 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNMformer: A Transformer for Noisy Modulation Classification in Wireless Communication
Paper and Code

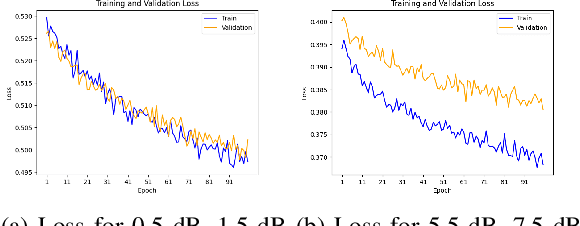

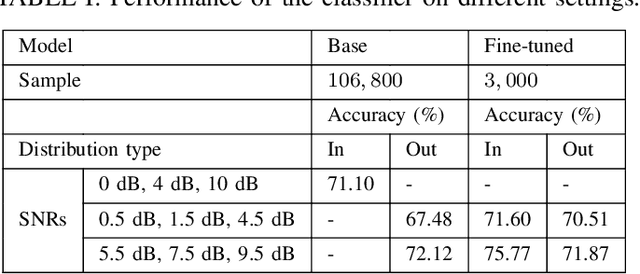
Modulation classification is a very challenging task since the signals intertwine with various ambient noises. Methods are required that can classify them without adding extra steps like denoising, which introduces computational complexity. In this study, we propose a vision transformer (ViT) based model named NMformer to predict the channel modulation images with different noise levels in wireless communication. Since ViTs are most effective for RGB images, we generated constellation diagrams from the modulated signals. The diagrams provide the information from the signals in a 2-D representation form. We trained NMformer on 106, 800 modulation images to build the base classifier and only used 3, 000 images to fine-tune for specific tasks. Our proposed model has two different kinds of prediction setups: in-distribution and out-of-distribution. Our model achieves 4.67% higher accuracy than the base classifier when finetuned and tested on high signal-to-noise ratios (SNRs) in-distribution classes. Moreover, the fine-tuned low SNR task achieves a higher accuracy than the base classifier. The fine-tuned classifier becomes much more effective than the base classifier by achieving higher accuracy when predicted, even on unseen data from out-of-distribution classes. Extensive experiments show the effectiveness of NMformer for a wide range of SNRs.