 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Multimodality: Unimodal Approach to Multimodal Challenges in Radiology with General-Domain Large Language Model
Paper and Code
Apr 29, 2024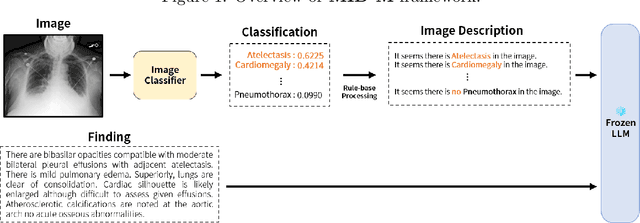

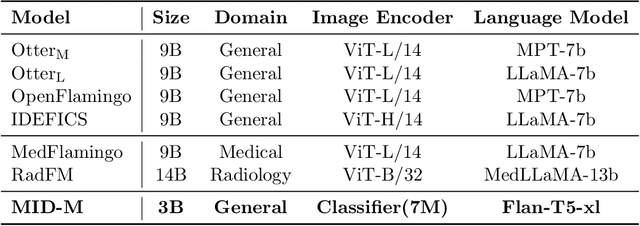
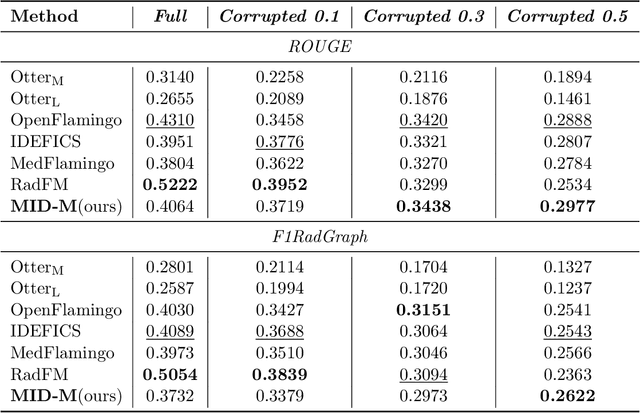
Recent advancements in Large Multimodal Models (LMMs) have attracted interest in their generalization capability with only a few samples in the prompt. This progress is particularly relevant to the medical domain, where the quality and sensitivity of data pose unique challenges for model training and application. However, the dependency on high-quality data for effective in-context learning raises questions about the feasibility of these models when encountering with the inevitable variations and errors inherent in real-world medical data. In this paper, we introduce MID-M, a novel framework that leverages the in-context learning capabilities of a general-domain Large Language Model (LLM) to process multimodal data via image descriptions. MID-M achieves a comparable or superior performance to task-specific fine-tuned LMMs and other general-domain ones, without the extensive domain-specific training or pre-training on multimodal data, with significantly fewer parameters. This highlights the potential of leveraging general-domain LLMs for domain-specific tasks and offers a sustainable and cost-effective alternative to traditional LMM developments. Moreover, the robustness of MID-M against data quality issues demonstrates its practical utility in real-world medical domain applications.