typically work with massive dossiers to draw connections between seemingly unrelated entities, and uncover adversaries' plans and motives. We explore if and how LLMs can be helpful to analysts for this task and develop an architecture to augment the capabilities of an LLM with a memory module called dynamic evidence trees (DETs) to develop and track multiple investigation threads. Through extensive experiments on multiple datasets, we highlight how LLMs, as-is, are still inadequate to support intelligence analysts and offer recommendations to improve LLMs for such intricate reasoning applications.
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Jun 20, 2024



Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
Lessons from Deep Learning applied to Scholarly Information Extraction: What Works, What Doesn't, and Future Directions
Jul 08, 2022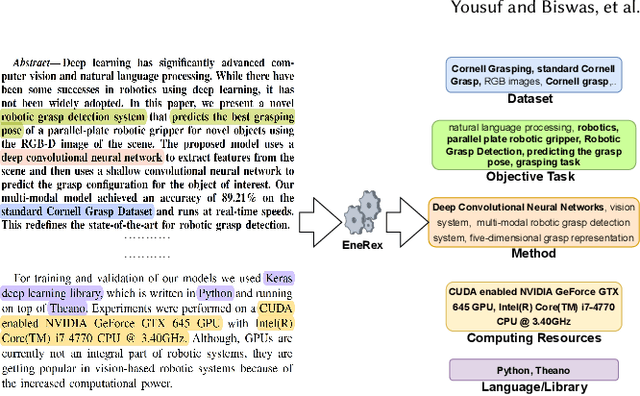

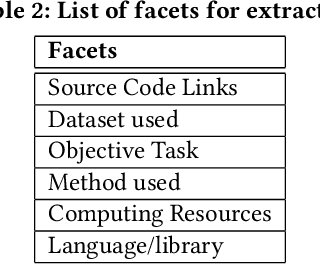
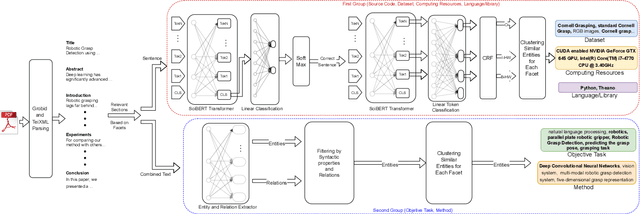
Understanding key insights from full-text scholarly articles is essential as it enables us to determine interesting trends, give insight into the research and development, and build knowledge graphs. However, some of the interesting key insights are only available when considering full-text. Although researchers have made significant progress in information extraction from short documents, extraction of scientific entities from full-text scholarly literature remains a challenging problem. This work presents an automated End-to-end Research Entity Extractor called EneRex to extract technical facets such as dataset usage, objective task, method from full-text scholarly research articles. Additionally, we extracted three novel facets, e.g., links to source code, computing resources, programming language/libraries from full-text articles. We demonstrate how EneRex is able to extract key insights and trends from a large-scale dataset in the domain of computer science. We further test our pipeline on multiple datasets and found that the EneRex improves upon a state of the art model. We highlight how the existing datasets are limited in their capacity and how EneRex may fit into an existing knowledge graph. We also present a detailed discussion with pointers for future research. Our code and data are publicly available at https://github.com/DiscoveryAnalyticsCenter/EneRex.