 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuraLight: Debate-Guided Data Curation for LLM-Centered Traffic Signal Control
Apr 07, 2026Traffic signal control (TSC) is a core component of intelligent transportation systems (ITS), aiming to reduce congestion, emissions, and travel time. Recent approaches based on reinforcement learning (RL) and large language models (LLMs) have improved adaptivity, but still suffer from limited interpretability, insufficient interaction data, and weak generalization to heterogeneous intersections. This paper proposes CuraLight, an LLM-centered framework where an RL agent assists the fine-tuning of an LLM-based traffic signal controller. The RL agent explores traffic environments and generates high-quality interaction trajectories, which are converted into prompt-response pairs for imitation fine-tuning. A multi-LLM ensemble deliberation system further evaluates candidate signal timing actions through structured debate, providing preference-aware supervision signals for training. Experiments conducted in SUMO across heterogeneous real-world networks from Jinan, Hangzhou, and Yizhuang demonstrate that CuraLight consistently outperforms state-of-the-art baselines, reducing average travel time by 5.34 percent, average queue length by 5.14 percent, and average waiting time by 7.02 percent. The results highlight the effectiveness of combining RL-assisted exploration with deliberation-based data curation for scalable and interpretable traffic signal control.
Utilizing Metadata for Better Retrieval-Augmented Generation
Jan 17, 2026Retrieval-Augmented Generation systems depend on retrieving semantically relevant document chunks to support accurate, grounded outputs from large language models. In structured and repetitive corpora such as regulatory filings, chunk similarity alone often fails to distinguish between documents with overlapping language. Practitioners often flatten metadata into input text as a heuristic, but the impact and trade-offs of this practice remain poorly understood. We present a systematic study of metadata-aware retrieval strategies, comparing plain-text baselines with approaches that embed metadata directly. Our evaluation spans metadata-as-text (prefix and suffix), a dual-encoder unified embedding that fuses metadata and content in a single index, dual-encoder late-fusion retrieval, and metadata-aware query reformulation. Across multiple retrieval metrics and question types, we find that prefixing and unified embeddings consistently outperform plain-text baselines, with the unified at times exceeding prefixing while being easier to maintain. Beyond empirical comparisons, we analyze embedding space, showing that metadata integration improves effectiveness by increasing intra-document cohesion, reducing inter-document confusion, and widening the separation between relevant and irrelevant chunks. Field-level ablations show that structural cues provide strong disambiguating signals. Our code, evaluation framework, and the RAGMATE-10K dataset are publicly hosted.
Retrieval Augmented Generation-Enhanced Distributed LLM Agents for Generalizable Traffic Signal Control with Emergency Vehicles
Oct 30, 2025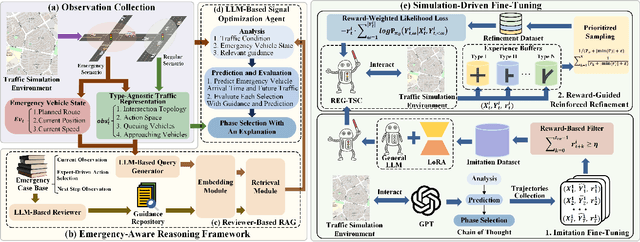
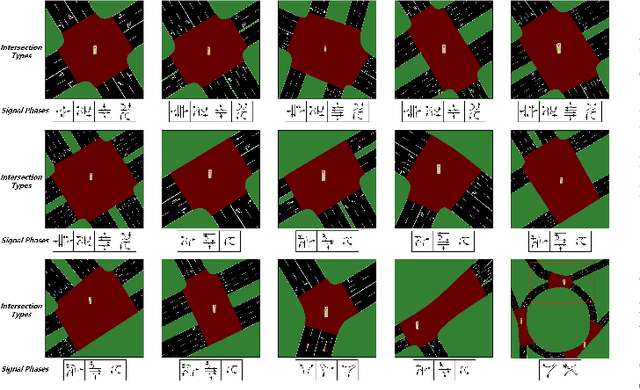
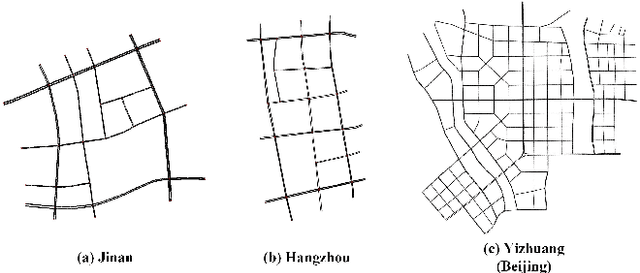
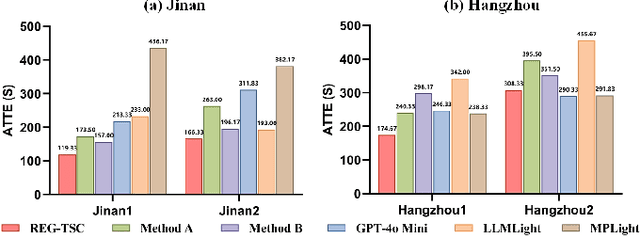
With increasing urban traffic complexity, Traffic Signal Control (TSC) is essential for optimizing traffic flow and improving road safety. Large Language Models (LLMs) emerge as promising approaches for TSC. However, they are prone to hallucinations in emergencies, leading to unreliable decisions that may cause substantial delays for emergency vehicles. Moreover, diverse intersection types present substantial challenges for traffic state encoding and cross-intersection training, limiting generalization across heterogeneous intersections. Therefore, this paper proposes Retrieval Augmented Generation (RAG)-enhanced distributed LLM agents with Emergency response for Generalizable TSC (REG-TSC). Firstly, this paper presents an emergency-aware reasoning framework, which dynamically adjusts reasoning depth based on the emergency scenario and is equipped with a novel Reviewer-based Emergency RAG (RERAG) to distill specific knowledge and guidance from historical cases, enhancing the reliability and rationality of agents' emergency decisions. Secondly, this paper designs a type-agnostic traffic representation and proposes a Reward-guided Reinforced Refinement (R3) for heterogeneous intersections. R3 adaptively samples training experience from diverse intersections with environment feedback-based priority and fine-tunes LLM agents with a designed reward-weighted likelihood loss, guiding REG-TSC toward high-reward policies across heterogeneous intersections. On three real-world road networks with 17 to 177 heterogeneous intersections, extensive experiments show that REG-TSC reduces travel time by 42.00%, queue length by 62.31%, and emergency vehicle waiting time by 83.16%, outperforming other state-of-the-art methods.
When can isotropy help adapt LLMs' next word prediction to numerical domains?
May 26, 2025Recent studies have shown that vector representations of contextual embeddings learned by pre-trained large language models (LLMs) are effective in various downstream tasks in numerical domains. Despite their significant benefits, the tendency of LLMs to hallucinate in such domains can have severe consequences in applications such as energy, nature, finance, healthcare, retail and transportation, among others. To guarantee prediction reliability and accuracy in numerical domains, it is necessary to open the black-box and provide performance guarantees through explanation. However, there is little theoretical understanding of when pre-trained language models help solve numeric downstream tasks. This paper seeks to bridge this gap by understanding when the next-word prediction capability of LLMs can be adapted to numerical domains through a novel analysis based on the concept of isotropy in the contextual embedding space. Specifically, we consider a log-linear model for LLMs in which numeric data can be predicted from its context through a network with softmax in the output layer of LLMs (i.e., language model head in self-attention). We demonstrate that, in order to achieve state-of-the-art performance in numerical domains, the hidden representations of the LLM embeddings must possess a structure that accounts for the shift-invariance of the softmax function. By formulating a gradient structure of self-attention in pre-trained models, we show how the isotropic property of LLM embeddings in contextual embedding space preserves the underlying structure of representations, thereby resolving the shift-invariance problem and providing a performance guarantee. Experiments show that different characteristics of numeric data and model architecture could have different impacts on isotropy.
The Prompt is Mightier than the Example
May 24, 2025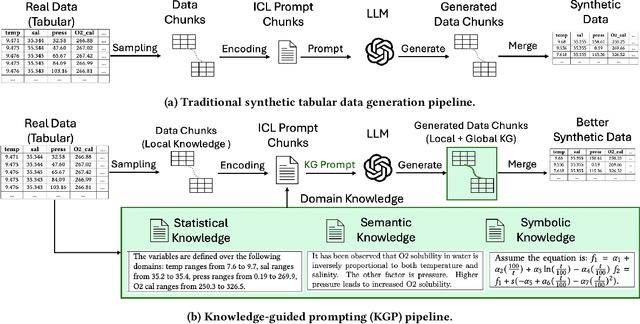
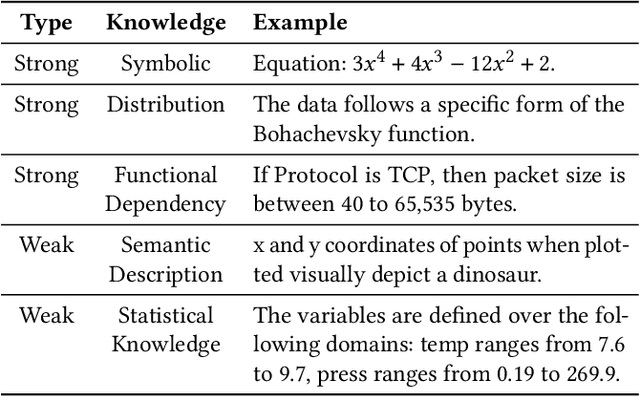
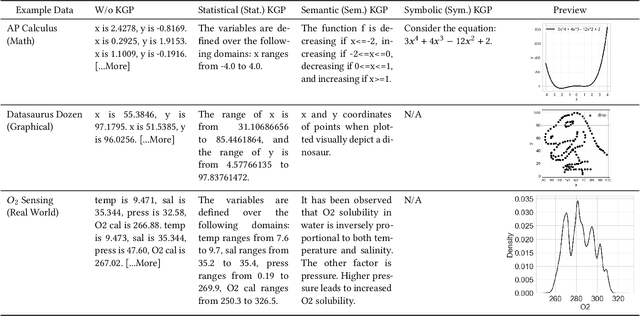
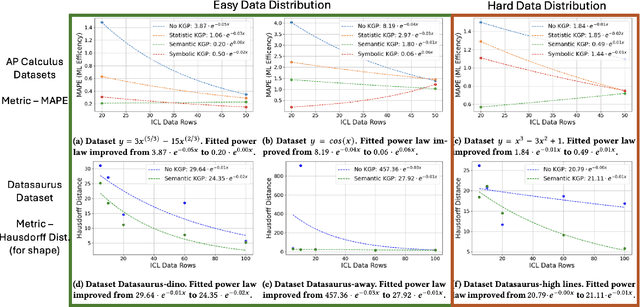
Numerous recent prompt optimization approaches like chain-of-thought, have been demonstrated to significantly improve the quality of content generated by large language models (LLMs). In-context learning (ICL), a recent paradigm where a few representative examples guide content generation has also led to strong improvements in generation quality of LLM generated content. This idea has been applied to great effect in synthetic tabular data generation, where LLMs, through effective use of ICL and prompt optimization, can generate data that approximate samples from complex, heterogeneous distributions based on representative examples. However, ensuring high-fidelity synthetic data often requires a very large number of ICL examples which may be unavailable or costly to obtain. At the same time, as LLMs get larger and larger, their in-built prior knowledge becomes vast and can potentially substitute for specific data examples. In this paper, we introduce Knowledge-Guided Prompting (KGP) as a new knob in prompt optimization and explore the ability of KGP-based prompt optimization to offset the cost of ICL. Specifically, we explore the question `how many examples can a prompt substitute for?' and explore knowledge-guided prompting (KGP) where domain knowledge, either inferred or available, is explicitly injected into the prompt, reducing dependence on ICL examples. Our experiments systematically explore the trade-off between ICL and KGP, revealing an empirical scaling law that quantifies how quality of generated synthetic data varies with increasing domain knowledge and decreasing example count. Our results demonstrate that knowledge-guided prompting can be a scalable alternative, or addition, to in-context examples, unlocking new approaches to synthetic data generation.
Optimizing Product Provenance Verification using Data Valuation Methods
Feb 21, 2025Determining and verifying product provenance remains a critical challenge in global supply chains, particularly as geopolitical conflicts and shifting borders create new incentives for misrepresentation of commodities, such as hiding the origin of illegally harvested timber or stolen agricultural products. Stable Isotope Ratio Analysis (SIRA), combined with Gaussian process regression-based isoscapes, has emerged as a powerful tool for geographic origin verification. However, the effectiveness of these models is often constrained by data scarcity and suboptimal dataset selection. In this work, we introduce a novel data valuation framework designed to enhance the selection and utilization of training data for machine learning models applied in SIRA. By prioritizing high-informative samples, our approach improves model robustness and predictive accuracy across diverse datasets and geographies. We validate our methodology with extensive experiments, demonstrating its potential to significantly enhance provenance verification, mitigate fraudulent trade practices, and strengthen regulatory enforcement of global supply chains.
LLM Augmentations to support Analytical Reasoning over Multiple Documents
Nov 25, 2024
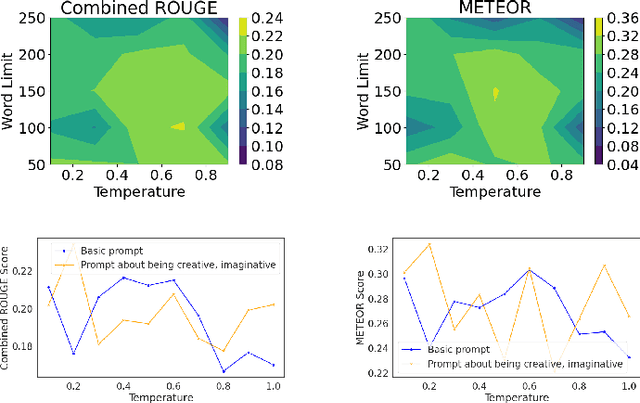
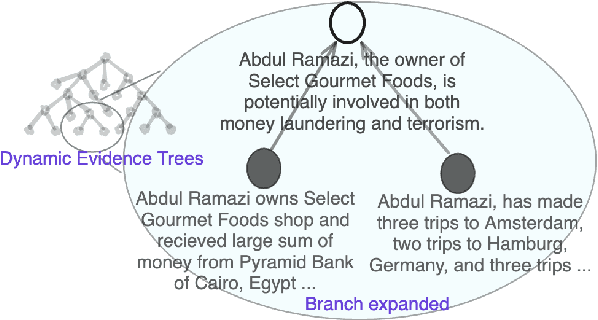

Building on their demonstrated ability to perform a variety of tasks, we investigate the application of large language models (LLMs) to enhance in-depth analytical reasoning within the context of intelligence analysis. Intelligence analysts typically work with massive dossiers to draw connections between seemingly unrelated entities, and uncover adversaries' plans and motives. We explore if and how LLMs can be helpful to analysts for this task and develop an architecture to augment the capabilities of an LLM with a memory module called dynamic evidence trees (DETs) to develop and track multiple investigation threads. Through extensive experiments on multiple datasets, we highlight how LLMs, as-is, are still inadequate to support intelligence analysts and offer recommendations to improve LLMs for such intricate reasoning applications.
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Jun 20, 2024



Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
Information Guided Regularization for Fine-tuning Language Models
Jun 20, 2024



The pretraining-fine-tuning paradigm has been the de facto strategy for transfer learning in modern language modeling. With the understanding that task adaptation in LMs is often a function of parameters shared across tasks, we argue that a more surgical approach to regularization needs to exist for smoother transfer learning. Towards this end, we investigate how the pretraining loss landscape is affected by these task-sensitive parameters through an information-theoretic lens. We then leverage the findings from our investigations to devise a novel approach to dropout for improved model regularization and better downstream generalization. This approach, named guided dropout, is both task & architecture agnostic and adds no computational overhead to the fine-tuning process. Through empirical evaluations, we showcase that our approach to regularization yields consistently better performance, even in scenarios of data paucity, compared to standardized baselines.
Large Multi-Modal Models (LMMs) as Universal Foundation Models for AI-Native Wireless Systems
Feb 07, 2024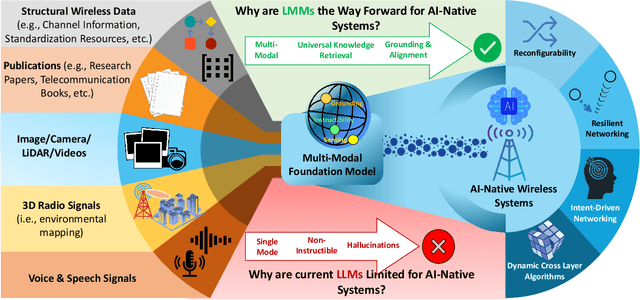
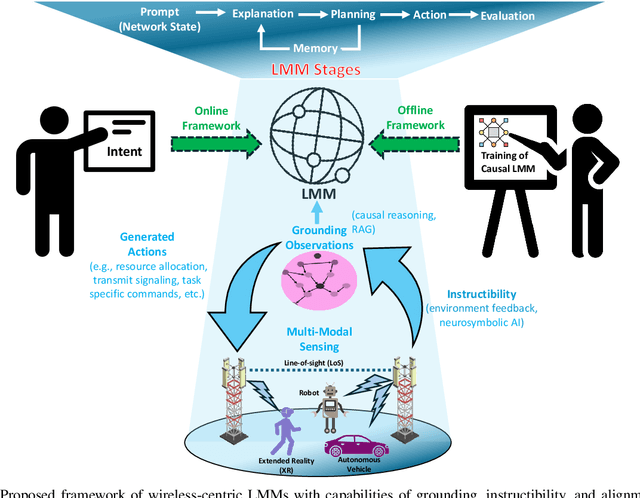
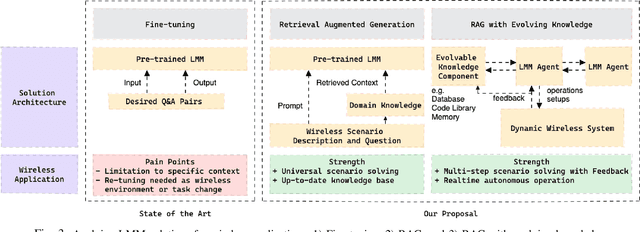
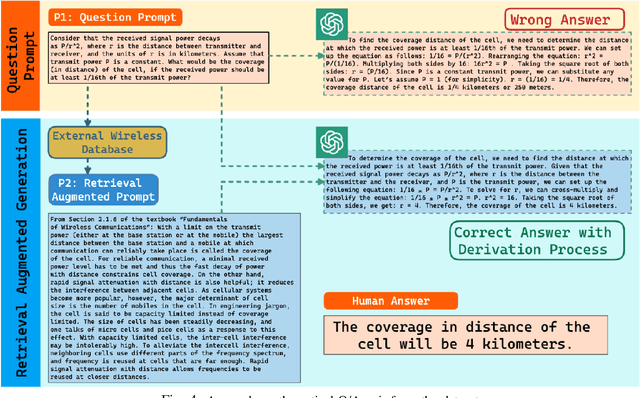
Large language models (LLMs) and foundation models have been recently touted as a game-changer for 6G systems. However, recent efforts on LLMs for wireless networks are limited to a direct application of existing language models that were designed for natural language processing (NLP) applications. To address this challenge and create wireless-centric foundation models, this paper presents a comprehensive vision on how to design universal foundation models that are tailored towards the deployment of artificial intelligence (AI)-native networks. Diverging from NLP-based foundation models, the proposed framework promotes the design of large multi-modal models (LMMs) fostered by three key capabilities: 1) processing of multi-modal sensing data, 2) grounding of physical symbol representations in real-world wireless systems using causal reasoning and retrieval-augmented generation (RAG), and 3) enabling instructibility from the wireless environment feedback to facilitate dynamic network adaptation thanks to logical and mathematical reasoning facilitated by neuro-symbolic AI. In essence, these properties enable the proposed LMM framework to build universal capabilities that cater to various cross-layer networking tasks and alignment of intents across different domains. Preliminary results from experimental evaluation demonstrate the efficacy of grounding using RAG in LMMs, and showcase the alignment of LMMs with wireless system designs. Furthermore, the enhanced rationale exhibited in the responses to mathematical questions by LMMs, compared to vanilla LLMs, demonstrates the logical and mathematical reasoning capabilities inherent in LMMs. Building on those results, we present a sequel of open questions and challenges for LMMs. We then conclude with a set of recommendations that ignite the path towards LMM-empowered AI-native systems.