 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Masked Autoencoders: Unlocking Vision Transformer Potential with Limited Data
Jan 27, 2026We address the challenge of training Vision Transformers (ViTs) when labeled data is scarce but unlabeled data is abundant. We propose Semi-Supervised Masked Autoencoder (SSMAE), a framework that jointly optimizes masked image reconstruction and classification using both unlabeled and labeled samples with dynamically selected pseudo-labels. SSMAE introduces a validation-driven gating mechanism that activates pseudo-labeling only after the model achieves reliable, high-confidence predictions that are consistent across both weakly and strongly augmented views of the same image, reducing confirmation bias. On CIFAR-10 and CIFAR-100, SSMAE consistently outperforms supervised ViT and fine-tuned MAE, with the largest gains in low-label regimes (+9.24% over ViT on CIFAR-10 with 10% labels). Our results demonstrate that when pseudo-labels are introduced is as important as how they are generated for data-efficient transformer training. Codes are available at https://github.com/atik666/ssmae.
Finetune-Informed Pretraining Boosts Downstream Performance
Jan 27, 2026Multimodal pretraining is effective for building general-purpose representations, but in many practical deployments, only one modality is heavily used during downstream fine-tuning. Standard pretraining strategies treat all modalities uniformly, which can lead to under-optimized representations for the modality that actually matters. We propose Finetune-Informed Pretraining (FIP), a model-agnostic method that biases representation learning toward a designated target modality needed at fine-tuning time. FIP combines higher masking difficulty, stronger loss weighting, and increased decoder capacity for the target modality, without modifying the shared encoder or requiring additional supervision. When applied to masked modeling on constellation diagrams for wireless signals, FIP consistently improves downstream fine-tuned performance with no extra data or compute. FIP is simple to implement, architecture-compatible, and broadly applicable across multimodal masked modeling pipelines.
CageDroneRF: A Large-Scale RF Benchmark and Toolkit for Drone Perception
Jan 06, 2026We present CageDroneRF (CDRF), a large-scale benchmark for Radio-Frequency (RF) drone detection and identification built from real-world captures and systematically generated synthetic variants. CDRF addresses the scarcity and limited diversity of existing RF datasets by coupling extensive raw recordings with a principled augmentation pipeline that (i) precisely controls Signal-to-Noise Ratio (SNR), (ii) injects interfering emitters, and (iii) applies frequency shifts with label-consistent bounding-box transformations for detection. This dataset spans a wide range of contemporary drone models, many unavailable in current public datasets, and acquisition conditions, derived from data collected at the Rowan University campus and within a controlled RF-cage facility. CDRF is released with interoperable open-source tools for data generation, preprocessing, augmentation, and evaluation that also operate on existing public benchmarks. CDRF enables standardized benchmarking for classification, open-set recognition, and object detection, supporting rigorous comparisons and reproducible pipelines. By releasing this comprehensive benchmark and tooling, CDRF aims to accelerate progress toward robust, generalizable RF perception models.
Plug-and-Play AMC: Context Is King in Training-Free, Open-Set Modulation with LLMs
May 06, 2025Automatic Modulation Classification (AMC) is critical for efficient spectrum management and robust wireless communications. However, AMC remains challenging due to the complex interplay of signal interference and noise. In this work, we propose an innovative framework that integrates traditional signal processing techniques with Large-Language Models (LLMs) to address AMC. Our approach leverages higher-order statistics and cumulant estimation to convert quantitative signal features into structured natural language prompts. By incorporating exemplar contexts into these prompts, our method exploits the LLM's inherent familiarity with classical signal processing, enabling effective one-shot classification without additional training or preprocessing (e.g., denoising). Experimental evaluations on synthetically generated datasets, spanning both noiseless and noisy conditions, demonstrate that our framework achieves competitive performance across diverse modulation schemes and Signal-to-Noise Ratios (SNRs). Moreover, our approach paves the way for robust foundation models in wireless communications across varying channel conditions, significantly reducing the expense associated with developing channel-specific models. This work lays the foundation for scalable, interpretable, and versatile signal classification systems in next-generation wireless networks. The source code is available at https://github.com/RU-SIT/context-is-king
DenoMAE2.0: Improving Denoising Masked Autoencoders by Classifying Local Patches
Feb 25, 2025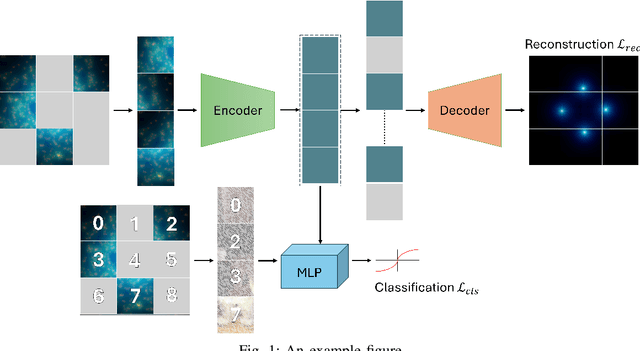
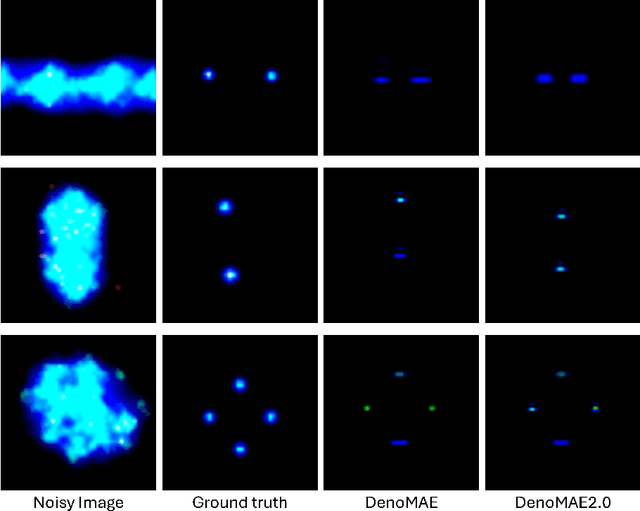
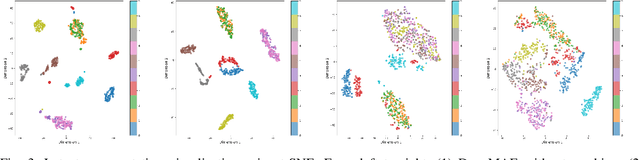
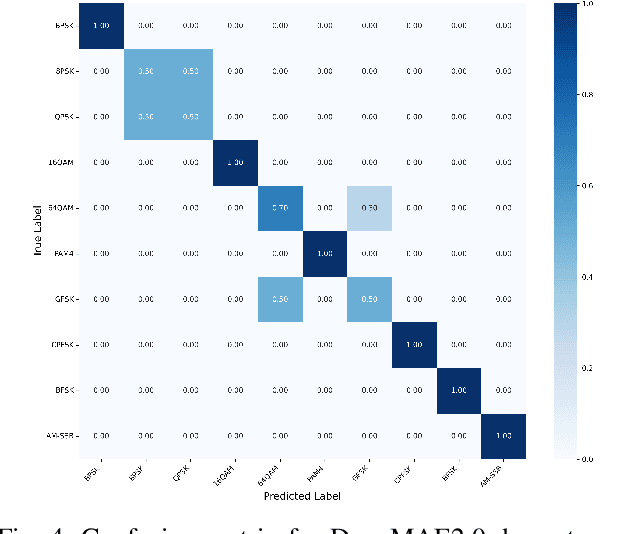
We introduce DenoMAE2.0, an enhanced denoising masked autoencoder that integrates a local patch classification objective alongside traditional reconstruction loss to improve representation learning and robustness. Unlike conventional Masked Autoencoders (MAE), which focus solely on reconstructing missing inputs, DenoMAE2.0 introduces position-aware classification of unmasked patches, enabling the model to capture fine-grained local features while maintaining global coherence. This dual-objective approach is particularly beneficial in semi-supervised learning for wireless communication, where high noise levels and data scarcity pose significant challenges. We conduct extensive experiments on modulation signal classification across a wide range of signal-to-noise ratios (SNRs), from extremely low to moderately high conditions and in a low data regime. Our results demonstrate that DenoMAE2.0 surpasses its predecessor, Deno-MAE, and other baselines in both denoising quality and downstream classification accuracy. DenoMAE2.0 achieves a 1.1% improvement over DenoMAE on our dataset and 11.83%, 16.55% significant improved accuracy gains on the RadioML benchmark, over DenoMAE, for constellation diagram classification of modulation signals.
DenoMAE: A Multimodal Autoencoder for Denoising Modulation Signals
Jan 20, 2025We propose Denoising Masked Autoencoder (Deno-MAE), a novel multimodal autoencoder framework for denoising modulation signals during pretraining. DenoMAE extends the concept of masked autoencoders by incorporating multiple input modalities, including noise as an explicit modality, to enhance cross-modal learning and improve denoising performance. The network is pre-trained using unlabeled noisy modulation signals and constellation diagrams, effectively learning to reconstruct their equivalent noiseless signals and diagrams. Deno-MAE achieves state-of-the-art accuracy in automatic modulation classification tasks with significantly fewer training samples, demonstrating a 10% reduction in unlabeled pretraining data and a 3% reduction in labeled fine-tuning data compared to existing approaches. Moreover, our model exhibits robust performance across varying signal-to-noise ratios (SNRs) and supports extrapolation on unseen lower SNRs. The results indicate that DenoMAE is an efficient, flexible, and data-efficient solution for denoising and classifying modulation signals in challenging noise-intensive environments.
NMformer: A Transformer for Noisy Modulation Classification in Wireless Communication
Oct 30, 2024
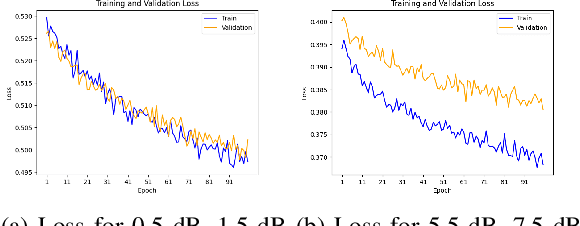

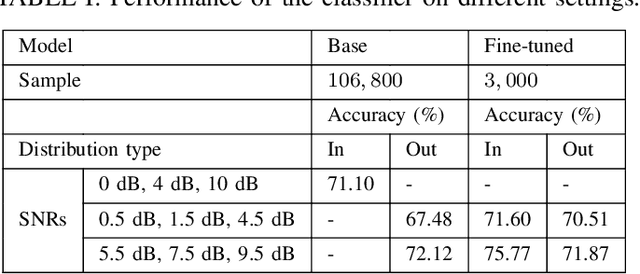
Modulation classification is a very challenging task since the signals intertwine with various ambient noises. Methods are required that can classify them without adding extra steps like denoising, which introduces computational complexity. In this study, we propose a vision transformer (ViT) based model named NMformer to predict the channel modulation images with different noise levels in wireless communication. Since ViTs are most effective for RGB images, we generated constellation diagrams from the modulated signals. The diagrams provide the information from the signals in a 2-D representation form. We trained NMformer on 106, 800 modulation images to build the base classifier and only used 3, 000 images to fine-tune for specific tasks. Our proposed model has two different kinds of prediction setups: in-distribution and out-of-distribution. Our model achieves 4.67% higher accuracy than the base classifier when finetuned and tested on high signal-to-noise ratios (SNRs) in-distribution classes. Moreover, the fine-tuned low SNR task achieves a higher accuracy than the base classifier. The fine-tuned classifier becomes much more effective than the base classifier by achieving higher accuracy when predicted, even on unseen data from out-of-distribution classes. Extensive experiments show the effectiveness of NMformer for a wide range of SNRs.
SimO Loss: Anchor-Free Contrastive Loss for Fine-Grained Supervised Contrastive Learning
Oct 07, 2024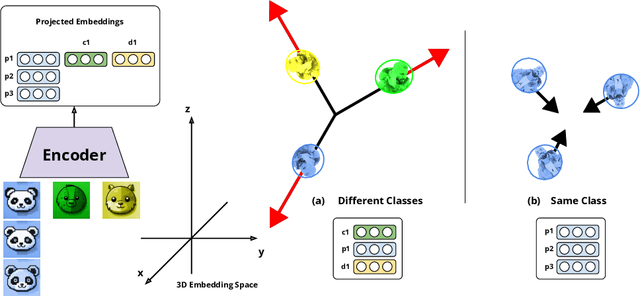

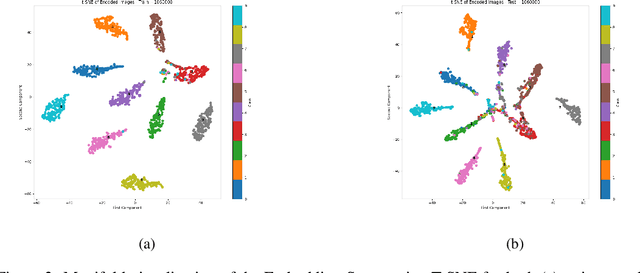
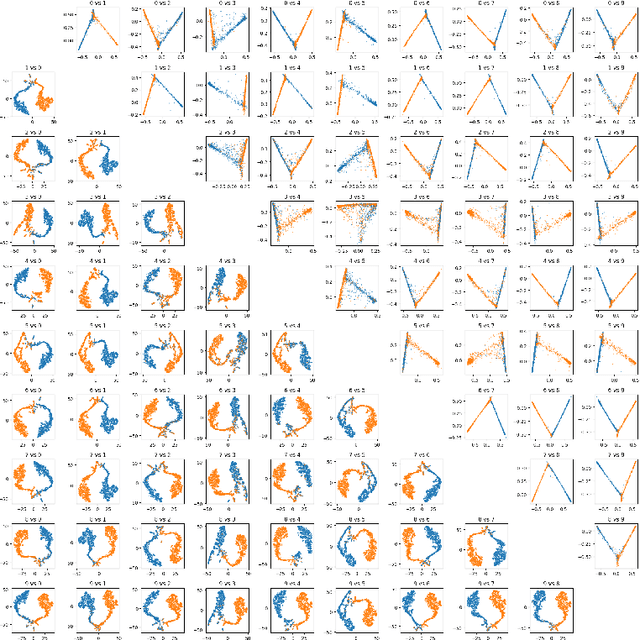
We introduce a novel anchor-free contrastive learning (AFCL) method leveraging our proposed Similarity-Orthogonality (SimO) loss. Our approach minimizes a semi-metric discriminative loss function that simultaneously optimizes two key objectives: reducing the distance and orthogonality between embeddings of similar inputs while maximizing these metrics for dissimilar inputs, facilitating more fine-grained contrastive learning. The AFCL method, powered by SimO loss, creates a fiber bundle topological structure in the embedding space, forming class-specific, internally cohesive yet orthogonal neighborhoods. We validate the efficacy of our method on the CIFAR-10 dataset, providing visualizations that demonstrate the impact of SimO loss on the embedding space. Our results illustrate the formation of distinct, orthogonal class neighborhoods, showcasing the method's ability to create well-structured embeddings that balance class separation with intra-class variability. This work opens new avenues for understanding and leveraging the geometric properties of learned representations in various machine learning tasks.
Meta-Tasks: An alternative view on Meta-Learning Regularization
Feb 27, 2024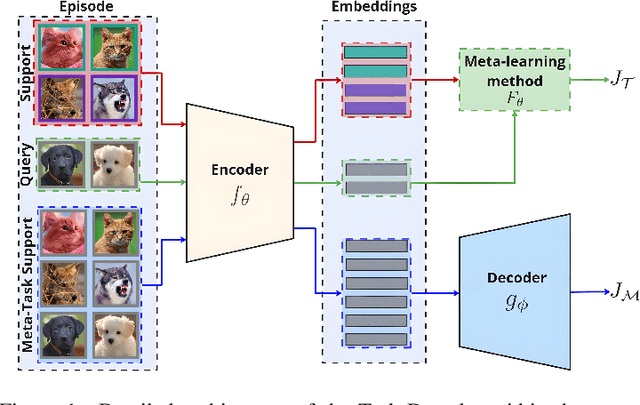

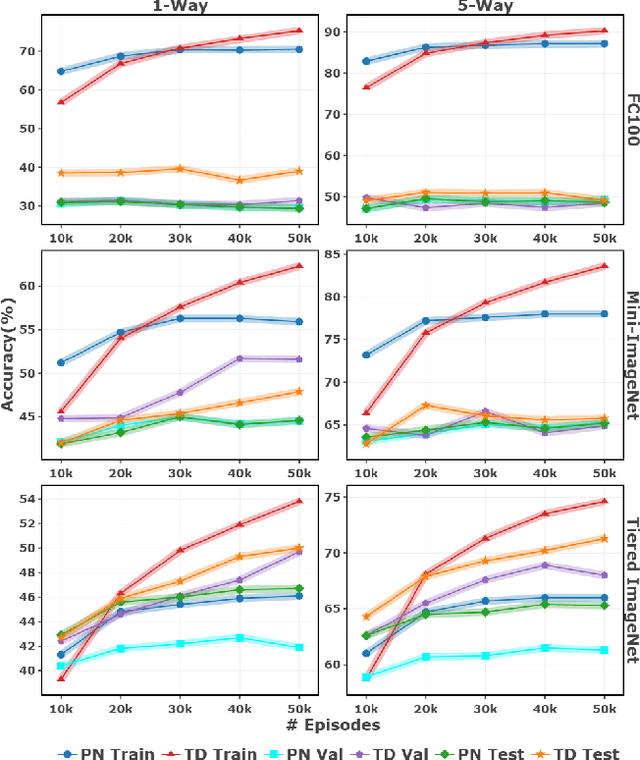
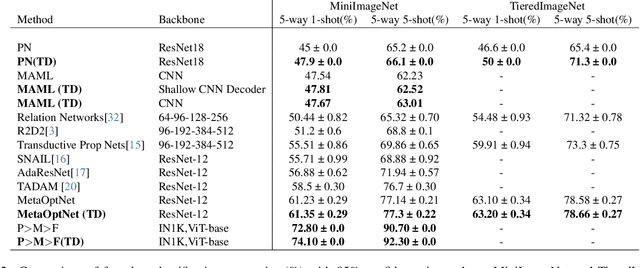
Few-shot learning (FSL) is a challenging machine learning problem due to a scarcity of labeled data. The ability to generalize effectively on both novel and training tasks is a significant barrier to FSL. This paper proposes a novel solution that can generalize to both training and novel tasks while also utilizing unlabeled samples. The method refines the embedding model before updating the outer loop using unsupervised techniques as ``meta-tasks''. The experimental results show that our proposed method performs well on novel and training tasks, with faster and better convergence, lower generalization, and standard deviation error, indicating its potential for practical applications in FSL. The experimental results show that the proposed method outperforms prototypical networks by 3.9%.
Unsupervised Representation Learning to Aid Semi-Supervised Meta Learning
Oct 19, 2023



Few-shot learning or meta-learning leverages the data scarcity problem in machine learning. Traditionally, training data requires a multitude of samples and labeling for supervised learning. To address this issue, we propose a one-shot unsupervised meta-learning to learn the latent representation of the training samples. We use augmented samples as the query set during the training phase of the unsupervised meta-learning. A temperature-scaled cross-entropy loss is used in the inner loop of meta-learning to prevent overfitting during unsupervised learning. The learned parameters from this step are applied to the targeted supervised meta-learning in a transfer-learning fashion for initialization and fast adaptation with improved accuracy. The proposed method is model agnostic and can aid any meta-learning model to improve accuracy. We use model agnostic meta-learning (MAML) and relation network (RN) on Omniglot and mini-Imagenet datasets to demonstrate the performance of the proposed method. Furthermore, a meta-learning model with the proposed initialization can achieve satisfactory accuracy with significantly fewer training samples.