 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHR-SeqSQL : A Sequential Text-to-SQL Dataset For Interactively Exploring Electronic Health Records
May 23, 2024In this paper, we introduce EHR-SeqSQL, a novel sequential text-to-SQL dataset for Electronic Health Record (EHR) databases. EHR-SeqSQL is designed to address critical yet underexplored aspects in text-to-SQL parsing: interactivity, compositionality, and efficiency. To the best of our knowledge, EHR-SeqSQL is not only the largest but also the first medical text-to-SQL dataset benchmark to include sequential and contextual questions. We provide a data split and the new test set designed to assess compositional generalization ability. Our experiments demonstrate the superiority of a multi-turn approach over a single-turn approach in learning compositionality. Additionally, our dataset integrates specially crafted tokens into SQL queries to improve execution efficiency. With EHR-SeqSQL, we aim to bridge the gap between practical needs and academic research in the text-to-SQL domain.
Simplifying Multimodality: Unimodal Approach to Multimodal Challenges in Radiology with General-Domain Large Language Model
Apr 29, 2024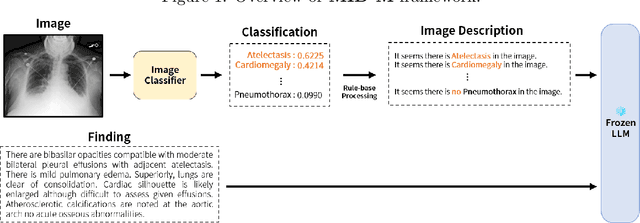

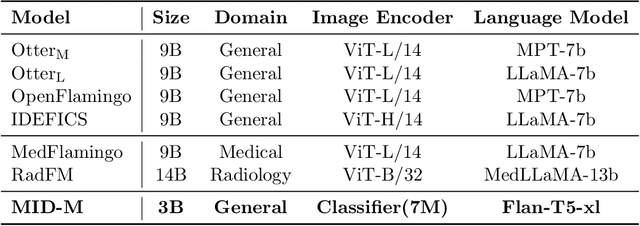
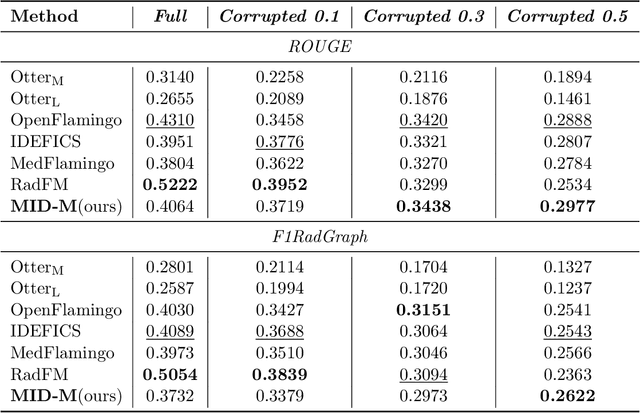
Recent advancements in Large Multimodal Models (LMMs) have attracted interest in their generalization capability with only a few samples in the prompt. This progress is particularly relevant to the medical domain, where the quality and sensitivity of data pose unique challenges for model training and application. However, the dependency on high-quality data for effective in-context learning raises questions about the feasibility of these models when encountering with the inevitable variations and errors inherent in real-world medical data. In this paper, we introduce MID-M, a novel framework that leverages the in-context learning capabilities of a general-domain Large Language Model (LLM) to process multimodal data via image descriptions. MID-M achieves a comparable or superior performance to task-specific fine-tuned LMMs and other general-domain ones, without the extensive domain-specific training or pre-training on multimodal data, with significantly fewer parameters. This highlights the potential of leveraging general-domain LLMs for domain-specific tasks and offers a sustainable and cost-effective alternative to traditional LMM developments. Moreover, the robustness of MID-M against data quality issues demonstrates its practical utility in real-world medical domain applications.
TrustSQL: A Reliability Benchmark for Text-to-SQL Models with Diverse Unanswerable Questions
Mar 23, 2024Recent advances in large language models (LLMs) have led to significant improvements in translating natural language questions into SQL queries. While achieving high accuracy in SQL generation is crucial, little is known about the extent to which these text-to-SQL models can reliably handle diverse types of questions encountered during real-world deployment, including unanswerable ones. To explore this aspect, we present TrustSQL, a new benchmark designed to assess the reliability of text-to-SQL models in both single-database and cross-database settings. The benchmark tasks models with providing one of two outcomes: 1) SQL prediction; or 2) abstention from making a prediction, either when there is a potential error in the generated SQL or when faced with unanswerable questions. For model evaluation, we explore various modeling approaches specifically designed for this task. These include: 1) optimizing separate models for answerability detection, SQL generation, and error detection, which are then integrated into a single pipeline; and 2) developing a unified approach that optimizes a single model to address the proposed task. Experimental results using our new reliability score show that addressing this challenge involves many different areas of research and opens new avenues for model development. Nonetheless, none of the methods surpass the reliability performance of the naive baseline, which abstains from answering all questions.
Open-WikiTable: Dataset for Open Domain Question Answering with Complex Reasoning over Table
May 12, 2023
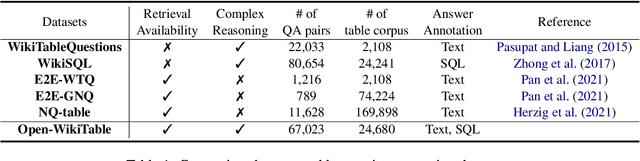


Despite recent interest in open domain question answering (ODQA) over tables, many studies still rely on datasets that are not truly optimal for the task with respect to utilizing structural nature of table. These datasets assume answers reside as a single cell value and do not necessitate exploring over multiple cells such as aggregation, comparison, and sorting. Thus, we release Open-WikiTable, the first ODQA dataset that requires complex reasoning over tables. Open-WikiTable is built upon WikiSQL and WikiTableQuestions to be applicable in the open-domain setting. As each question is coupled with both textual answers and SQL queries, Open-WikiTable opens up a wide range of possibilities for future research, as both reader and parser methods can be applied. The dataset and code are publicly available.