 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Metadata for Better Retrieval-Augmented Generation
Jan 17, 2026Retrieval-Augmented Generation systems depend on retrieving semantically relevant document chunks to support accurate, grounded outputs from large language models. In structured and repetitive corpora such as regulatory filings, chunk similarity alone often fails to distinguish between documents with overlapping language. Practitioners often flatten metadata into input text as a heuristic, but the impact and trade-offs of this practice remain poorly understood. We present a systematic study of metadata-aware retrieval strategies, comparing plain-text baselines with approaches that embed metadata directly. Our evaluation spans metadata-as-text (prefix and suffix), a dual-encoder unified embedding that fuses metadata and content in a single index, dual-encoder late-fusion retrieval, and metadata-aware query reformulation. Across multiple retrieval metrics and question types, we find that prefixing and unified embeddings consistently outperform plain-text baselines, with the unified at times exceeding prefixing while being easier to maintain. Beyond empirical comparisons, we analyze embedding space, showing that metadata integration improves effectiveness by increasing intra-document cohesion, reducing inter-document confusion, and widening the separation between relevant and irrelevant chunks. Field-level ablations show that structural cues provide strong disambiguating signals. Our code, evaluation framework, and the RAGMATE-10K dataset are publicly hosted.
LLM Augmentations to support Analytical Reasoning over Multiple Documents
Nov 25, 2024
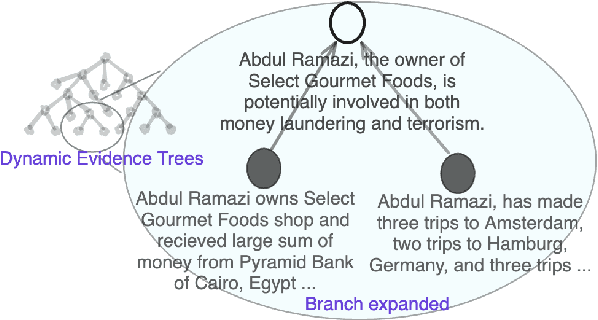

Building on their demonstrated ability to perform a variety of tasks, we investigate the application of large language models (LLMs) to enhance in-depth analytical reasoning within the context of intelligence analysis. Intelligence analysts typically work with massive dossiers to draw connections between seemingly unrelated entities, and uncover adversaries' plans and motives. We explore if and how LLMs can be helpful to analysts for this task and develop an architecture to augment the capabilities of an LLM with a memory module called dynamic evidence trees (DETs) to develop and track multiple investigation threads. Through extensive experiments on multiple datasets, we highlight how LLMs, as-is, are still inadequate to support intelligence analysts and offer recommendations to improve LLMs for such intricate reasoning applications.
Information Guided Regularization for Fine-tuning Language Models
Jun 20, 2024



The pretraining-fine-tuning paradigm has been the de facto strategy for transfer learning in modern language modeling. With the understanding that task adaptation in LMs is often a function of parameters shared across tasks, we argue that a more surgical approach to regularization needs to exist for smoother transfer learning. Towards this end, we investigate how the pretraining loss landscape is affected by these task-sensitive parameters through an information-theoretic lens. We then leverage the findings from our investigations to devise a novel approach to dropout for improved model regularization and better downstream generalization. This approach, named guided dropout, is both task & architecture agnostic and adds no computational overhead to the fine-tuning process. Through empirical evaluations, we showcase that our approach to regularization yields consistently better performance, even in scenarios of data paucity, compared to standardized baselines.
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Jun 20, 2024



Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
Laying Anchors: Semantically Priming Numerals in Language Modeling
Apr 02, 2024Off-the-shelf pre-trained language models have become the de facto standard in NLP pipelines for a multitude of downstream tasks. However, the inability of these models to properly encode numerals limits their performance on tasks requiring numeric comprehension. We introduce strategies to semantically prime numerals in any corpus by generating anchors governed by the distribution of numerals in said corpus, thereby enabling mathematically grounded representations of these numeral tokens. We establish the superiority of our proposed techniques through evaluation on a range of numeracy tasks for both in-domain (seen) and out-domain (unseen) numerals. Further, we expand our empirical evaluations to numerals ranging from 1 to 10 billion, a significantly broader range compared to previous studies of the same nature, and we demonstrate significant improvements in the mathematical grounding of our learned embeddings.
Learning Non-linguistic Skills without Sacrificing Linguistic Proficiency
May 14, 2023


The field of Math-NLP has witnessed significant growth in recent years, motivated by the desire to expand LLM performance to the learning of non-linguistic notions (numerals, and subsequently, arithmetic reasoning). However, non-linguistic skill injection typically comes at a cost for LLMs: it leads to catastrophic forgetting of core linguistic skills, a consequence that often remains unaddressed in the literature. As Math-NLP has been able to create LLMs that can closely approximate the mathematical skills of a grade-schooler or the arithmetic reasoning skills of a calculator, the practicality of these models fail if they concomitantly shed their linguistic capabilities. In this work, we take a closer look into the phenomena of catastrophic forgetting as it pertains to LLMs and subsequently offer a novel framework for non-linguistic skill injection for LLMs based on information theoretic interventions and skill-specific losses that enable the learning of strict arithmetic reasoning. Our model outperforms the state-of-the-art both on injected non-linguistic skills and on linguistic knowledge retention, and does so with a fraction of the non-linguistic training data (1/4) and zero additional synthetic linguistic training data.
Overcoming Barriers to Skill Injection in Language Modeling: Case Study in Arithmetic
Nov 03, 2022Through their transfer learning abilities, highly-parameterized large pre-trained language models have dominated the NLP landscape for a multitude of downstream language tasks. Though linguistically proficient, the inability of these models to incorporate the learning of non-linguistic entities (numerals and arithmetic reasoning) limits their usage for tasks that require numeric comprehension or strict mathematical reasoning. However, as we illustrate in this paper, building a general purpose language model that also happens to be proficient in mathematical reasoning is not as straight-forward as training it on a numeric dataset. In this work, we develop a novel framework that enables language models to be mathematically proficient while retaining their linguistic prowess. Specifically, we offer information-theoretic interventions to overcome the catastrophic forgetting of linguistic skills that occurs while injecting non-linguistic skills into language models.
Innovations in Neural Data-to-text Generation
Jul 25, 2022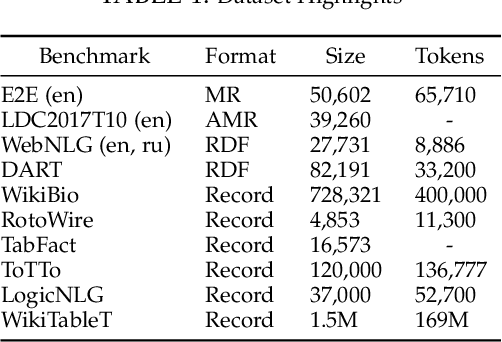
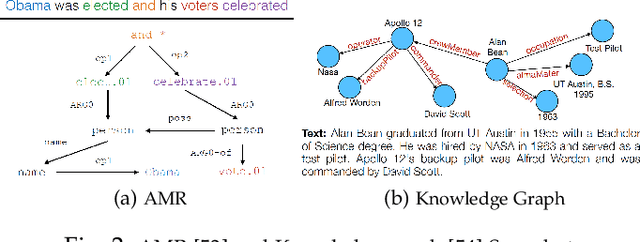

The neural boom that has sparked natural language processing (NLP) research through the last decade has similarly led to significant innovations in data-to-text generation (DTG). This survey offers a consolidated view into the neural DTG paradigm with a structured examination of the approaches, benchmark datasets, and evaluation protocols. This survey draws boundaries separating DTG from the rest of the natural language generation (NLG) landscape, encompassing an up-to-date synthesis of the literature, and highlighting the stages of technological adoption from within and outside the greater NLG umbrella. With this holistic view, we highlight promising avenues for DTG research that not only focus on the design of linguistically capable systems but also systems that exhibit fairness and accountability.
TCube: Domain-Agnostic Neural Time-series Narration
Oct 11, 2021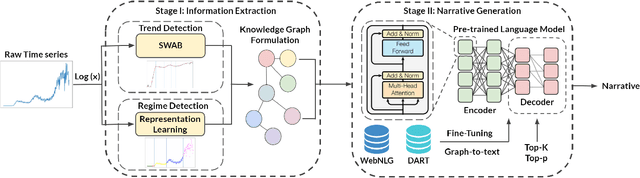
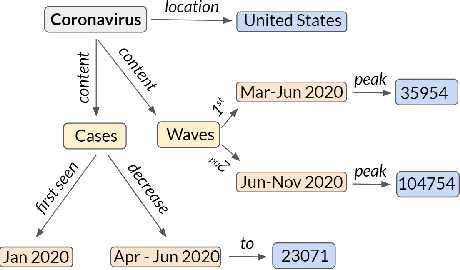
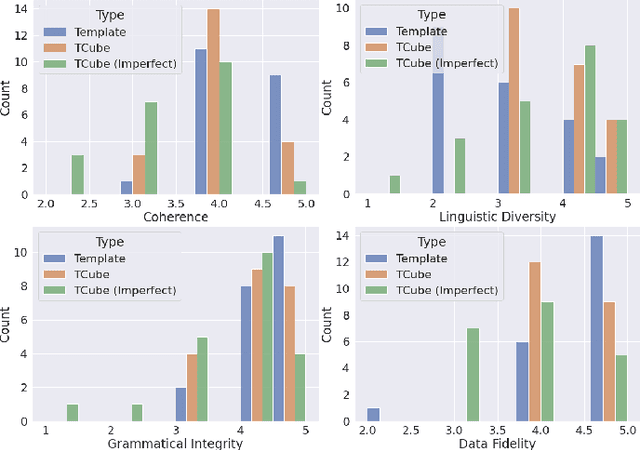
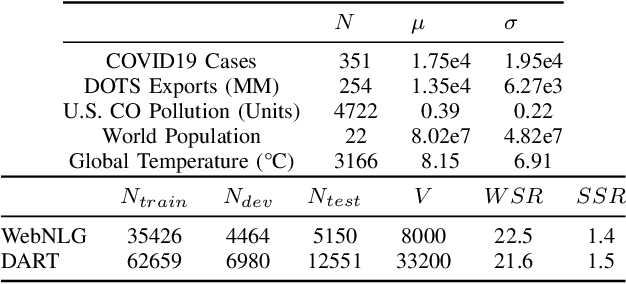
The task of generating rich and fluent narratives that aptly describe the characteristics, trends, and anomalies of time-series data is invaluable to the sciences (geology, meteorology, epidemiology) or finance (trades, stocks, or sales and inventory). The efforts for time-series narration hitherto are domain-specific and use predefined templates that offer consistency but lead to mechanical narratives. We present TCube (Time-series-to-text), a domain-agnostic neural framework for time-series narration, that couples the representation of essential time-series elements in the form of a dense knowledge graph and the translation of said knowledge graph into rich and fluent narratives through the transfer-learning capabilities of PLMs (Pre-trained Language Models). TCube's design primarily addresses the challenge that lies in building a neural framework in the complete paucity of annotated training data for time-series. The design incorporates knowledge graphs as an intermediary for the representation of essential time-series elements which can be linearized for textual translation. To the best of our knowledge, TCube is the first investigation of the use of neural strategies for time-series narration. Through extensive evaluations, we show that TCube can improve the lexical diversity of the generated narratives by up to 65.38% while still maintaining grammatical integrity. The practicality and deployability of TCube is further validated through an expert review (n=21) where 76.2% of participating experts wary of auto-generated narratives favored TCube as a deployable system for time-series narration due to its richer narratives. Our code-base, models, and datasets, with detailed instructions for reproducibility is publicly hosted at https://github.com/Mandar-Sharma/TCube.
Once Upon A Time In Visualization: Understanding the Use of Textual Narratives for Causality
Sep 06, 2020
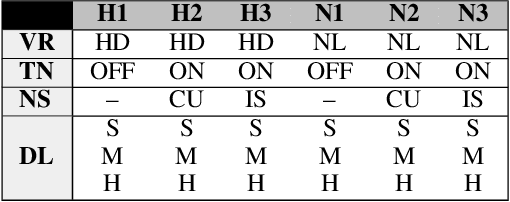
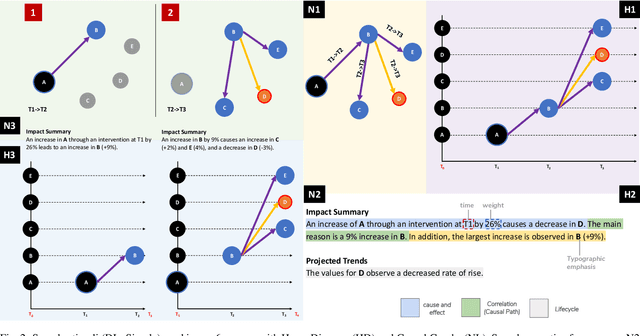

Causality visualization can help people understand temporal chains of events, such as messages sent in a distributed system, cause and effect in a historical conflict, or the interplay between political actors over time. However, as the scale and complexity of these event sequences grows, even these visualizations can become overwhelming to use. In this paper, we propose the use of textual narratives as a data-driven storytelling method to augment causality visualization. We first propose a design space for how textual narratives can be used to describe causal data. We then present results from a crowdsourced user study where participants were asked to recover causality information from two causality visualizations--causal graphs and Hasse diagrams--with and without an associated textual narrative. Finally, we describe CAUSEWORKS, a causality visualization system for understanding how specific interventions influence a causal model. The system incorporates an automatic textual narrative mechanism based on our design space. We validate CAUSEWORKS through interviews with experts who used the system for understanding complex events.