 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAY: Geometry-Aware Spherical Linearized Attention with Yat-Kernel
Feb 04, 2026We propose a new class of linear-time attention mechanisms based on a relaxed and computationally efficient formulation of the recently introduced E-Product, often referred to as the Yat-kernel (Bouhsine, 2025). The resulting interactions are geometry-aware and inspired by inverse-square interactions in physics. Our method, Spherical Linearized Attention with Yat Kernels (SLAY), constrains queries and keys to the unit sphere so that attention depends only on angular alignment. Using Bernstein's theorem, we express the spherical Yat-kernel as a nonnegative mixture of polynomial-exponential product kernels and derive a strictly positive random-feature approximation enabling linear-time O(L) attention. We establish positive definiteness and boundedness on the sphere and show that the estimator yields well-defined, nonnegative attention scores. Empirically, SLAY achieves performance that is nearly indistinguishable from standard softmax attention while retaining linear time and memory scaling, and consistently outperforms prior linear-time attention mechanisms such as Performers and Cosformers. To the best of our knowledge, SLAY represents the closest linear-time approximation to softmax attention reported to date, enabling scalable Transformers without the typical performance trade-offs of attention linearization.
Deep Learning 2.0: Artificial Neurons That Matter -- Reject Correlation, Embrace Orthogonality
Nov 12, 2024


We introduce a yat-product-powered neural network, the Neural Matter Network (NMN), a breakthrough in deep learning that achieves non-linear pattern recognition without activation functions. Our key innovation relies on the yat-product and yat-product, which naturally induces non-linearity by projecting inputs into a pseudo-metric space, eliminating the need for traditional activation functions while maintaining only a softmax layer for final class probability distribution. This approach simplifies network architecture and provides unprecedented transparency into the network's decision-making process. Our comprehensive empirical evaluation across different datasets demonstrates that NMN consistently outperforms traditional MLPs. The results challenge the assumption that separate activation functions are necessary for effective deep-learning models. The implications of this work extend beyond immediate architectural benefits, by eliminating intermediate activation functions while preserving non-linear capabilities, yat-MLP establishes a new paradigm for neural network design that combines simplicity with effectiveness. Most importantly, our approach provides unprecedented insights into the traditionally opaque "black-box" nature of neural networks, offering a clearer understanding of how these models process and classify information.
SimO Loss: Anchor-Free Contrastive Loss for Fine-Grained Supervised Contrastive Learning
Oct 07, 2024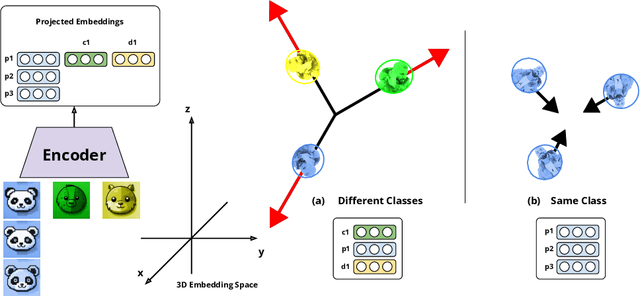

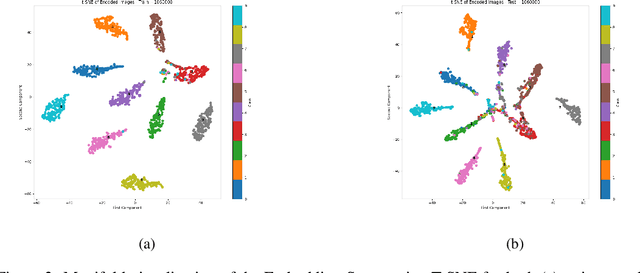
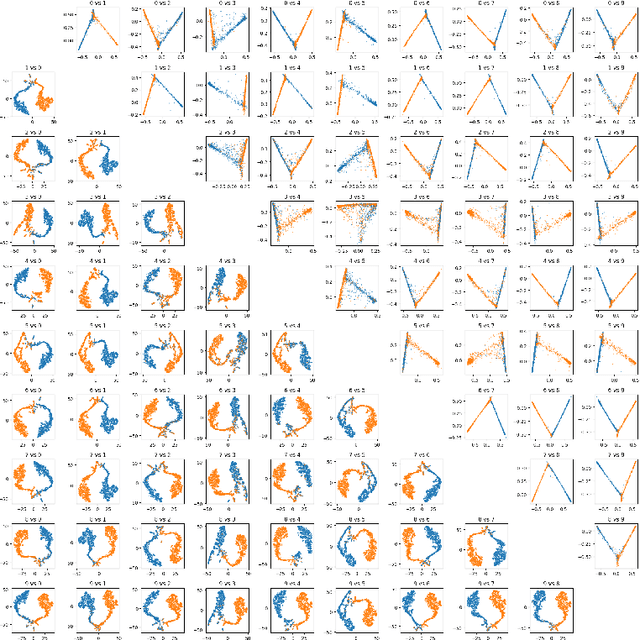
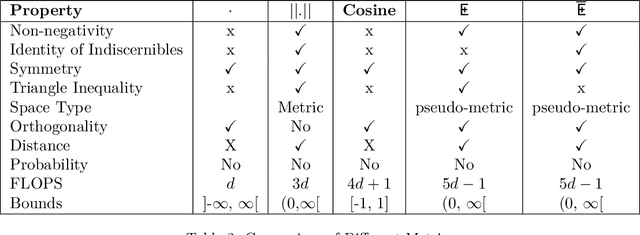
We introduce a novel anchor-free contrastive learning (AFCL) method leveraging our proposed Similarity-Orthogonality (SimO) loss. Our approach minimizes a semi-metric discriminative loss function that simultaneously optimizes two key objectives: reducing the distance and orthogonality between embeddings of similar inputs while maximizing these metrics for dissimilar inputs, facilitating more fine-grained contrastive learning. The AFCL method, powered by SimO loss, creates a fiber bundle topological structure in the embedding space, forming class-specific, internally cohesive yet orthogonal neighborhoods. We validate the efficacy of our method on the CIFAR-10 dataset, providing visualizations that demonstrate the impact of SimO loss on the embedding space. Our results illustrate the formation of distinct, orthogonal class neighborhoods, showcasing the method's ability to create well-structured embeddings that balance class separation with intra-class variability. This work opens new avenues for understanding and leveraging the geometric properties of learned representations in various machine learning tasks.