 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Missing: Variable-Aware Representation Learning for Irregular EHR Time Series using Large Language Models
Sep 26, 2025

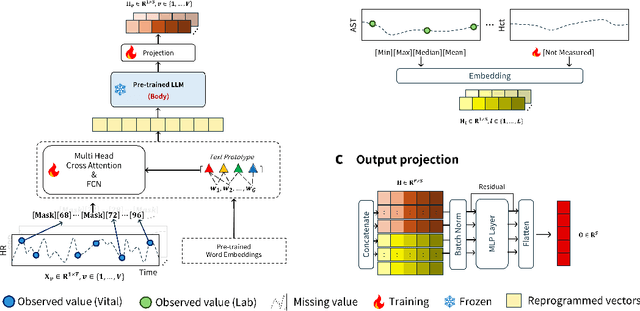

Irregular sampling and high missingness are intrinsic challenges in modeling time series derived from electronic health records (EHRs),where clinical variables are measured at uneven intervals depending on workflow and intervention timing. To address this, we propose VITAL, a variable-aware, large language model (LLM) based framework tailored for learning from irregularly sampled physiological time series. VITAL differentiates between two distinct types of clinical variables: vital signs, which are frequently recorded and exhibit temporal patterns, and laboratory tests, which are measured sporadically and lack temporal structure. It reprograms vital signs into the language space, enabling the LLM to capture temporal context and reason over missing values through explicit encoding. In contrast, laboratory variables are embedded either using representative summary values or a learnable [Not measured] token, depending on their availability. Extensive evaluations on the benchmark datasets from the PhysioNet demonstrate that VITAL outperforms state of the art methods designed for irregular time series. Furthermore, it maintains robust performance under high levels of missingness, which is prevalent in real world clinical scenarios where key variables are often unavailable.
Simplifying Multimodality: Unimodal Approach to Multimodal Challenges in Radiology with General-Domain Large Language Model
Apr 29, 2024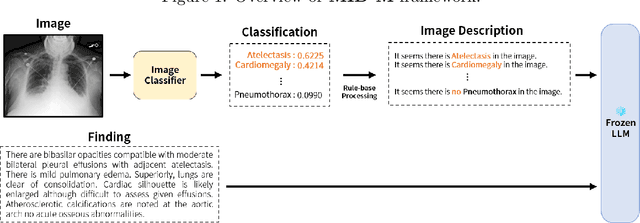

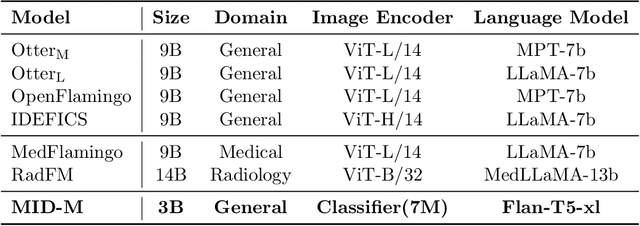
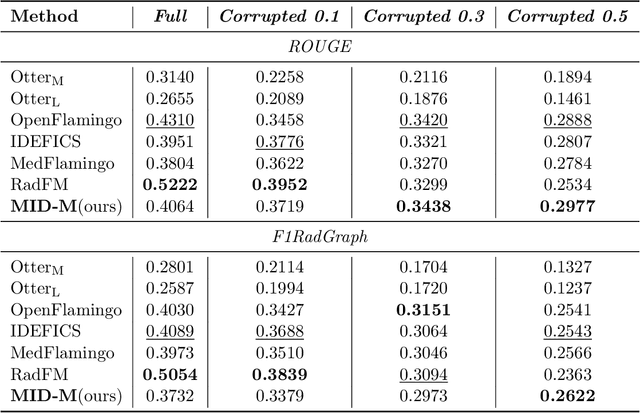
Recent advancements in Large Multimodal Models (LMMs) have attracted interest in their generalization capability with only a few samples in the prompt. This progress is particularly relevant to the medical domain, where the quality and sensitivity of data pose unique challenges for model training and application. However, the dependency on high-quality data for effective in-context learning raises questions about the feasibility of these models when encountering with the inevitable variations and errors inherent in real-world medical data. In this paper, we introduce MID-M, a novel framework that leverages the in-context learning capabilities of a general-domain Large Language Model (LLM) to process multimodal data via image descriptions. MID-M achieves a comparable or superior performance to task-specific fine-tuned LMMs and other general-domain ones, without the extensive domain-specific training or pre-training on multimodal data, with significantly fewer parameters. This highlights the potential of leveraging general-domain LLMs for domain-specific tasks and offers a sustainable and cost-effective alternative to traditional LMM developments. Moreover, the robustness of MID-M against data quality issues demonstrates its practical utility in real-world medical domain applications.
Evaluation of General Large Language Models in Contextually Assessing Semantic Concepts Extracted from Adult Critical Care Electronic Health Record Notes
Jan 24, 2024The field of healthcare has increasingly turned its focus towards Large Language Models (LLMs) due to their remarkable performance. However, their performance in actual clinical applications has been underexplored. Traditional evaluations based on question-answering tasks don't fully capture the nuanced contexts. This gap highlights the need for more in-depth and practical assessments of LLMs in real-world healthcare settings. Objective: We sought to evaluate the performance of LLMs in the complex clinical context of adult critical care medicine using systematic and comprehensible analytic methods, including clinician annotation and adjudication. Methods: We investigated the performance of three general LLMs in understanding and processing real-world clinical notes. Concepts from 150 clinical notes were identified by MetaMap and then labeled by 9 clinicians. Each LLM's proficiency was evaluated by identifying the temporality and negation of these concepts using different prompts for an in-depth analysis. Results: GPT-4 showed overall superior performance compared to other LLMs. In contrast, both GPT-3.5 and text-davinci-003 exhibit enhanced performance when the appropriate prompting strategies are employed. The GPT family models have demonstrated considerable efficiency, evidenced by their cost-effectiveness and time-saving capabilities. Conclusion: A comprehensive qualitative performance evaluation framework for LLMs is developed and operationalized. This framework goes beyond singular performance aspects. With expert annotations, this methodology not only validates LLMs' capabilities in processing complex medical data but also establishes a benchmark for future LLM evaluations across specialized domains.
Weakly Supervised Classification of Vital Sign Alerts as Real or Artifact
Jun 18, 2022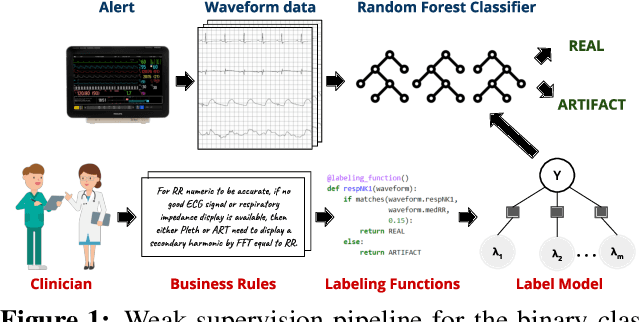


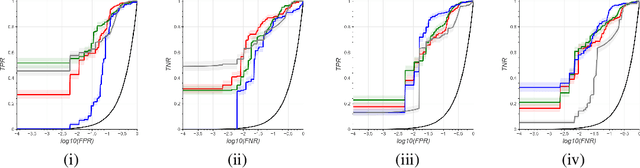
A significant proportion of clinical physiologic monitoring alarms are false. This often leads to alarm fatigue in clinical personnel, inevitably compromising patient safety. To combat this issue, researchers have attempted to build Machine Learning (ML) models capable of accurately adjudicating Vital Sign (VS) alerts raised at the bedside of hemodynamically monitored patients as real or artifact. Previous studies have utilized supervised ML techniques that require substantial amounts of hand-labeled data. However, manually harvesting such data can be costly, time-consuming, and mundane, and is a key factor limiting the widespread adoption of ML in healthcare (HC). Instead, we explore the use of multiple, individually imperfect heuristics to automatically assign probabilistic labels to unlabeled training data using weak supervision. Our weakly supervised models perform competitively with traditional supervised techniques and require less involvement from domain experts, demonstrating their use as efficient and practical alternatives to supervised learning in HC applications of ML.