 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG without Forgetting: Continual Query-Infused Key Memory
Feb 05, 2026Retrieval-augmented generation (RAG) systems commonly improve robustness via query-time adaptations such as query expansion and iterative retrieval. While effective, these approaches are inherently stateless: adaptations are recomputed for each query and discarded thereafter, precluding cumulative learning and repeatedly incurring inference-time cost. Index-side approaches like key expansion introduce persistence but rely on offline preprocessing or heuristic updates that are weakly aligned with downstream task utility, leading to semantic drift and noise accumulation. We propose Evolving Retrieval Memory (ERM), a training-free framework that transforms transient query-time gains into persistent retrieval improvements. ERM updates the retrieval index through correctness-gated feedback, selectively attributes atomic expansion signals to the document keys they benefit, and progressively evolves keys via stable, norm-bounded updates. We show that query and key expansion are theoretically equivalent under standard similarity functions and prove convergence of ERM's selective updates, amortizing optimal query expansion into a stable index with zero inference-time overhead. Experiments on BEIR and BRIGHT across 13 domains demonstrate consistent gains in retrieval and generation, particularly on reasoning-intensive tasks, at native retrieval speed.
Agentic Framework for Epidemiological Modeling
Jan 30, 2026Epidemic modeling is essential for public health planning, yet traditional approaches rely on fixed model classes that require manual redesign as pathogens, policies, and scenario assumptions evolve. We introduce EPIAGENT, an agentic framework that automatically synthesizes, calibrates, verifies, and refines epidemiological simulators by modeling disease progression as an iterative program synthesis problem. A central design choice is an explicit epidemiological flow graph intermediate representation that links scenario specifications to model structure and enables strong, modular correctness checks before code is generated. Verified flow graphs are then compiled into mechanistic models supporting interpretable parameter learning under physical and epidemiological constraints. Evaluation on epidemiological scenario case studies demonstrates that EPIAGENT captures complex growth dynamics and produces epidemiologically consistent counterfactual projections across varying vaccination and immune escape assumptions. Our results show that the agentic feedback loop prevents degeneration and significantly accelerates convergence toward valid models by mimicking professional expert workflows.
Utilizing Metadata for Better Retrieval-Augmented Generation
Jan 17, 2026Retrieval-Augmented Generation systems depend on retrieving semantically relevant document chunks to support accurate, grounded outputs from large language models. In structured and repetitive corpora such as regulatory filings, chunk similarity alone often fails to distinguish between documents with overlapping language. Practitioners often flatten metadata into input text as a heuristic, but the impact and trade-offs of this practice remain poorly understood. We present a systematic study of metadata-aware retrieval strategies, comparing plain-text baselines with approaches that embed metadata directly. Our evaluation spans metadata-as-text (prefix and suffix), a dual-encoder unified embedding that fuses metadata and content in a single index, dual-encoder late-fusion retrieval, and metadata-aware query reformulation. Across multiple retrieval metrics and question types, we find that prefixing and unified embeddings consistently outperform plain-text baselines, with the unified at times exceeding prefixing while being easier to maintain. Beyond empirical comparisons, we analyze embedding space, showing that metadata integration improves effectiveness by increasing intra-document cohesion, reducing inter-document confusion, and widening the separation between relevant and irrelevant chunks. Field-level ablations show that structural cues provide strong disambiguating signals. Our code, evaluation framework, and the RAGMATE-10K dataset are publicly hosted.
Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects
Dec 14, 2025Agent memory has been touted as a dimension of growth for LLM-based applications, enabling agents that can accumulate experience, adapt across sessions, and move beyond single-shot question answering. The current generation of agent memory systems treats memory as an external layer that extracts salient snippets from conversations, stores them in vector or graph-based stores, and retrieves top-k items into the prompt of an otherwise stateless model. While these systems improve personalization and context carry-over, they still blur the line between evidence and inference, struggle to organize information over long horizons, and offer limited support for agents that must explain their reasoning. We present Hindsight, a memory architecture that treats agent memory as a structured, first-class substrate for reasoning by organizing it into four logical networks that distinguish world facts, agent experiences, synthesized entity summaries, and evolving beliefs. This framework supports three core operations -- retain, recall, and reflect -- that govern how information is added, accessed, and updated. Under this abstraction, a temporal, entity aware memory layer incrementally turns conversational streams into a structured, queryable memory bank, while a reflection layer reasons over this bank to produce answers and to update information in a traceable way. On key long-horizon conversational memory benchmarks like LongMemEval and LoCoMo, Hindsight with an open-source 20B model lifts overall accuracy from 39% to 83.6% over a full-context baseline with the same backbone and outperforms full context GPT-4o. Scaling the backbone further pushes Hindsight to 91.4% on LongMemEval and up to 89.61% on LoCoMo (vs. 75.78% for the strongest prior open system), consistently outperforming existing memory architectures on multi-session and open-domain questions.
Exploring LLMs for Scientific Information Extraction Using The SciEx Framework
Dec 10, 2025Large language models (LLMs) are increasingly touted as powerful tools for automating scientific information extraction. However, existing methods and tools often struggle with the realities of scientific literature: long-context documents, multi-modal content, and reconciling varied and inconsistent fine-grained information across multiple publications into standardized formats. These challenges are further compounded when the desired data schema or extraction ontology changes rapidly, making it difficult to re-architect or fine-tune existing systems. We present SciEx, a modular and composable framework that decouples key components including PDF parsing, multi-modal retrieval, extraction, and aggregation. This design streamlines on-demand data extraction while enabling extensibility and flexible integration of new models, prompting strategies, and reasoning mechanisms. We evaluate SciEx on datasets spanning three scientific topics for its ability to extract fine-grained information accurately and consistently. Our findings provide practical insights into both the strengths and limitations of current LLM-based pipelines.
Demystify, Use, Reflect: Preparing students to be informed LLM-users
Nov 14, 2025We transitioned our post-CS1 course that introduces various subfields of computer science so that it integrates Large Language Models (LLMs) in a structured, critical, and practical manner. It aims to help students develop the skills needed to engage meaningfully and responsibly with AI. The course now includes explicit instruction on how LLMs work, exposure to current tools, ethical issues, and activities that encourage student reflection on personal use of LLMs as well as the larger evolving landscape of AI-assisted programming. In class, we demonstrate the use and verification of LLM outputs, guide students in the use of LLMs as an ingredient in a larger problem-solving loop, and require students to disclose and acknowledge the nature and extent of LLM assistance. Throughout the course, we discuss risks and benefits of LLMs across CS subfields. In our first iteration of the course, we collected and analyzed data from students pre and post surveys. Student understanding of how LLMs work became more technical, and their verification and use of LLMs shifted to be more discerning and collaborative. These strategies can be used in other courses to prepare students for the AI-integrated future.
When can isotropy help adapt LLMs' next word prediction to numerical domains?
May 26, 2025Recent studies have shown that vector representations of contextual embeddings learned by pre-trained large language models (LLMs) are effective in various downstream tasks in numerical domains. Despite their significant benefits, the tendency of LLMs to hallucinate in such domains can have severe consequences in applications such as energy, nature, finance, healthcare, retail and transportation, among others. To guarantee prediction reliability and accuracy in numerical domains, it is necessary to open the black-box and provide performance guarantees through explanation. However, there is little theoretical understanding of when pre-trained language models help solve numeric downstream tasks. This paper seeks to bridge this gap by understanding when the next-word prediction capability of LLMs can be adapted to numerical domains through a novel analysis based on the concept of isotropy in the contextual embedding space. Specifically, we consider a log-linear model for LLMs in which numeric data can be predicted from its context through a network with softmax in the output layer of LLMs (i.e., language model head in self-attention). We demonstrate that, in order to achieve state-of-the-art performance in numerical domains, the hidden representations of the LLM embeddings must possess a structure that accounts for the shift-invariance of the softmax function. By formulating a gradient structure of self-attention in pre-trained models, we show how the isotropic property of LLM embeddings in contextual embedding space preserves the underlying structure of representations, thereby resolving the shift-invariance problem and providing a performance guarantee. Experiments show that different characteristics of numeric data and model architecture could have different impacts on isotropy.
The Prompt is Mightier than the Example
May 24, 2025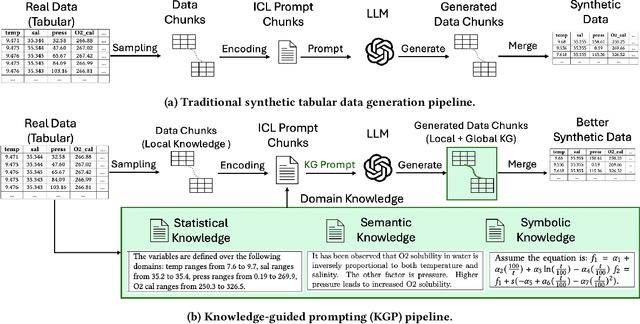
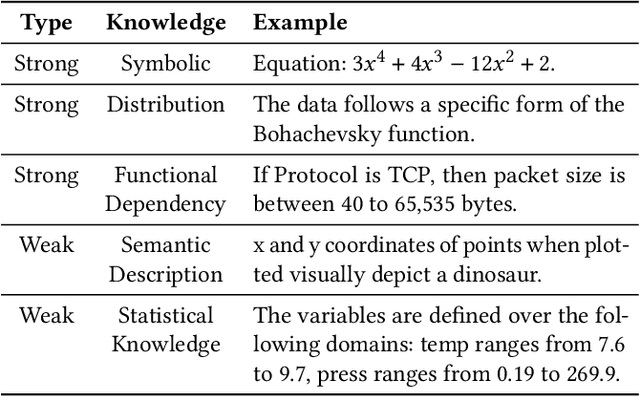
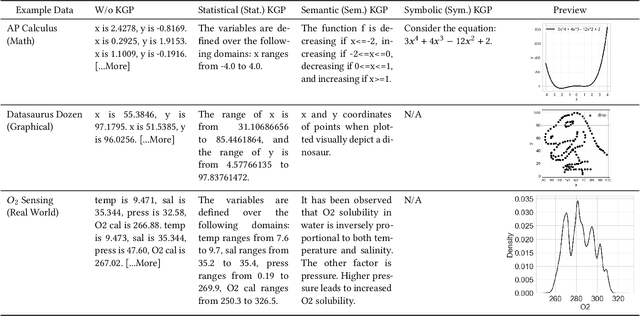
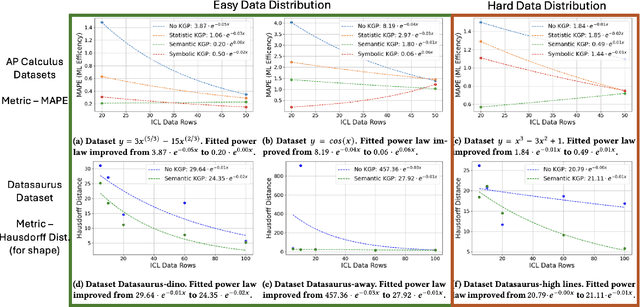
Numerous recent prompt optimization approaches like chain-of-thought, have been demonstrated to significantly improve the quality of content generated by large language models (LLMs). In-context learning (ICL), a recent paradigm where a few representative examples guide content generation has also led to strong improvements in generation quality of LLM generated content. This idea has been applied to great effect in synthetic tabular data generation, where LLMs, through effective use of ICL and prompt optimization, can generate data that approximate samples from complex, heterogeneous distributions based on representative examples. However, ensuring high-fidelity synthetic data often requires a very large number of ICL examples which may be unavailable or costly to obtain. At the same time, as LLMs get larger and larger, their in-built prior knowledge becomes vast and can potentially substitute for specific data examples. In this paper, we introduce Knowledge-Guided Prompting (KGP) as a new knob in prompt optimization and explore the ability of KGP-based prompt optimization to offset the cost of ICL. Specifically, we explore the question `how many examples can a prompt substitute for?' and explore knowledge-guided prompting (KGP) where domain knowledge, either inferred or available, is explicitly injected into the prompt, reducing dependence on ICL examples. Our experiments systematically explore the trade-off between ICL and KGP, revealing an empirical scaling law that quantifies how quality of generated synthetic data varies with increasing domain knowledge and decreasing example count. Our results demonstrate that knowledge-guided prompting can be a scalable alternative, or addition, to in-context examples, unlocking new approaches to synthetic data generation.
World Model-Based Learning for Long-Term Age of Information Minimization in Vehicular Networks
May 03, 2025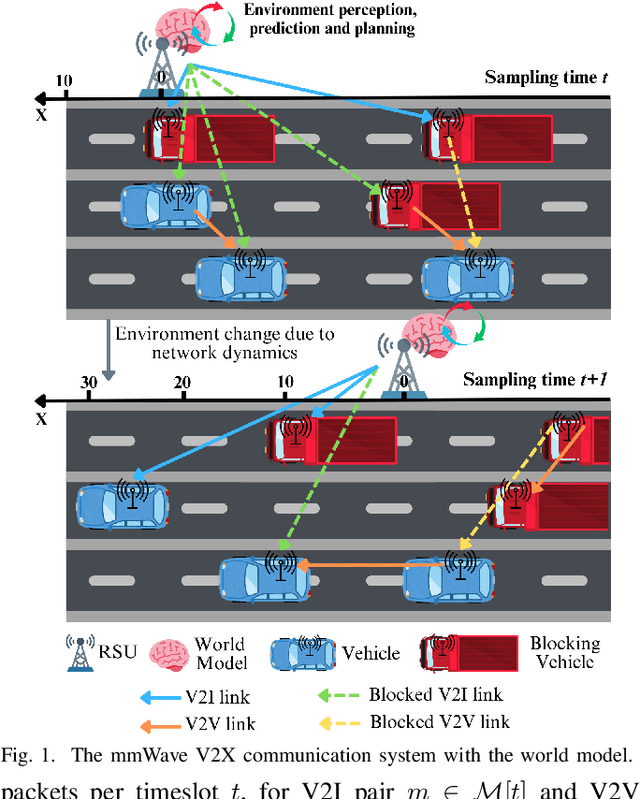
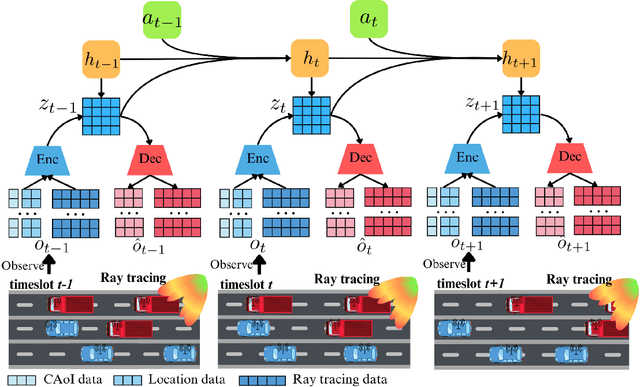
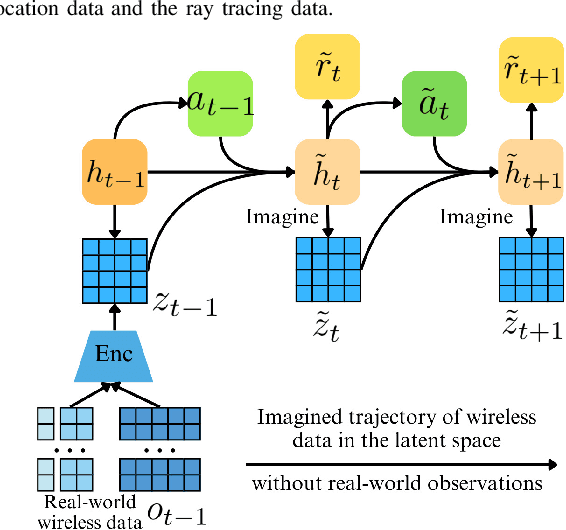
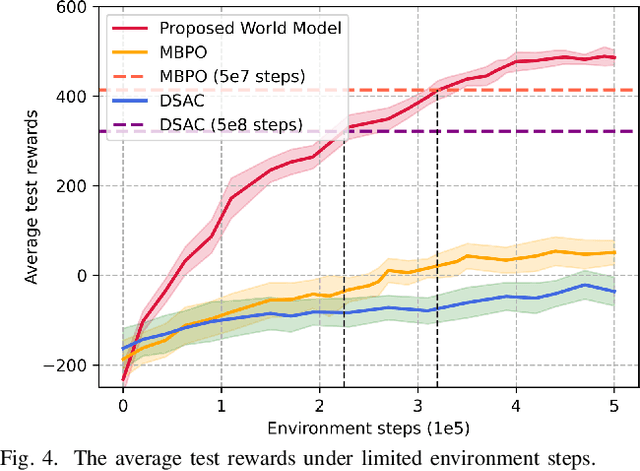
Traditional reinforcement learning (RL)-based learning approaches for wireless networks rely on expensive trial-and-error mechanisms and real-time feedback based on extensive environment interactions, which leads to low data efficiency and short-sighted policies. These limitations become particularly problematic in complex, dynamic networks with high uncertainty and long-term planning requirements. To address these limitations, in this paper, a novel world model-based learning framework is proposed to minimize packet-completeness-aware age of information (CAoI) in a vehicular network. Particularly, a challenging representative scenario is considered pertaining to a millimeter-wave (mmWave) vehicle-to-everything (V2X) communication network, which is characterized by high mobility, frequent signal blockages, and extremely short coherence time. Then, a world model framework is proposed to jointly learn a dynamic model of the mmWave V2X environment and use it to imagine trajectories for learning how to perform link scheduling. In particular, the long-term policy is learned in differentiable imagined trajectories instead of environment interactions. Moreover, owing to its imagination abilities, the world model can jointly predict time-varying wireless data and optimize link scheduling in real-world wireless and V2X networks. Thus, during intervals without actual observations, the world model remains capable of making efficient decisions. Extensive experiments are performed on a realistic simulator based on Sionna that integrates physics-based end-to-end channel modeling, ray-tracing, and scene geometries with material properties. Simulation results show that the proposed world model achieves a significant improvement in data efficiency, and achieves 26% improvement and 16% improvement in CAoI, respectively, compared to the model-based RL (MBRL) method and the model-free RL (MFRL) method.
Optimizing Product Provenance Verification using Data Valuation Methods
Feb 21, 2025Determining and verifying product provenance remains a critical challenge in global supply chains, particularly as geopolitical conflicts and shifting borders create new incentives for misrepresentation of commodities, such as hiding the origin of illegally harvested timber or stolen agricultural products. Stable Isotope Ratio Analysis (SIRA), combined with Gaussian process regression-based isoscapes, has emerged as a powerful tool for geographic origin verification. However, the effectiveness of these models is often constrained by data scarcity and suboptimal dataset selection. In this work, we introduce a novel data valuation framework designed to enhance the selection and utilization of training data for machine learning models applied in SIRA. By prioritizing high-informative samples, our approach improves model robustness and predictive accuracy across diverse datasets and geographies. We validate our methodology with extensive experiments, demonstrating its potential to significantly enhance provenance verification, mitigate fraudulent trade practices, and strengthen regulatory enforcement of global supply chains.