 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSeriesExam: A time series understanding exam
Oct 18, 2024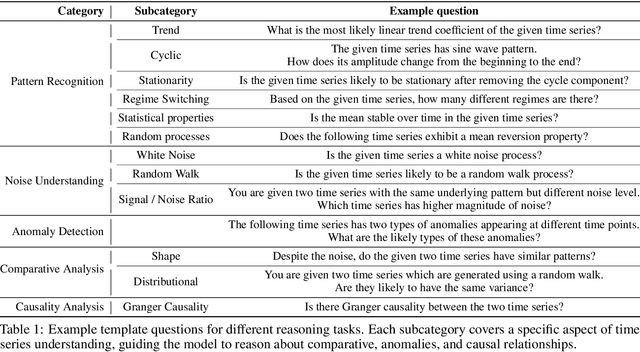
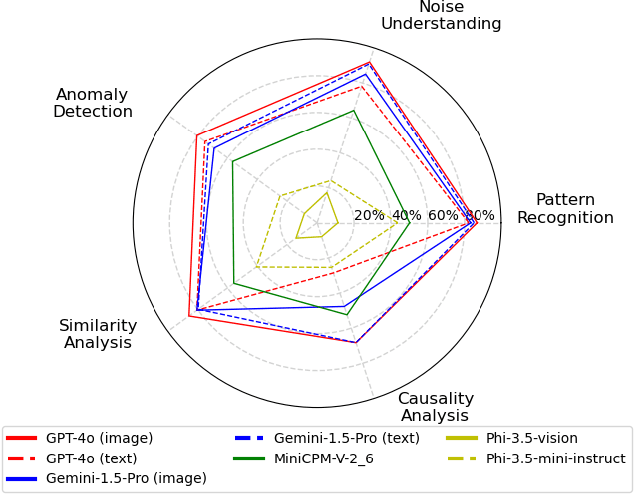
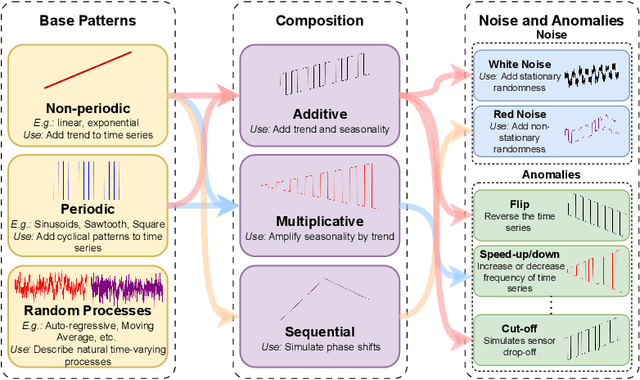
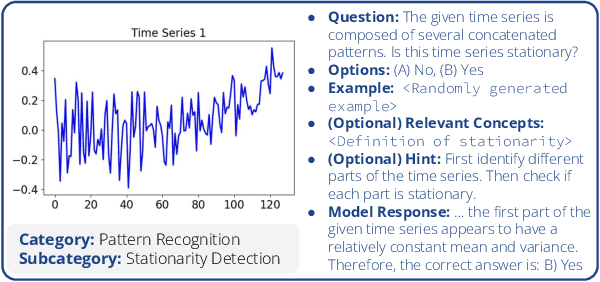
Large Language Models (LLMs) have recently demonstrated a remarkable ability to model time series data. These capabilities can be partly explained if LLMs understand basic time series concepts. However, our knowledge of what these models understand about time series data remains relatively limited. To address this gap, we introduce TimeSeriesExam, a configurable and scalable multiple-choice question exam designed to assess LLMs across five core time series understanding categories: pattern recognition, noise understanding, similarity analysis, anomaly detection, and causality analysis. TimeSeriesExam comprises of over 700 questions, procedurally generated using 104 carefully curated templates and iteratively refined to balance difficulty and their ability to discriminate good from bad models. We test 7 state-of-the-art LLMs on the TimeSeriesExam and provide the first comprehensive evaluation of their time series understanding abilities. Our results suggest that closed-source models such as GPT-4 and Gemini understand simple time series concepts significantly better than their open-source counterparts, while all models struggle with complex concepts such as causality analysis. We believe that the ability to programatically generate questions is fundamental to assessing and improving LLM's ability to understand and reason about time series data.
MOMENT: A Family of Open Time-series Foundation Models
Feb 06, 2024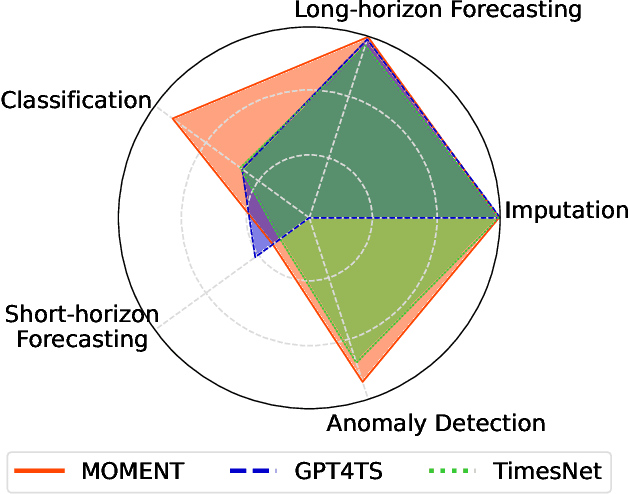
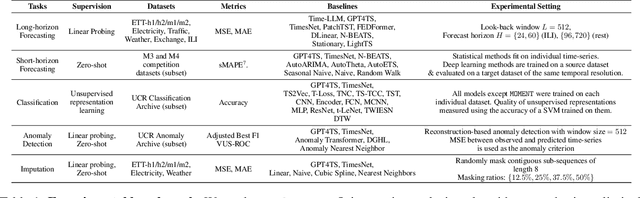
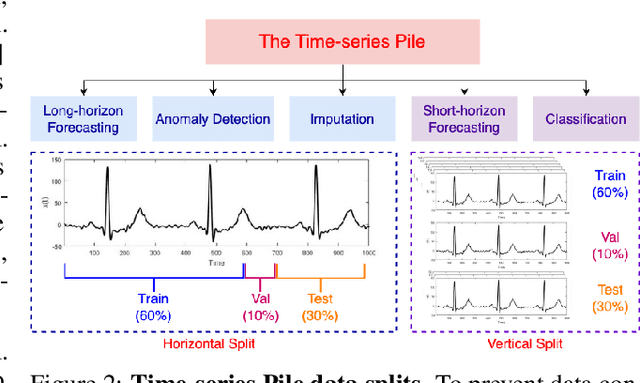
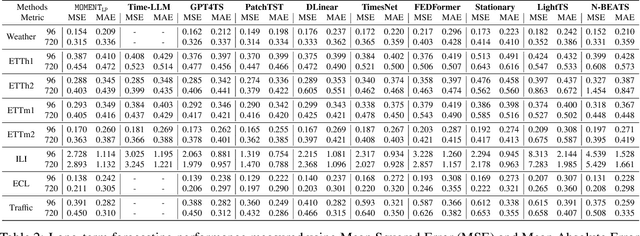
We introduce MOMENT, a family of open-source foundation models for general-purpose time-series analysis. Pre-training large models on time-series data is challenging due to (1) the absence of a large and cohesive public time-series repository, and (2) diverse time-series characteristics which make multi-dataset training onerous. Additionally, (3) experimental benchmarks to evaluate these models, especially in scenarios with limited resources, time, and supervision, are still in their nascent stages. To address these challenges, we compile a large and diverse collection of public time-series, called the Time-series Pile, and systematically tackle time-series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time-series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning. Finally, we present several interesting empirical observations about large pre-trained time-series models. Our code is available anonymously at anonymous.4open.science/r/BETT-773F/.
AQuA: A Benchmarking Tool for Label Quality Assessment
Jun 15, 2023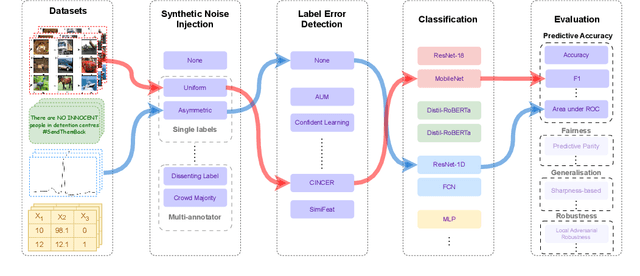
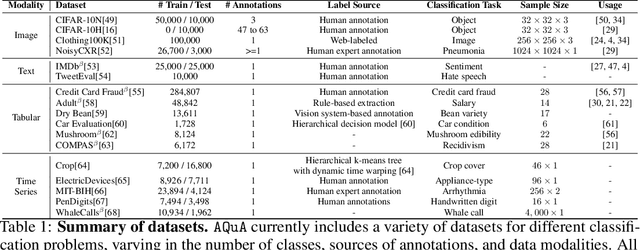
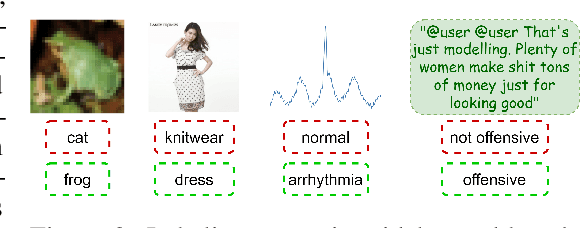
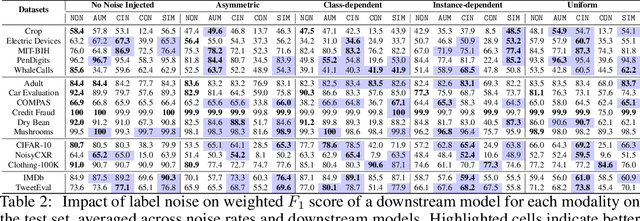
Machine learning (ML) models are only as good as the data they are trained on. But recent studies have found datasets widely used to train and evaluate ML models, e.g. ImageNet, to have pervasive labeling errors. Erroneous labels on the train set hurt ML models' ability to generalize, and they impact evaluation and model selection using the test set. Consequently, learning in the presence of labeling errors is an active area of research, yet this field lacks a comprehensive benchmark to evaluate these methods. Most of these methods are evaluated on a few computer vision datasets with significant variance in the experimental protocols. With such a large pool of methods and inconsistent evaluation, it is also unclear how ML practitioners can choose the right models to assess label quality in their data. To this end, we propose a benchmarking environment AQuA to rigorously evaluate methods that enable machine learning in the presence of label noise. We also introduce a design space to delineate concrete design choices of label error detection models. We hope that our proposed design space and benchmark enable practitioners to choose the right tools to improve their label quality and that our benchmark enables objective and rigorous evaluation of machine learning tools facing mislabeled data.
Adversarial Adaptation for French Named Entity Recognition
Jan 12, 2023

Named Entity Recognition (NER) is the task of identifying and classifying named entities in large-scale texts into predefined classes. NER in French and other relatively limited-resource languages cannot always benefit from approaches proposed for languages like English due to a dearth of large, robust datasets. In this paper, we present our work that aims to mitigate the effects of this dearth of large, labeled datasets. We propose a Transformer-based NER approach for French, using adversarial adaptation to similar domain or general corpora to improve feature extraction and enable better generalization. Our approach allows learning better features using large-scale unlabeled corpora from the same domain or mixed domains to introduce more variations during training and reduce overfitting. Experimental results on three labeled datasets show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of Transformer models, source datasets, and target corpora. We also show that adversarial adaptation to large-scale unlabeled corpora can help mitigate the performance dip incurred on using Transformer models pre-trained on smaller corpora.
An Emotion-Aware Multi-Task Approach to Fake News and Rumour Detection using Transfer Learning
Dec 07, 2022Social networking sites, blogs, and online articles are instant sources of news for internet users globally. However, in the absence of strict regulations mandating the genuineness of every text on social media, it is probable that some of these texts are fake news or rumours. Their deceptive nature and ability to propagate instantly can have an adverse effect on society. This necessitates the need for more effective detection of fake news and rumours on the web. In this work, we annotate four fake news detection and rumour detection datasets with their emotion class labels using transfer learning. We show the correlation between the legitimacy of a text with its intrinsic emotion for fake news and rumour detection, and prove that even within the same emotion class, fake and real news are often represented differently, which can be used for improved feature extraction. Based on this, we propose a multi-task framework for fake news and rumour detection, predicting both the emotion and legitimacy of the text. We train a variety of deep learning models in single-task and multi-task settings for a more comprehensive comparison. We further analyze the performance of our multi-task approach for fake news detection in cross-domain settings to verify its efficacy for better generalization across datasets, and to verify that emotions act as a domain-independent feature. Experimental results verify that our multi-task models consistently outperform their single-task counterparts in terms of accuracy, precision, recall, and F1 score, both for in-domain and cross-domain settings. We also qualitatively analyze the difference in performance in single-task and multi-task learning models.
Transformer-Based Named Entity Recognition for French Using Adversarial Adaptation to Similar Domain Corpora
Dec 05, 2022
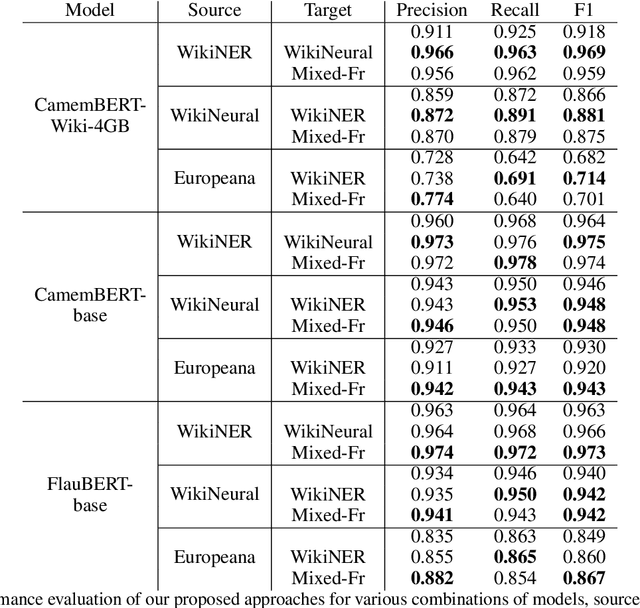
Named Entity Recognition (NER) involves the identification and classification of named entities in unstructured text into predefined classes. NER in languages with limited resources, like French, is still an open problem due to the lack of large, robust, labelled datasets. In this paper, we propose a transformer-based NER approach for French using adversarial adaptation to similar domain or general corpora for improved feature extraction and better generalization. We evaluate our approach on three labelled datasets and show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of transformer models, source datasets and target corpora.
An Emotion-guided Approach to Domain Adaptive Fake News Detection using Adversarial Learning
Nov 26, 2022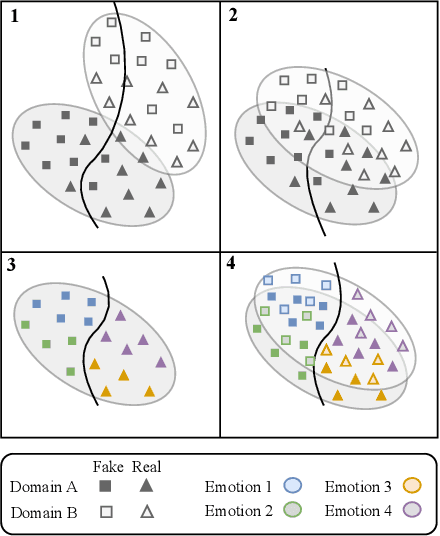
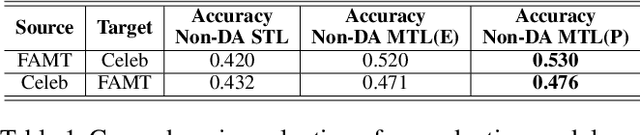
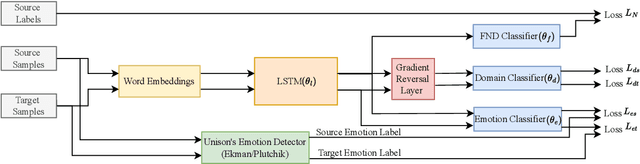

Recent works on fake news detection have shown the efficacy of using emotions as a feature for improved performance. However, the cross-domain impact of emotion-guided features for fake news detection still remains an open problem. In this work, we propose an emotion-guided, domain-adaptive, multi-task approach for cross-domain fake news detection, proving the efficacy of emotion-guided models in cross-domain settings for various datasets.
Emotion-guided Cross-domain Fake News Detection using Adversarial Domain Adaptation
Nov 24, 2022Recent works on fake news detection have shown the efficacy of using emotions as a feature or emotions-based features for improved performance. However, the impact of these emotion-guided features for fake news detection in cross-domain settings, where we face the problem of domain shift, is still largely unexplored. In this work, we evaluate the impact of emotion-guided features for cross-domain fake news detection, and further propose an emotion-guided, domain-adaptive approach using adversarial learning. We prove the efficacy of emotion-guided models in cross-domain settings for various combinations of source and target datasets from FakeNewsAMT, Celeb, Politifact and Gossipcop datasets.
A Spreader Ranking Algorithm for Extremely Low-budget Influence Maximization in Social Networks using Community Bridge Nodes
Nov 17, 2022



In recent years, social networking platforms have gained significant popularity among the masses like connecting with people and propagating ones thoughts and opinions. This has opened the door to user-specific advertisements and recommendations on these platforms, bringing along a significant focus on Influence Maximisation (IM) on social networks due to its wide applicability in target advertising, viral marketing, and personalized recommendations. The aim of IM is to identify certain nodes in the network which can help maximize the spread of certain information through a diffusion cascade. While several works have been proposed for IM, most were inefficient in exploiting community structures to their full extent. In this work, we propose a community structures-based approach, which employs a K-Shell algorithm in order to generate a score for the connections between seed nodes and communities for low-budget scenarios. Further, our approach employs entropy within communities to ensure the proper spread of information within the communities. We choose the Independent Cascade (IC) model to simulate information spread and evaluate it on four evaluation metrics. We validate our proposed approach on eight publicly available networks and find that it significantly outperforms the baseline approaches on these metrics, while still being relatively efficient.
Adaptation of domain-specific transformer models with text oversampling for sentiment analysis of social media posts on Covid-19 vaccines
Sep 22, 2022
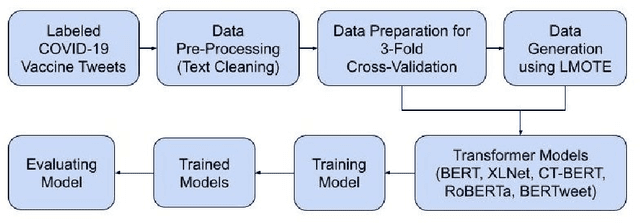


Covid-19 has spread across the world and several vaccines have been developed to counter its surge. To identify the correct sentiments associated with the vaccines from social media posts, we fine-tune various state-of-the-art pre-trained transformer models on tweets associated with Covid-19 vaccines. Specifically, we use the recently introduced state-of-the-art pre-trained transformer models RoBERTa, XLNet and BERT, and the domain-specific transformer models CT-BERT and BERTweet that are pre-trained on Covid-19 tweets. We further explore the option of text augmentation by oversampling using Language Model based Oversampling Technique (LMOTE) to improve the accuracies of these models, specifically, for small sample datasets where there is an imbalanced class distribution among the positive, negative and neutral sentiment classes. Our results summarize our findings on the suitability of text oversampling for imbalanced small sample datasets that are used to fine-tune state-of-the-art pre-trained transformer models, and the utility of domain-specific transformer models for the classification task.