 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpIDER: Spatially Informed Dense Embedding Retrieval for Software Issue Localization
Dec 18, 2025Retrieving code units (e.g., files, classes, functions) that are semantically relevant to a given user query, bug report, or feature request from large codebases is a fundamental challenge for LLM-based coding agents. Agentic approaches typically employ sparse retrieval methods like BM25 or dense embedding strategies to identify relevant units. While embedding-based approaches can outperform BM25 by large margins, they often lack exploration of the codebase and underutilize its underlying graph structure. To address this, we propose SpIDER (Spatially Informed Dense Embedding Retrieval), an enhanced dense retrieval approach that incorporates LLM-based reasoning over auxiliary context obtained through graph-based exploration of the codebase. Empirical results show that SpIDER consistently improves dense retrieval performance across several programming languages.
STAMP: Spatial-Temporal Adapter with Multi-Head Pooling
Nov 13, 2025Time series foundation models (TSFMs) pretrained on data from multiple domains have shown strong performance on diverse modeling tasks. Various efforts have been made to develop foundation models specific to electroencephalography (EEG) data, which records brain electrical activity as time series. However, no comparative analysis of EEG-specific foundation models (EEGFMs) versus general TSFMs has been performed on EEG-specific tasks. We introduce a novel Spatial-Temporal Adapter with Multi-Head Pooling (STAMP), which leverages univariate embeddings produced by a general TSFM, implicitly models spatial-temporal characteristics of EEG data, and achieves performance comparable to state-of-the-art EEGFMs. A comprehensive analysis is performed on 8 benchmark datasets of clinical tasks using EEG for classification, along with ablation studies. Our proposed adapter is lightweight in trainable parameters and flexible in the inputs it can accommodate, supporting easy modeling of EEG data using TSFMs.
TimeSeriesGym: A Scalable Benchmark for (Time Series) Machine Learning Engineering Agents
May 19, 2025We introduce TimeSeriesGym, a scalable benchmarking framework for evaluating Artificial Intelligence (AI) agents on time series machine learning engineering challenges. Existing benchmarks lack scalability, focus narrowly on model building in well-defined settings, and evaluate only a limited set of research artifacts (e.g., CSV submission files). To make AI agent benchmarking more relevant to the practice of machine learning engineering, our framework scales along two critical dimensions. First, recognizing that effective ML engineering requires a range of diverse skills, TimeSeriesGym incorporates challenges from diverse sources spanning multiple domains and tasks. We design challenges to evaluate both isolated capabilities (including data handling, understanding research repositories, and code translation) and their combinations, and rather than addressing each challenge independently, we develop tools that support designing multiple challenges at scale. Second, we implement evaluation mechanisms for multiple research artifacts, including submission files, code, and models, using both precise numeric measures and more flexible LLM-based evaluation approaches. This dual strategy balances objective assessment with contextual judgment. Although our initial focus is on time series applications, our framework can be readily extended to other data modalities, broadly enhancing the comprehensiveness and practical utility of agentic AI evaluation. We open-source our benchmarking framework to facilitate future research on the ML engineering capabilities of AI agents.
Investigating Compositional Reasoning in Time Series Foundation Models
Feb 09, 2025



Large pre-trained time series foundation models (TSFMs) have demonstrated promising zero-shot performance across a wide range of domains. However, a question remains: Do TSFMs succeed solely by memorizing training patterns, or do they possess the ability to reason? While reasoning is a topic of great interest in the study of Large Language Models (LLMs), it is undefined and largely unexplored in the context of TSFMs. In this work, inspired by language modeling literature, we formally define compositional reasoning in forecasting and distinguish it from in-distribution generalization. We evaluate the reasoning and generalization capabilities of 23 popular deep learning forecasting models on multiple synthetic and real-world datasets. Additionally, through controlled studies, we systematically examine which design choices in TSFMs contribute to improved reasoning abilities. Our study yields key insights into the impact of TSFM architecture design on compositional reasoning and generalization. We find that patch-based Transformers have the best reasoning performance, closely followed by residualized MLP-based architectures, which are 97\% less computationally complex in terms of FLOPs and 86\% smaller in terms of the number of trainable parameters. Interestingly, in some zero-shot out-of-distribution scenarios, these models can outperform moving average and exponential smoothing statistical baselines trained on in-distribution data. Only a few design choices, such as the tokenization method, had a significant (negative) impact on Transformer model performance.
TimeSeriesExam: A time series understanding exam
Oct 18, 2024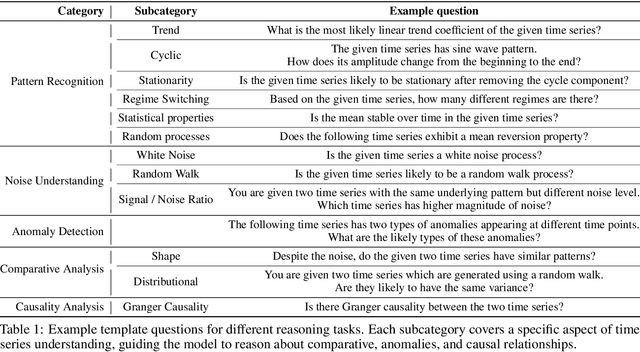
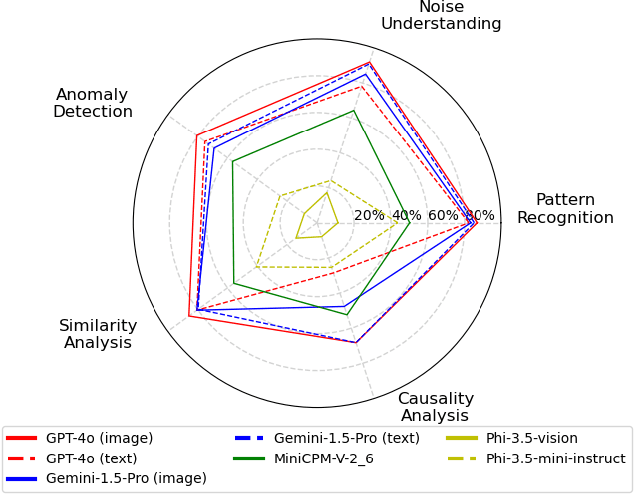
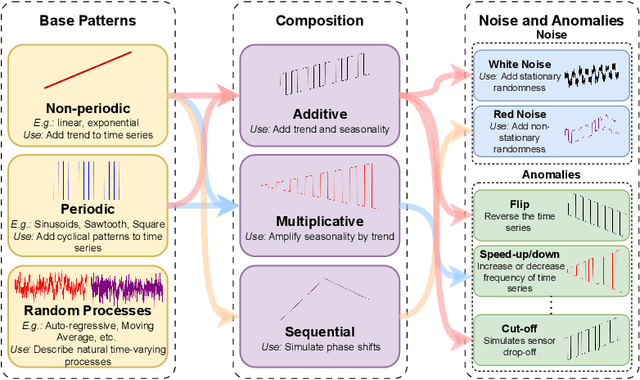
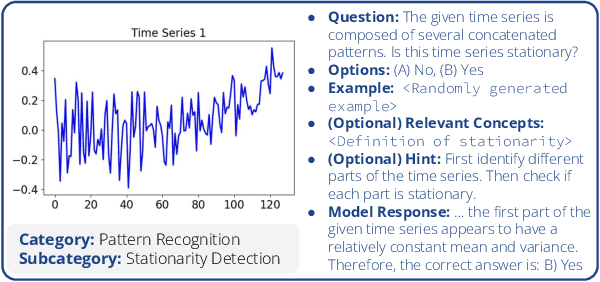
Large Language Models (LLMs) have recently demonstrated a remarkable ability to model time series data. These capabilities can be partly explained if LLMs understand basic time series concepts. However, our knowledge of what these models understand about time series data remains relatively limited. To address this gap, we introduce TimeSeriesExam, a configurable and scalable multiple-choice question exam designed to assess LLMs across five core time series understanding categories: pattern recognition, noise understanding, similarity analysis, anomaly detection, and causality analysis. TimeSeriesExam comprises of over 700 questions, procedurally generated using 104 carefully curated templates and iteratively refined to balance difficulty and their ability to discriminate good from bad models. We test 7 state-of-the-art LLMs on the TimeSeriesExam and provide the first comprehensive evaluation of their time series understanding abilities. Our results suggest that closed-source models such as GPT-4 and Gemini understand simple time series concepts significantly better than their open-source counterparts, while all models struggle with complex concepts such as causality analysis. We believe that the ability to programatically generate questions is fundamental to assessing and improving LLM's ability to understand and reason about time series data.
Implicit Reasoning in Deep Time Series Forecasting
Sep 18, 2024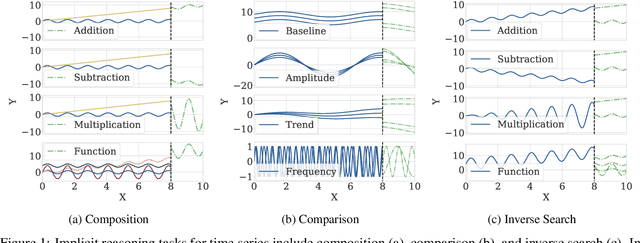

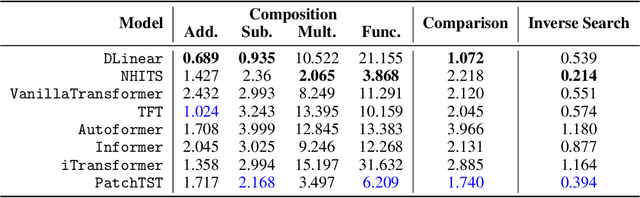
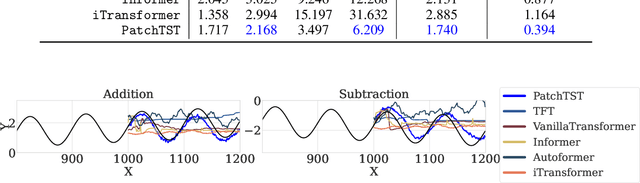
Recently, time series foundation models have shown promising zero-shot forecasting performance on time series from a wide range of domains. However, it remains unclear whether their success stems from a true understanding of temporal dynamics or simply from memorizing the training data. While implicit reasoning in language models has been studied, similar evaluations for time series models have been largely unexplored. This work takes an initial step toward assessing the reasoning abilities of deep time series forecasting models. We find that certain linear, MLP-based, and patch-based Transformer models generalize effectively in systematically orchestrated out-of-distribution scenarios, suggesting underexplored reasoning capabilities beyond simple pattern memorization.
MOMENT: A Family of Open Time-series Foundation Models
Feb 06, 2024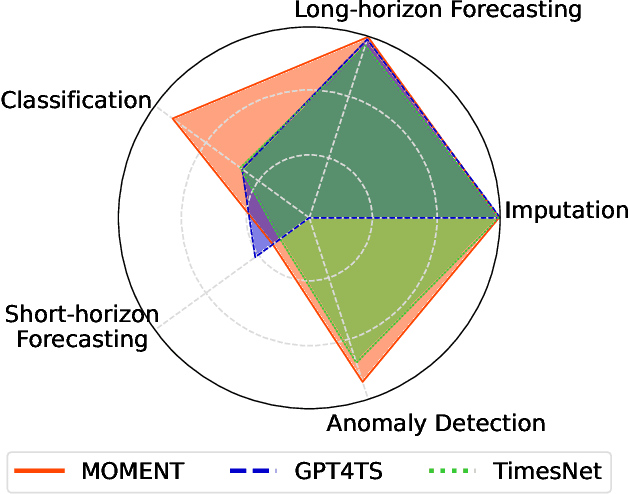
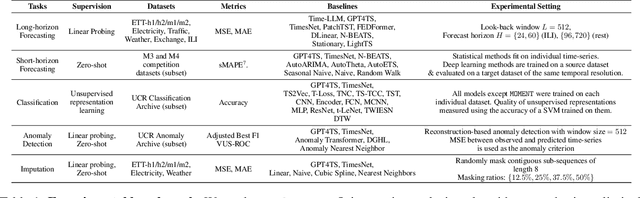
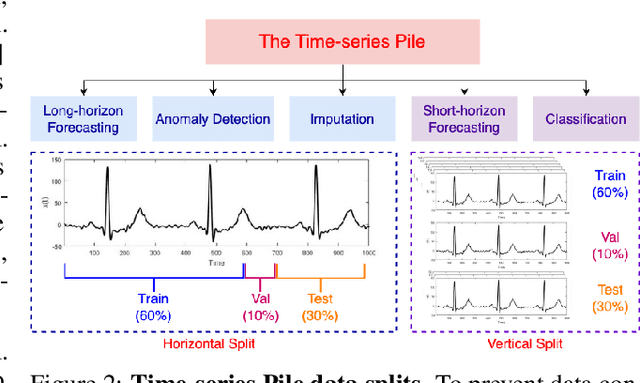
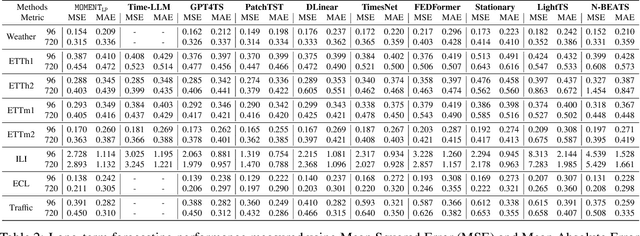
We introduce MOMENT, a family of open-source foundation models for general-purpose time-series analysis. Pre-training large models on time-series data is challenging due to (1) the absence of a large and cohesive public time-series repository, and (2) diverse time-series characteristics which make multi-dataset training onerous. Additionally, (3) experimental benchmarks to evaluate these models, especially in scenarios with limited resources, time, and supervision, are still in their nascent stages. To address these challenges, we compile a large and diverse collection of public time-series, called the Time-series Pile, and systematically tackle time-series-specific challenges to unlock large-scale multi-dataset pre-training. Finally, we build on recent work to design a benchmark to evaluate time-series foundation models on diverse tasks and datasets in limited supervision settings. Experiments on this benchmark demonstrate the effectiveness of our pre-trained models with minimal data and task-specific fine-tuning. Finally, we present several interesting empirical observations about large pre-trained time-series models. Our code is available anonymously at anonymous.4open.science/r/BETT-773F/.
AQuA: A Benchmarking Tool for Label Quality Assessment
Jun 15, 2023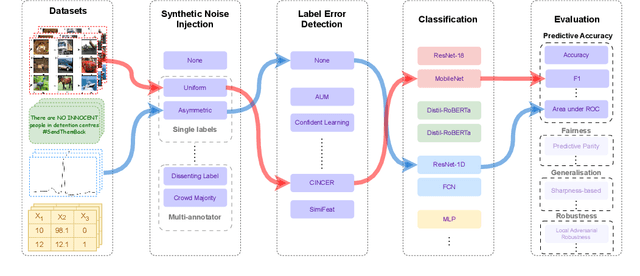
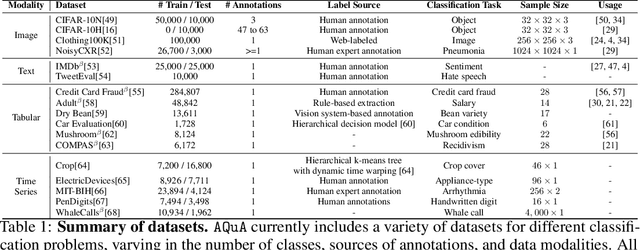
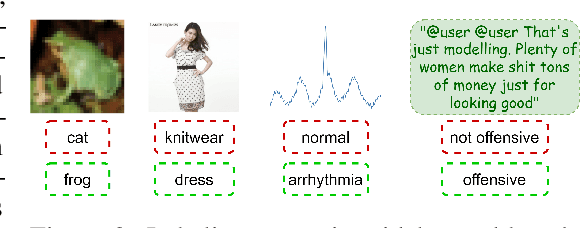
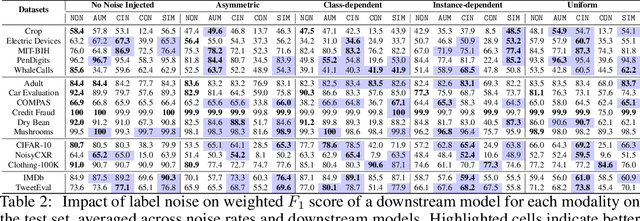
Machine learning (ML) models are only as good as the data they are trained on. But recent studies have found datasets widely used to train and evaluate ML models, e.g. ImageNet, to have pervasive labeling errors. Erroneous labels on the train set hurt ML models' ability to generalize, and they impact evaluation and model selection using the test set. Consequently, learning in the presence of labeling errors is an active area of research, yet this field lacks a comprehensive benchmark to evaluate these methods. Most of these methods are evaluated on a few computer vision datasets with significant variance in the experimental protocols. With such a large pool of methods and inconsistent evaluation, it is also unclear how ML practitioners can choose the right models to assess label quality in their data. To this end, we propose a benchmarking environment AQuA to rigorously evaluate methods that enable machine learning in the presence of label noise. We also introduce a design space to delineate concrete design choices of label error detection models. We hope that our proposed design space and benchmark enable practitioners to choose the right tools to improve their label quality and that our benchmark enables objective and rigorous evaluation of machine learning tools facing mislabeled data.
Unsupervised Model Selection for Time-series Anomaly Detection
Oct 03, 2022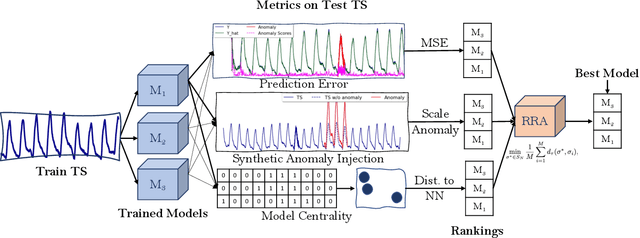
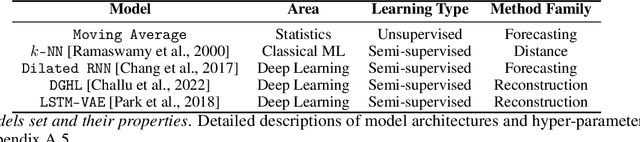
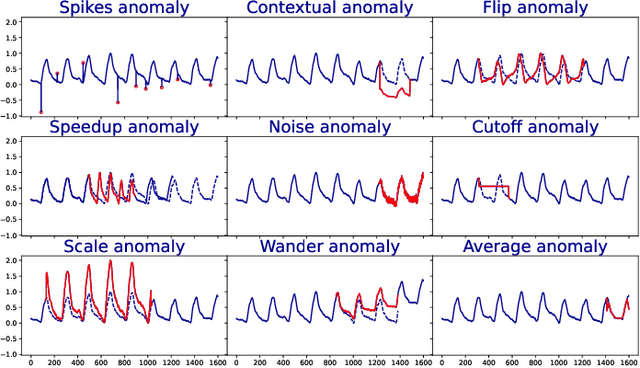
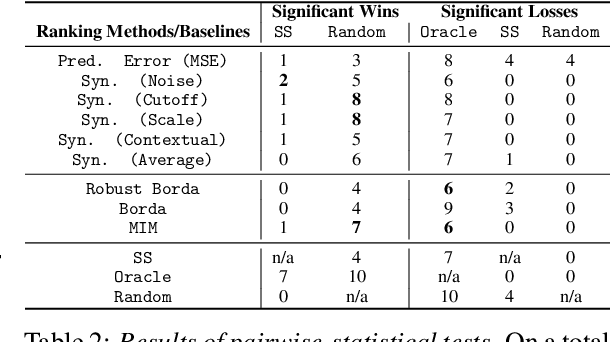
Anomaly detection in time-series has a wide range of practical applications. While numerous anomaly detection methods have been proposed in the literature, a recent survey concluded that no single method is the most accurate across various datasets. To make matters worse, anomaly labels are scarce and rarely available in practice. The practical problem of selecting the most accurate model for a given dataset without labels has received little attention in the literature. This paper answers this question i.e. Given an unlabeled dataset and a set of candidate anomaly detectors, how can we select the most accurate model? To this end, we identify three classes of surrogate (unsupervised) metrics, namely, prediction error, model centrality, and performance on injected synthetic anomalies, and show that some metrics are highly correlated with standard supervised anomaly detection performance metrics such as the $F_1$ score, but to varying degrees. We formulate metric combination with multiple imperfect surrogate metrics as a robust rank aggregation problem. We then provide theoretical justification behind the proposed approach. Large-scale experiments on multiple real-world datasets demonstrate that our proposed unsupervised approach is as effective as selecting the most accurate model based on partially labeled data.
Classifying Unstructured Clinical Notes via Automatic Weak Supervision
Jun 24, 2022

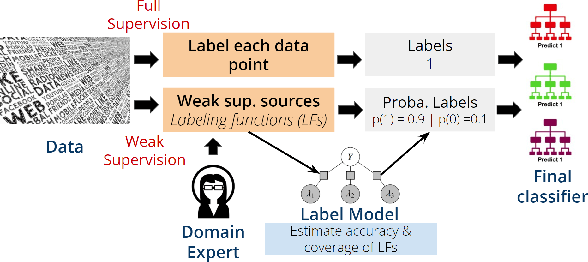

Healthcare providers usually record detailed notes of the clinical care delivered to each patient for clinical, research, and billing purposes. Due to the unstructured nature of these narratives, providers employ dedicated staff to assign diagnostic codes to patients' diagnoses using the International Classification of Diseases (ICD) coding system. This manual process is not only time-consuming but also costly and error-prone. Prior work demonstrated potential utility of Machine Learning (ML) methodology in automating this process, but it has relied on large quantities of manually labeled data to train the models. Additionally, diagnostic coding systems evolve with time, which makes traditional supervised learning strategies unable to generalize beyond local applications. In this work, we introduce a general weakly-supervised text classification framework that learns from class-label descriptions only, without the need to use any human-labeled documents. It leverages the linguistic domain knowledge stored within pre-trained language models and the data programming framework to assign code labels to individual texts. We demonstrate the efficacy and flexibility of our method by comparing it to state-of-the-art weak text classifiers across four real-world text classification datasets, in addition to assigning ICD codes to medical notes in the publicly available MIMIC-III database.