 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoMAE: A Multimodal Autoencoder for Denoising Modulation Signals
Jan 20, 2025We propose Denoising Masked Autoencoder (Deno-MAE), a novel multimodal autoencoder framework for denoising modulation signals during pretraining. DenoMAE extends the concept of masked autoencoders by incorporating multiple input modalities, including noise as an explicit modality, to enhance cross-modal learning and improve denoising performance. The network is pre-trained using unlabeled noisy modulation signals and constellation diagrams, effectively learning to reconstruct their equivalent noiseless signals and diagrams. Deno-MAE achieves state-of-the-art accuracy in automatic modulation classification tasks with significantly fewer training samples, demonstrating a 10% reduction in unlabeled pretraining data and a 3% reduction in labeled fine-tuning data compared to existing approaches. Moreover, our model exhibits robust performance across varying signal-to-noise ratios (SNRs) and supports extrapolation on unseen lower SNRs. The results indicate that DenoMAE is an efficient, flexible, and data-efficient solution for denoising and classifying modulation signals in challenging noise-intensive environments.
Federated Split Learning for Human Activity Recognition with Differential Privacy
Nov 09, 2024This paper proposes a novel intelligent human activity recognition (HAR) framework based on a new design of Federated Split Learning (FSL) with Differential Privacy (DP) over edge networks. Our FSL-DP framework leverages both accelerometer and gyroscope data, achieving significant improvements in HAR accuracy. The evaluation includes a detailed comparison between traditional Federated Learning (FL) and our FSL framework, showing that the FSL framework outperforms FL models in both accuracy and loss metrics. Additionally, we examine the privacy-performance trade-off under different data settings in the DP mechanism, highlighting the balance between privacy guarantees and model accuracy. The results also indicate that our FSL framework achieves faster communication times per training round compared to traditional FL, further emphasizing its efficiency and effectiveness. This work provides valuable insight and a novel framework which was tested on a real-life dataset.
Meta-Tasks: An alternative view on Meta-Learning Regularization
Feb 27, 2024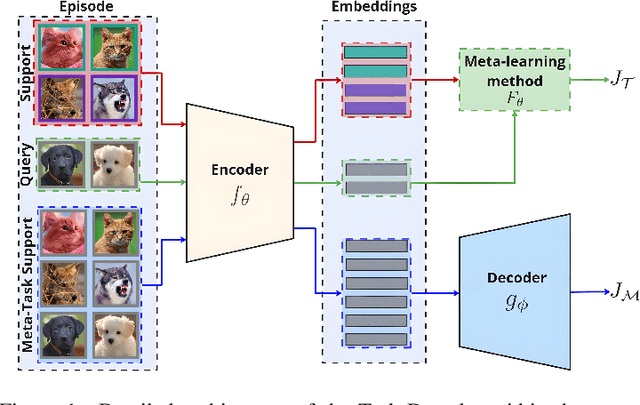

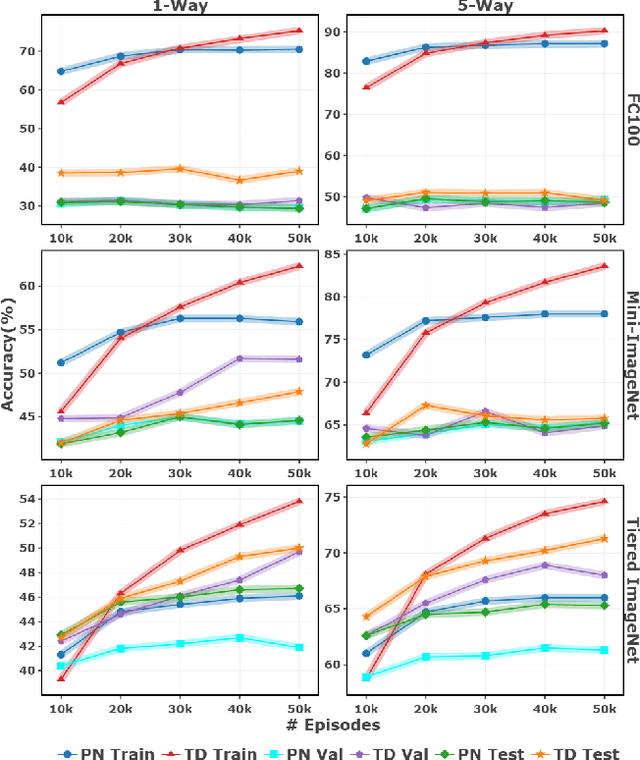
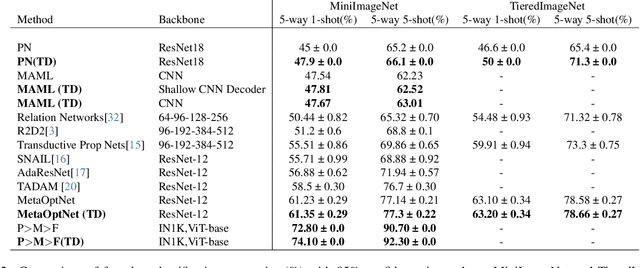
Few-shot learning (FSL) is a challenging machine learning problem due to a scarcity of labeled data. The ability to generalize effectively on both novel and training tasks is a significant barrier to FSL. This paper proposes a novel solution that can generalize to both training and novel tasks while also utilizing unlabeled samples. The method refines the embedding model before updating the outer loop using unsupervised techniques as ``meta-tasks''. The experimental results show that our proposed method performs well on novel and training tasks, with faster and better convergence, lower generalization, and standard deviation error, indicating its potential for practical applications in FSL. The experimental results show that the proposed method outperforms prototypical networks by 3.9%.
Unsupervised Representation Learning to Aid Semi-Supervised Meta Learning
Oct 19, 2023



Few-shot learning or meta-learning leverages the data scarcity problem in machine learning. Traditionally, training data requires a multitude of samples and labeling for supervised learning. To address this issue, we propose a one-shot unsupervised meta-learning to learn the latent representation of the training samples. We use augmented samples as the query set during the training phase of the unsupervised meta-learning. A temperature-scaled cross-entropy loss is used in the inner loop of meta-learning to prevent overfitting during unsupervised learning. The learned parameters from this step are applied to the targeted supervised meta-learning in a transfer-learning fashion for initialization and fast adaptation with improved accuracy. The proposed method is model agnostic and can aid any meta-learning model to improve accuracy. We use model agnostic meta-learning (MAML) and relation network (RN) on Omniglot and mini-Imagenet datasets to demonstrate the performance of the proposed method. Furthermore, a meta-learning model with the proposed initialization can achieve satisfactory accuracy with significantly fewer training samples.