 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Masked Autoencoders: Unlocking Vision Transformer Potential with Limited Data
Jan 27, 2026We address the challenge of training Vision Transformers (ViTs) when labeled data is scarce but unlabeled data is abundant. We propose Semi-Supervised Masked Autoencoder (SSMAE), a framework that jointly optimizes masked image reconstruction and classification using both unlabeled and labeled samples with dynamically selected pseudo-labels. SSMAE introduces a validation-driven gating mechanism that activates pseudo-labeling only after the model achieves reliable, high-confidence predictions that are consistent across both weakly and strongly augmented views of the same image, reducing confirmation bias. On CIFAR-10 and CIFAR-100, SSMAE consistently outperforms supervised ViT and fine-tuned MAE, with the largest gains in low-label regimes (+9.24% over ViT on CIFAR-10 with 10% labels). Our results demonstrate that when pseudo-labels are introduced is as important as how they are generated for data-efficient transformer training. Codes are available at https://github.com/atik666/ssmae.
Finetune-Informed Pretraining Boosts Downstream Performance
Jan 27, 2026Multimodal pretraining is effective for building general-purpose representations, but in many practical deployments, only one modality is heavily used during downstream fine-tuning. Standard pretraining strategies treat all modalities uniformly, which can lead to under-optimized representations for the modality that actually matters. We propose Finetune-Informed Pretraining (FIP), a model-agnostic method that biases representation learning toward a designated target modality needed at fine-tuning time. FIP combines higher masking difficulty, stronger loss weighting, and increased decoder capacity for the target modality, without modifying the shared encoder or requiring additional supervision. When applied to masked modeling on constellation diagrams for wireless signals, FIP consistently improves downstream fine-tuned performance with no extra data or compute. FIP is simple to implement, architecture-compatible, and broadly applicable across multimodal masked modeling pipelines.
Can AI Validate Science? Benchmarking LLMs for Accurate Scientific Claim $\rightarrow$ Evidence Reasoning
Jun 09, 2025Large language models (LLMs) are increasingly being used for complex research tasks such as literature review, idea generation, and scientific paper analysis, yet their ability to truly understand and process the intricate relationships within complex research papers, such as the logical links between claims and supporting evidence remains largely unexplored. In this study, we present CLAIM-BENCH, a comprehensive benchmark for evaluating LLMs' capabilities in scientific claim-evidence extraction and validation, a task that reflects deeper comprehension of scientific argumentation. We systematically compare three approaches which are inspired by divide and conquer approaches, across six diverse LLMs, highlighting model-specific strengths and weaknesses in scientific comprehension. Through evaluation involving over 300 claim-evidence pairs across multiple research domains, we reveal significant limitations in LLMs' ability to process complex scientific content. Our results demonstrate that closed-source models like GPT-4 and Claude consistently outperform open-source counterparts in precision and recall across claim-evidence identification tasks. Furthermore, strategically designed three-pass and one-by-one prompting approaches significantly improve LLMs' abilities to accurately link dispersed evidence with claims, although this comes at increased computational cost. CLAIM-BENCH sets a new standard for evaluating scientific comprehension in LLMs, offering both a diagnostic tool and a path forward for building systems capable of deeper, more reliable reasoning across full-length papers.
The Prompt is Mightier than the Example
May 24, 2025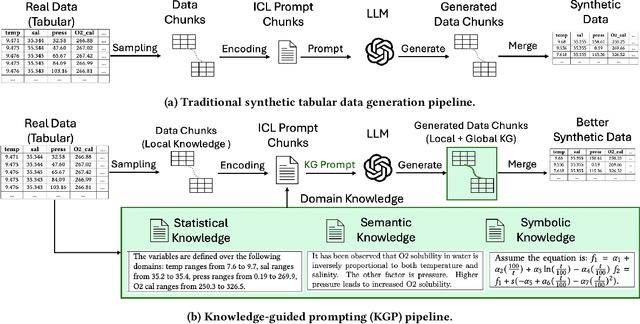
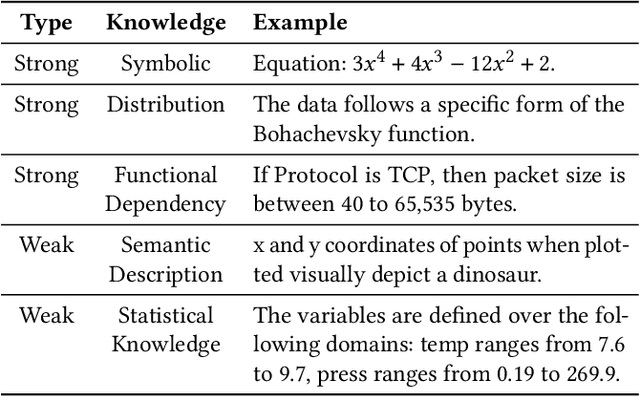
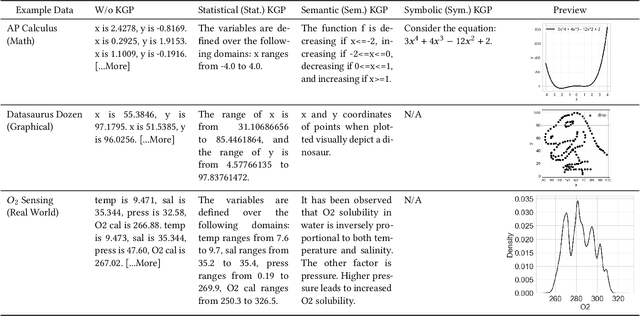
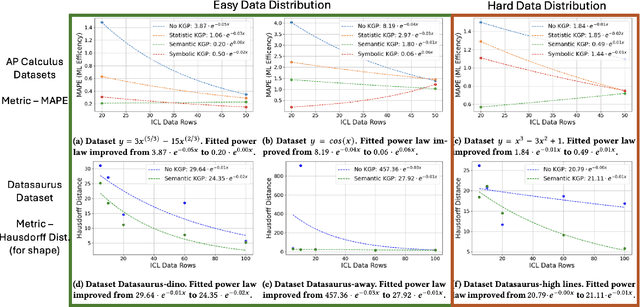
Numerous recent prompt optimization approaches like chain-of-thought, have been demonstrated to significantly improve the quality of content generated by large language models (LLMs). In-context learning (ICL), a recent paradigm where a few representative examples guide content generation has also led to strong improvements in generation quality of LLM generated content. This idea has been applied to great effect in synthetic tabular data generation, where LLMs, through effective use of ICL and prompt optimization, can generate data that approximate samples from complex, heterogeneous distributions based on representative examples. However, ensuring high-fidelity synthetic data often requires a very large number of ICL examples which may be unavailable or costly to obtain. At the same time, as LLMs get larger and larger, their in-built prior knowledge becomes vast and can potentially substitute for specific data examples. In this paper, we introduce Knowledge-Guided Prompting (KGP) as a new knob in prompt optimization and explore the ability of KGP-based prompt optimization to offset the cost of ICL. Specifically, we explore the question `how many examples can a prompt substitute for?' and explore knowledge-guided prompting (KGP) where domain knowledge, either inferred or available, is explicitly injected into the prompt, reducing dependence on ICL examples. Our experiments systematically explore the trade-off between ICL and KGP, revealing an empirical scaling law that quantifies how quality of generated synthetic data varies with increasing domain knowledge and decreasing example count. Our results demonstrate that knowledge-guided prompting can be a scalable alternative, or addition, to in-context examples, unlocking new approaches to synthetic data generation.
Plug-and-Play AMC: Context Is King in Training-Free, Open-Set Modulation with LLMs
May 06, 2025Automatic Modulation Classification (AMC) is critical for efficient spectrum management and robust wireless communications. However, AMC remains challenging due to the complex interplay of signal interference and noise. In this work, we propose an innovative framework that integrates traditional signal processing techniques with Large-Language Models (LLMs) to address AMC. Our approach leverages higher-order statistics and cumulant estimation to convert quantitative signal features into structured natural language prompts. By incorporating exemplar contexts into these prompts, our method exploits the LLM's inherent familiarity with classical signal processing, enabling effective one-shot classification without additional training or preprocessing (e.g., denoising). Experimental evaluations on synthetically generated datasets, spanning both noiseless and noisy conditions, demonstrate that our framework achieves competitive performance across diverse modulation schemes and Signal-to-Noise Ratios (SNRs). Moreover, our approach paves the way for robust foundation models in wireless communications across varying channel conditions, significantly reducing the expense associated with developing channel-specific models. This work lays the foundation for scalable, interpretable, and versatile signal classification systems in next-generation wireless networks. The source code is available at https://github.com/RU-SIT/context-is-king
Model-Agnostic Knowledge Guided Correction for Improved Neural Surrogate Rollout
Mar 13, 2025Modeling the evolution of physical systems is critical to many applications in science and engineering. As the evolution of these systems is governed by partial differential equations (PDEs), there are a number of computational simulations which resolve these systems with high accuracy. However, as these simulations incur high computational costs, they are infeasible to be employed for large-scale analysis. A popular alternative to simulators are neural network surrogates which are trained in a data-driven manner and are much more computationally efficient. However, these surrogate models suffer from high rollout error when used autoregressively, especially when confronted with training data paucity. Existing work proposes to improve surrogate rollout error by either including physical loss terms directly in the optimization of the model or incorporating computational simulators as `differentiable layers' in the neural network. Both of these approaches have their challenges, with physical loss functions suffering from slow convergence for stiff PDEs and simulator layers requiring gradients which are not always available, especially in legacy simulators. We propose the Hybrid PDE Predictor with Reinforcement Learning (HyPER) model: a model-agnostic, RL based, cost-aware model which combines a neural surrogate, RL decision model, and a physics simulator (with or without gradients) to reduce surrogate rollout error significantly. In addition to reducing in-distribution rollout error by **47%-78%**, HyPER learns an intelligent policy that is adaptable to changing physical conditions and resistant to noise corruption. Code available at https://github.com/scailab/HyPER.
DenoMAE2.0: Improving Denoising Masked Autoencoders by Classifying Local Patches
Feb 25, 2025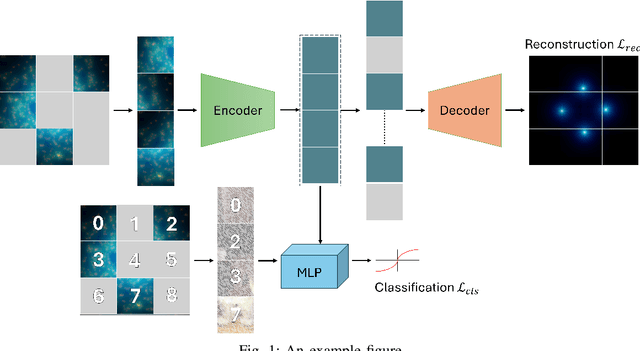
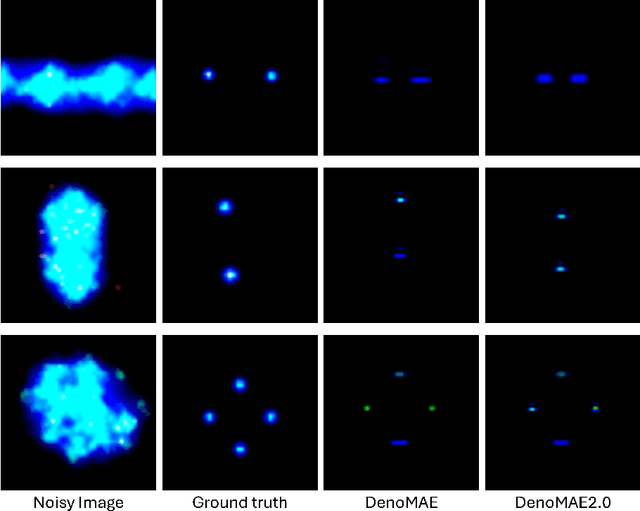
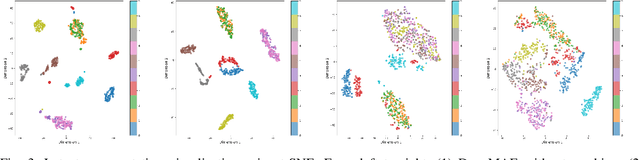
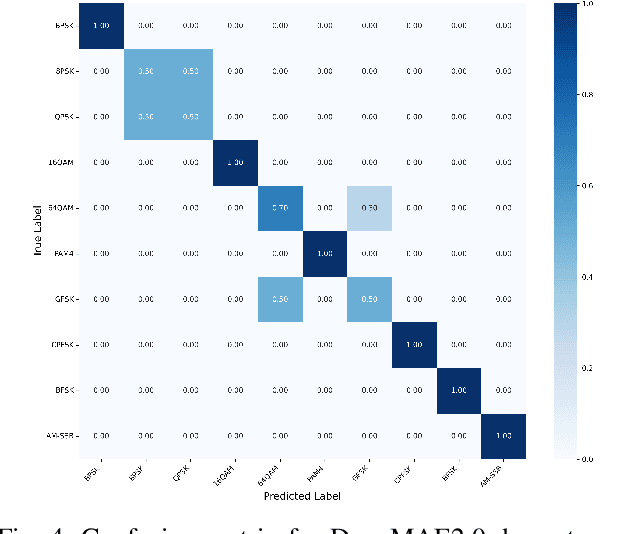
We introduce DenoMAE2.0, an enhanced denoising masked autoencoder that integrates a local patch classification objective alongside traditional reconstruction loss to improve representation learning and robustness. Unlike conventional Masked Autoencoders (MAE), which focus solely on reconstructing missing inputs, DenoMAE2.0 introduces position-aware classification of unmasked patches, enabling the model to capture fine-grained local features while maintaining global coherence. This dual-objective approach is particularly beneficial in semi-supervised learning for wireless communication, where high noise levels and data scarcity pose significant challenges. We conduct extensive experiments on modulation signal classification across a wide range of signal-to-noise ratios (SNRs), from extremely low to moderately high conditions and in a low data regime. Our results demonstrate that DenoMAE2.0 surpasses its predecessor, Deno-MAE, and other baselines in both denoising quality and downstream classification accuracy. DenoMAE2.0 achieves a 1.1% improvement over DenoMAE on our dataset and 11.83%, 16.55% significant improved accuracy gains on the RadioML benchmark, over DenoMAE, for constellation diagram classification of modulation signals.
DenoMAE: A Multimodal Autoencoder for Denoising Modulation Signals
Jan 20, 2025We propose Denoising Masked Autoencoder (Deno-MAE), a novel multimodal autoencoder framework for denoising modulation signals during pretraining. DenoMAE extends the concept of masked autoencoders by incorporating multiple input modalities, including noise as an explicit modality, to enhance cross-modal learning and improve denoising performance. The network is pre-trained using unlabeled noisy modulation signals and constellation diagrams, effectively learning to reconstruct their equivalent noiseless signals and diagrams. Deno-MAE achieves state-of-the-art accuracy in automatic modulation classification tasks with significantly fewer training samples, demonstrating a 10% reduction in unlabeled pretraining data and a 3% reduction in labeled fine-tuning data compared to existing approaches. Moreover, our model exhibits robust performance across varying signal-to-noise ratios (SNRs) and supports extrapolation on unseen lower SNRs. The results indicate that DenoMAE is an efficient, flexible, and data-efficient solution for denoising and classifying modulation signals in challenging noise-intensive environments.
NMformer: A Transformer for Noisy Modulation Classification in Wireless Communication
Oct 30, 2024
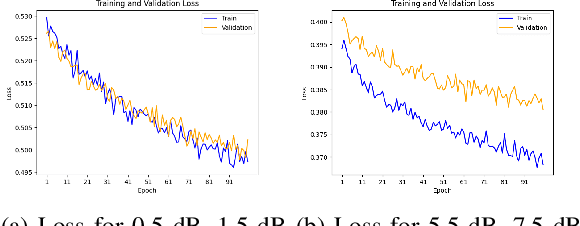

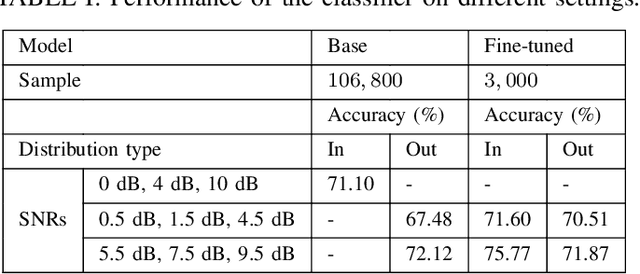
Modulation classification is a very challenging task since the signals intertwine with various ambient noises. Methods are required that can classify them without adding extra steps like denoising, which introduces computational complexity. In this study, we propose a vision transformer (ViT) based model named NMformer to predict the channel modulation images with different noise levels in wireless communication. Since ViTs are most effective for RGB images, we generated constellation diagrams from the modulated signals. The diagrams provide the information from the signals in a 2-D representation form. We trained NMformer on 106, 800 modulation images to build the base classifier and only used 3, 000 images to fine-tune for specific tasks. Our proposed model has two different kinds of prediction setups: in-distribution and out-of-distribution. Our model achieves 4.67% higher accuracy than the base classifier when finetuned and tested on high signal-to-noise ratios (SNRs) in-distribution classes. Moreover, the fine-tuned low SNR task achieves a higher accuracy than the base classifier. The fine-tuned classifier becomes much more effective than the base classifier by achieving higher accuracy when predicted, even on unseen data from out-of-distribution classes. Extensive experiments show the effectiveness of NMformer for a wide range of SNRs.
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Jun 20, 2024



Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.