 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAQuA: A Benchmarking Tool for Label Quality Assessment
Jun 15, 2023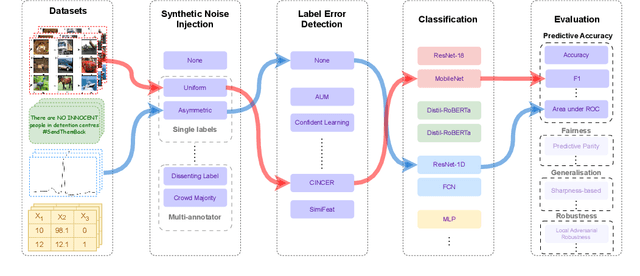
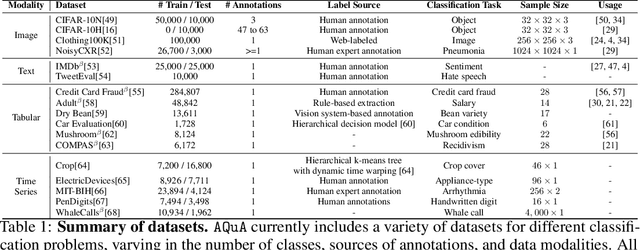
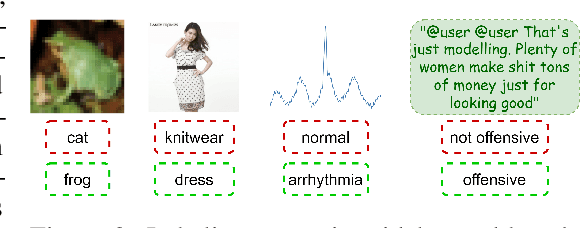
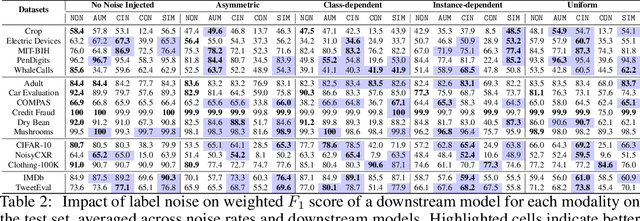
Machine learning (ML) models are only as good as the data they are trained on. But recent studies have found datasets widely used to train and evaluate ML models, e.g. ImageNet, to have pervasive labeling errors. Erroneous labels on the train set hurt ML models' ability to generalize, and they impact evaluation and model selection using the test set. Consequently, learning in the presence of labeling errors is an active area of research, yet this field lacks a comprehensive benchmark to evaluate these methods. Most of these methods are evaluated on a few computer vision datasets with significant variance in the experimental protocols. With such a large pool of methods and inconsistent evaluation, it is also unclear how ML practitioners can choose the right models to assess label quality in their data. To this end, we propose a benchmarking environment AQuA to rigorously evaluate methods that enable machine learning in the presence of label noise. We also introduce a design space to delineate concrete design choices of label error detection models. We hope that our proposed design space and benchmark enable practitioners to choose the right tools to improve their label quality and that our benchmark enables objective and rigorous evaluation of machine learning tools facing mislabeled data.
Fluid Transformers and Creative Analogies: Exploring Large Language Models' Capacity for Augmenting Cross-Domain Analogical Creativity
Feb 27, 2023



Cross-domain analogical reasoning is a core creative ability that can be challenging for humans. Recent work has shown some proofs-of concept of Large language Models' (LLMs) ability to generate cross-domain analogies. However, the reliability and potential usefulness of this capacity for augmenting human creative work has received little systematic exploration. In this paper, we systematically explore LLMs capacity to augment cross-domain analogical reasoning. Across three studies, we found: 1) LLM-generated cross-domain analogies were frequently judged as helpful in the context of a problem reformulation task (median 4 out of 5 helpfulness rating), and frequently (~80% of cases) led to observable changes in problem formulations, and 2) there was an upper bound of 25% of outputs bring rated as potentially harmful, with a majority due to potentially upsetting content, rather than biased or toxic content. These results demonstrate the potential utility -- and risks -- of LLMs for augmenting cross-domain analogical creativity.
Graph Anomaly Detection with Unsupervised GNNs
Oct 20, 2022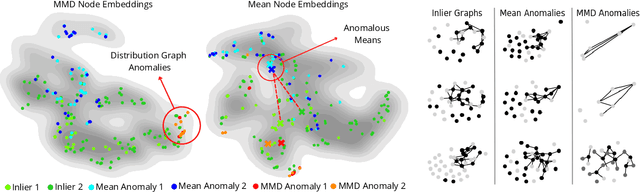
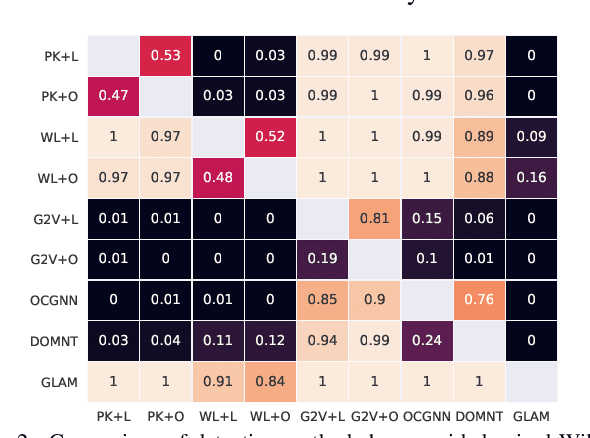
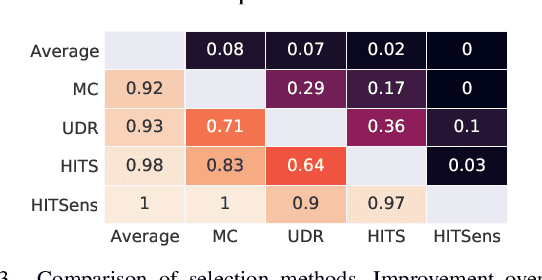

Graph-based anomaly detection finds numerous applications in the real-world. Thus, there exists extensive literature on the topic that has recently shifted toward deep detection models due to advances in deep learning and graph neural networks (GNNs). A vast majority of prior work focuses on detecting node/edge/subgraph anomalies within a single graph, with much less work on graph-level anomaly detection in a graph database. This work aims to fill two gaps in the literature: We (1) design GLAM, an end-to-end graph-level anomaly detection model based on GNNs, and (2) focus on unsupervised model selection, which is notoriously hard due to lack of any labels, yet especially critical for deep NN based models with a long list of hyper-parameters. Further, we propose a new pooling strategy for graph-level embedding, called MMD-pooling, that is geared toward detecting distribution anomalies which has not been considered before. Through extensive experiments on 15 real-world datasets, we show that (i) GLAM outperforms node-level and two-stage (i.e. not end-to-end) baselines, and (ii) model selection picks a significantly more effective model than expectation (i.e. average) -- without using any labels -- among candidates with otherwise large variation in performance.
Graph Based Temporal Aggregation for Video Retrieval
Nov 04, 2020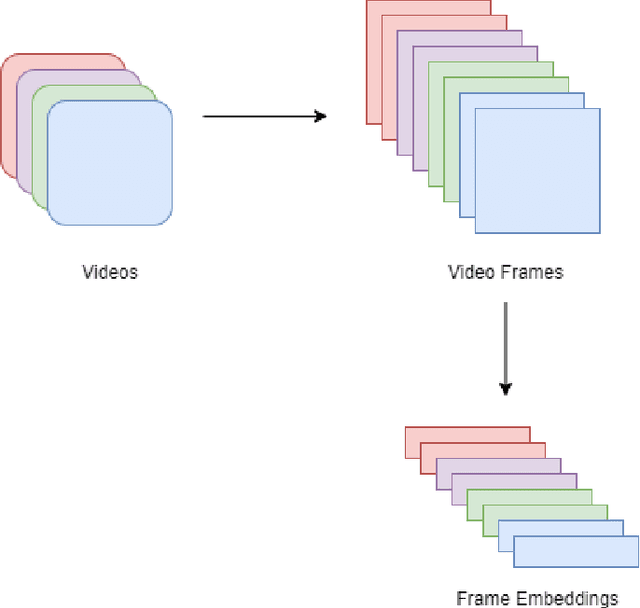
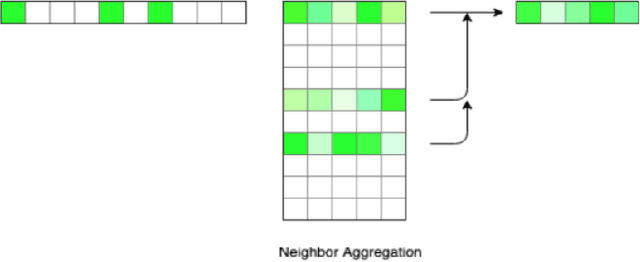
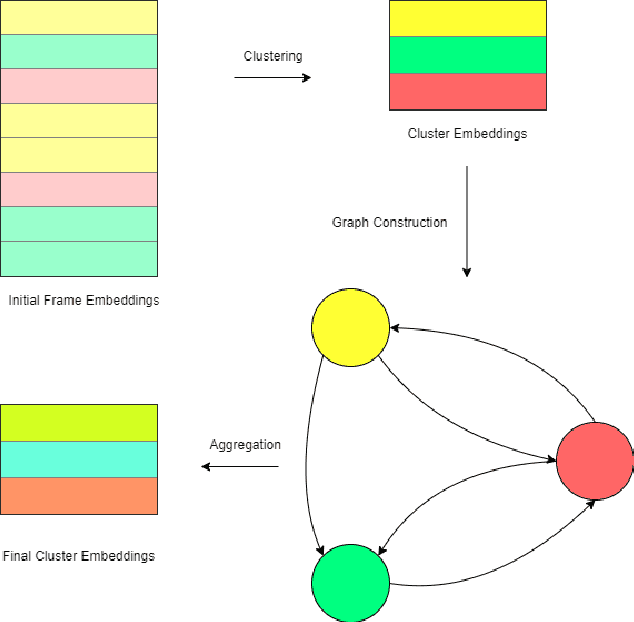
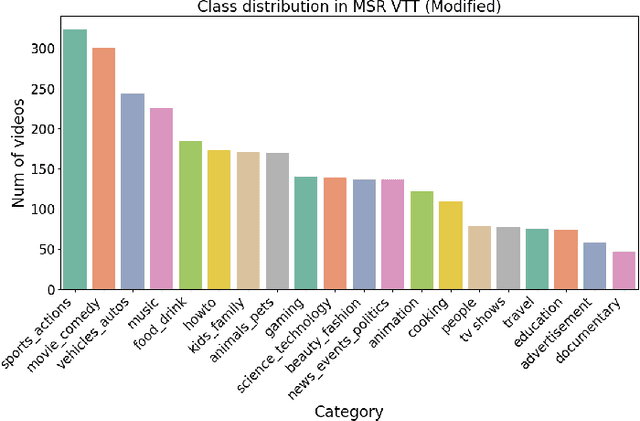
Large scale video retrieval is a field of study with a lot of ongoing research. Most of the work in the field is on video retrieval through text queries using techniques such as VSE++. However, there is little research done on video retrieval through image queries, and the work that has been done in this field either uses image queries from within the video dataset or iterates through videos frame by frame. These approaches are not generalized for queries from outside the dataset and do not scale well for large video datasets. To overcome these issues, we propose a new approach for video retrieval through image queries where an undirected graph is constructed from the combined set of frames from all videos to be searched. The node features of this graph are used in the task of video retrieval. Experimentation is done on the MSR-VTT dataset by using query images from outside the dataset. To evaluate this novel approach P@5, P@10 and P@20 metrics are calculated. Two different ResNet models namely, ResNet-152 and ResNet-50 are used in this study.
Optimization of Image Embeddings for Few Shot Learning
Apr 04, 2020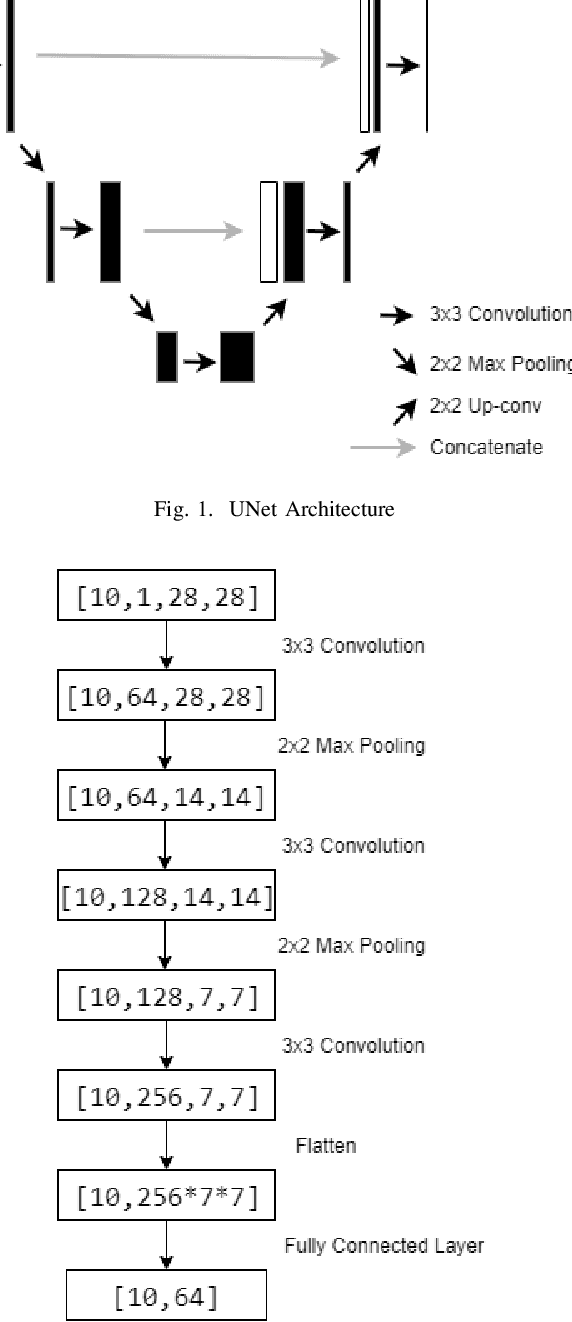
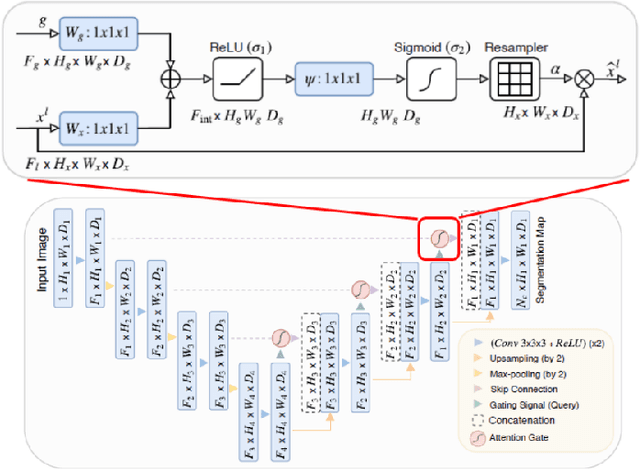
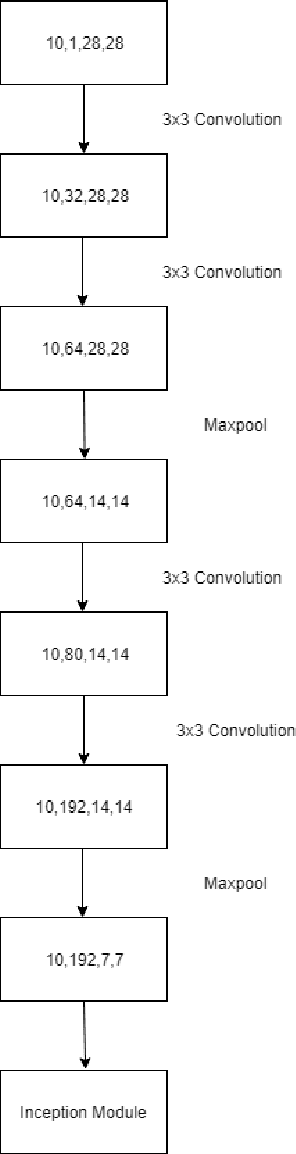
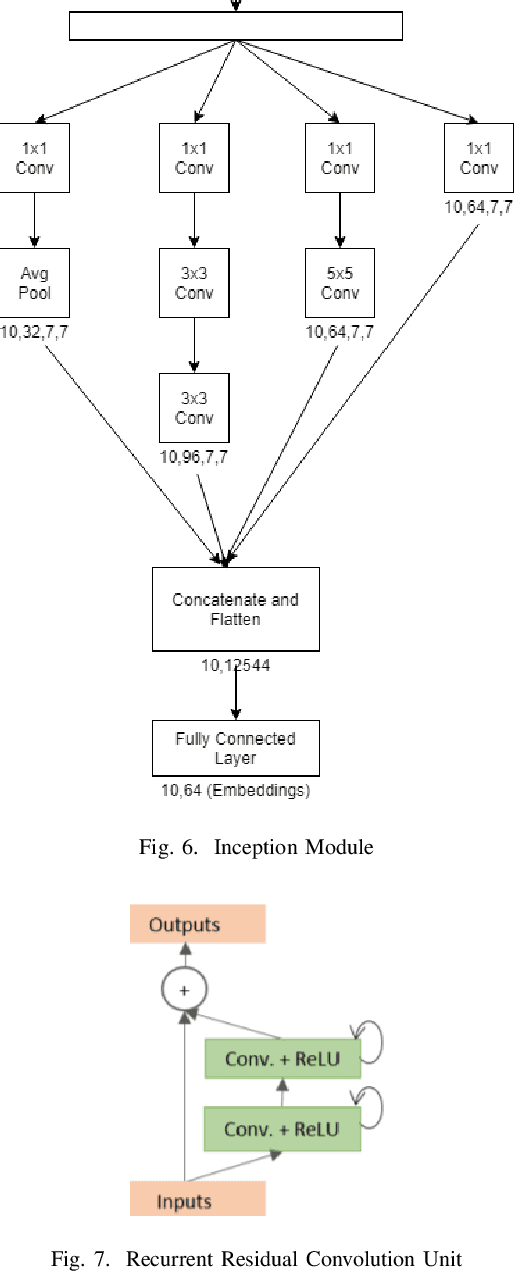
In this paper we improve the image embeddings generated in the graph neural network solution for few shot learning. We propose alternate architectures for existing networks such as Inception-Net, U-Net, Attention U-Net, and Squeeze-Net to generate embeddings and increase the accuracy of the models. We improve the quality of embeddings created at the cost of the time taken to generate them. The proposed implementations outperform the existing state of the art methods for 1-shot and 5-shot learning on the Omniglot dataset. The experiments involved a testing set and training set which had no common classes between them. The results for 5-way and 10-way/20-way tests have been tabulated.