 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHFGaussian: Learning Generalizable Gaussian Human with Integrated Human Features
Nov 05, 2024



Recent advancements in radiance field rendering show promising results in 3D scene representation, where Gaussian splatting-based techniques emerge as state-of-the-art due to their quality and efficiency. Gaussian splatting is widely used for various applications, including 3D human representation. However, previous 3D Gaussian splatting methods either use parametric body models as additional information or fail to provide any underlying structure, like human biomechanical features, which are essential for different applications. In this paper, we present a novel approach called HFGaussian that can estimate novel views and human features, such as the 3D skeleton, 3D key points, and dense pose, from sparse input images in real time at 25 FPS. The proposed method leverages generalizable Gaussian splatting technique to represent the human subject and its associated features, enabling efficient and generalizable reconstruction. By incorporating a pose regression network and the feature splatting technique with Gaussian splatting, HFGaussian demonstrates improved capabilities over existing 3D human methods, showcasing the potential of 3D human representations with integrated biomechanics. We thoroughly evaluate our HFGaussian method against the latest state-of-the-art techniques in human Gaussian splatting and pose estimation, demonstrating its real-time, state-of-the-art performance.
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Apr 09, 2024



Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields
Apr 09, 2024In recent advancements in novel view synthesis, generalizable Neural Radiance Fields (NeRF) based methods applied to human subjects have shown remarkable results in generating novel views from few images. However, this generalization ability cannot capture the underlying structural features of the skeleton shared across all instances. Building upon this, we introduce HFNeRF: a novel generalizable human feature NeRF aimed at generating human biomechanic features using a pre-trained image encoder. While previous human NeRF methods have shown promising results in the generation of photorealistic virtual avatars, such methods lack underlying human structure or biomechanic features such as skeleton or joint information that are crucial for downstream applications including Augmented Reality (AR)/Virtual Reality (VR). HFNeRF leverages 2D pre-trained foundation models toward learning human features in 3D using neural rendering, and then volume rendering towards generating 2D feature maps. We evaluate HFNeRF in the skeleton estimation task by predicting heatmaps as features. The proposed method is fully differentiable, allowing to successfully learn color, geometry, and human skeleton in a simultaneous manner. This paper presents preliminary results of HFNeRF, illustrating its potential in generating realistic virtual avatars with biomechanic features using NeRF.
DiVA-360: The Dynamic Visuo-Audio Dataset for Immersive Neural Fields
Jul 31, 2023
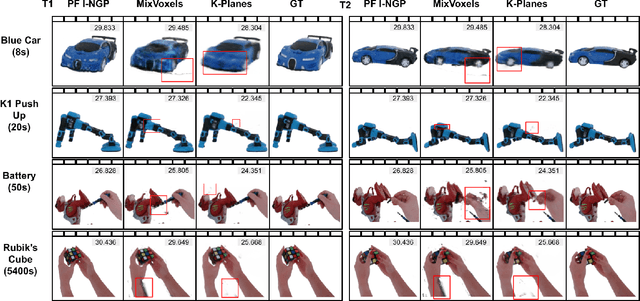
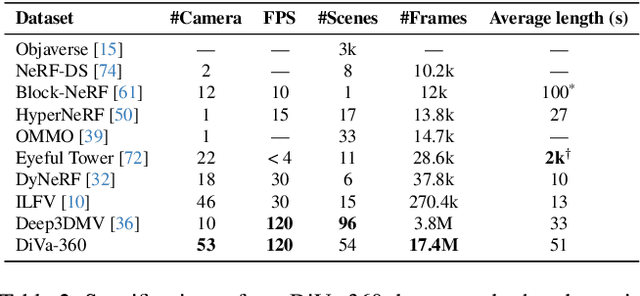

Advances in neural fields are enabling high-fidelity capture of the shape and appearance of static and dynamic scenes. However, their capabilities lag behind those offered by representations such as pixels or meshes due to algorithmic challenges and the lack of large-scale real-world datasets. We address the dataset limitation with DiVA-360, a real-world 360 dynamic visual-audio dataset with synchronized multimodal visual, audio, and textual information about table-scale scenes. It contains 46 dynamic scenes, 30 static scenes, and 95 static objects spanning 11 categories captured using a new hardware system using 53 RGB cameras at 120 FPS and 6 microphones for a total of 8.6M image frames and 1360 s of dynamic data. We provide detailed text descriptions for all scenes, foreground-background segmentation masks, category-specific 3D pose alignment for static objects, as well as metrics for comparison. Our data, hardware and software, and code are available at https://diva360.github.io/.
PNeRF: Probabilistic Neural Scene Representations for Uncertain 3D Visual Mapping
Sep 23, 2022
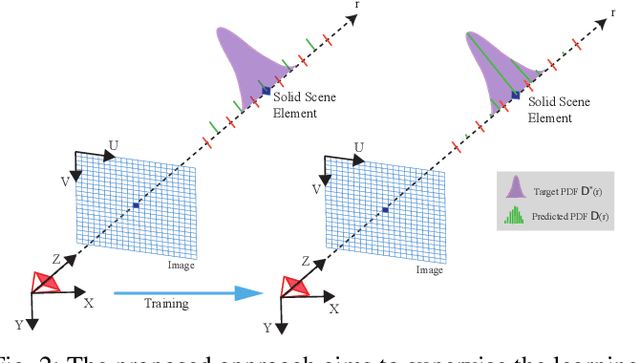
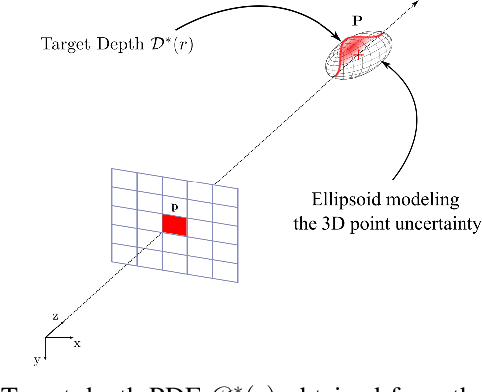
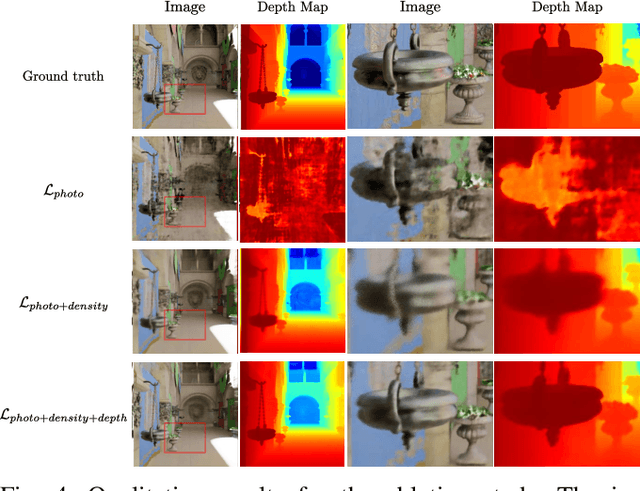
Recently neural scene representations have provided very impressive results for representing 3D scenes visually, however, their study and progress have mainly been limited to visualization of virtual models in computer graphics or scene reconstruction in computer vision without explicitly accounting for sensor and pose uncertainty. Using this novel scene representation in robotics applications, however, would require accounting for this uncertainty in the neural map. The aim of this paper is therefore to propose a novel method for training {\em probabilistic neural scene representations} with uncertain training data that could enable the inclusion of these representations in robotics applications. Acquiring images using cameras or depth sensors contains inherent uncertainty, and furthermore, the camera poses used for learning a 3D model are also imperfect. If these measurements are used for training without accounting for their uncertainty, then the resulting models are non-optimal, and the resulting scene representations are likely to contain artifacts such as blur and un-even geometry. In this work, the problem of uncertainty integration to the learning process is investigated by focusing on training with uncertain information in a probabilistic manner. The proposed method involves explicitly augmenting the training likelihood with an uncertainty term such that the learnt probability distribution of the network is minimized with respect to the training uncertainty. It will be shown that this leads to more accurate image rendering quality, in addition to more precise and consistent geometry. Validation has been carried out on both synthetic and real datasets showing that the proposed approach outperforms state-of-the-art methods. The results show notably that the proposed method is capable of rendering novel high-quality views even when the training data is limited.
Weakly Supervised Classification of Vital Sign Alerts as Real or Artifact
Jun 18, 2022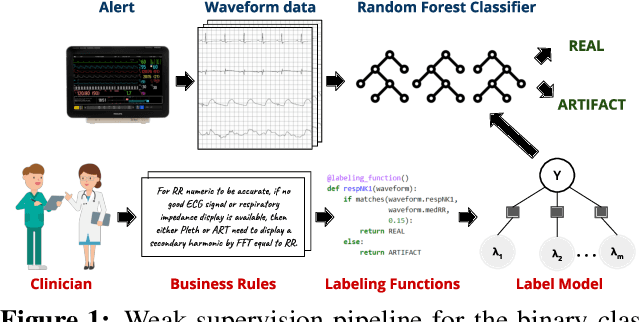


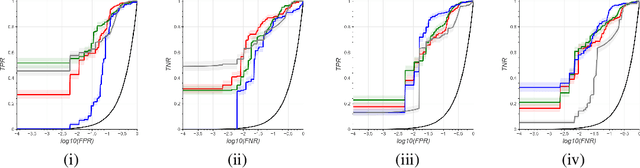
A significant proportion of clinical physiologic monitoring alarms are false. This often leads to alarm fatigue in clinical personnel, inevitably compromising patient safety. To combat this issue, researchers have attempted to build Machine Learning (ML) models capable of accurately adjudicating Vital Sign (VS) alerts raised at the bedside of hemodynamically monitored patients as real or artifact. Previous studies have utilized supervised ML techniques that require substantial amounts of hand-labeled data. However, manually harvesting such data can be costly, time-consuming, and mundane, and is a key factor limiting the widespread adoption of ML in healthcare (HC). Instead, we explore the use of multiple, individually imperfect heuristics to automatically assign probabilistic labels to unlabeled training data using weak supervision. Our weakly supervised models perform competitively with traditional supervised techniques and require less involvement from domain experts, demonstrating their use as efficient and practical alternatives to supervised learning in HC applications of ML.
Mip-NeRF RGB-D: Depth Assisted Fast Neural Radiance Fields
May 19, 2022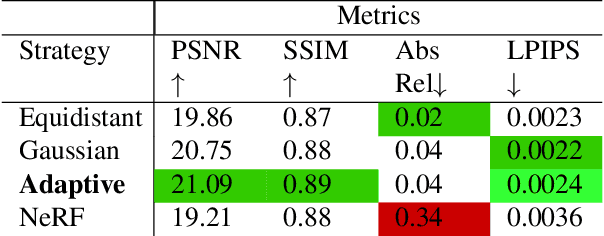
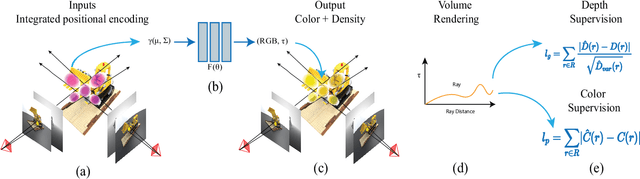
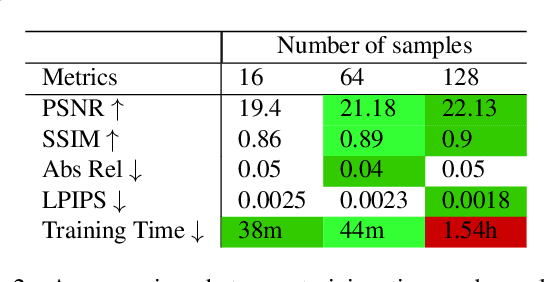
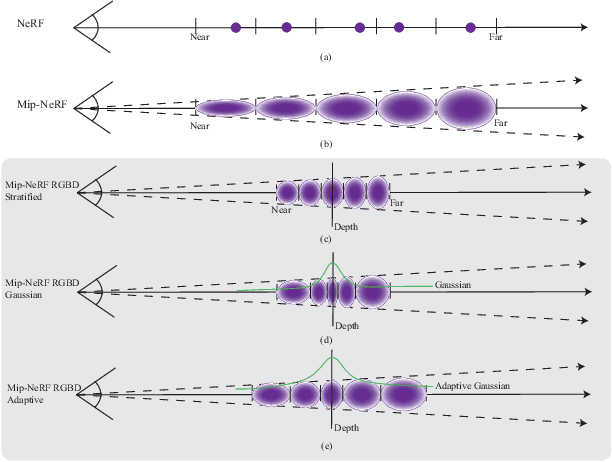
Neural scene representations, such as neural radiance fields (NeRF), are based on training a multilayer perceptron (MLP) using a set of color images with known poses. An increasing number of devices now produce RGB-D information, which has been shown to be very important for a wide range of tasks. Therefore, the aim of this paper is to investigate what improvements can be made to these promising implicit representations by incorporating depth information with the color images. In particular, the recently proposed Mip-NeRF approach, which uses conical frustums instead of rays for volume rendering, allows one to account for the varying area of a pixel with distance from the camera center. The proposed method additionally models depth uncertainty. This allows to address major limitations of NeRF-based approaches including improving the accuracy of geometry, reduced artifacts, faster training time, and shortened prediction time. Experiments are performed on well-known benchmark scenes, and comparisons show improved accuracy in scene geometry and photometric reconstruction, while reducing the training time by 3 - 5 times.
RGB-D Neural Radiance Fields: Local Sampling for Faster Training
Mar 26, 2022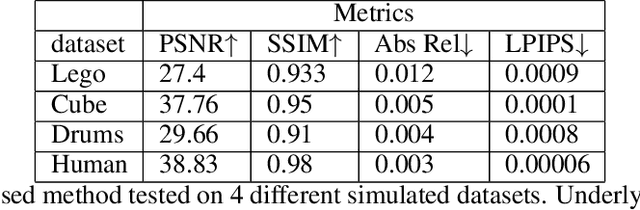
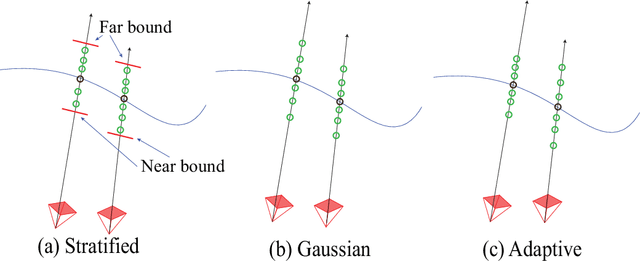
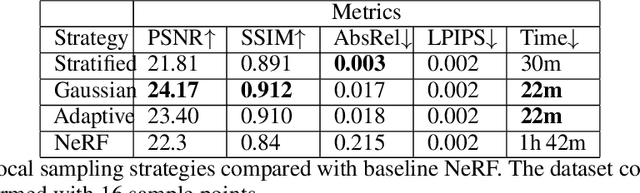

Learning a 3D representation of a scene has been a challenging problem for decades in computer vision. Recent advances in implicit neural representation from images using neural radiance fields(NeRF) have shown promising results. Some of the limitations of previous NeRF based methods include longer training time, and inaccurate underlying geometry. The proposed method takes advantage of RGB-D data to reduce training time by leveraging depth sensing to improve local sampling. This paper proposes a depth-guided local sampling strategy and a smaller neural network architecture to achieve faster training time without compromising quality.
Urban Fire Station Location Planning: A Systematic Approach using Predicted Demand and Service Quality Index
Sep 05, 2021
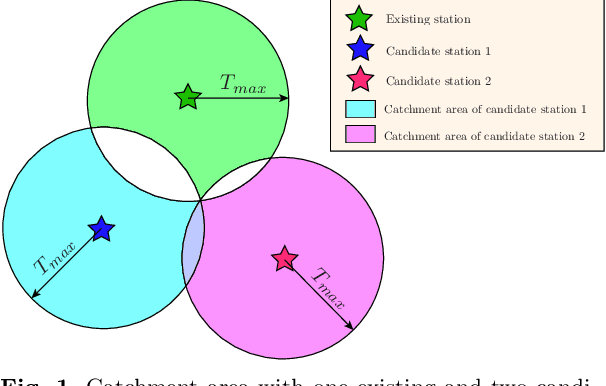
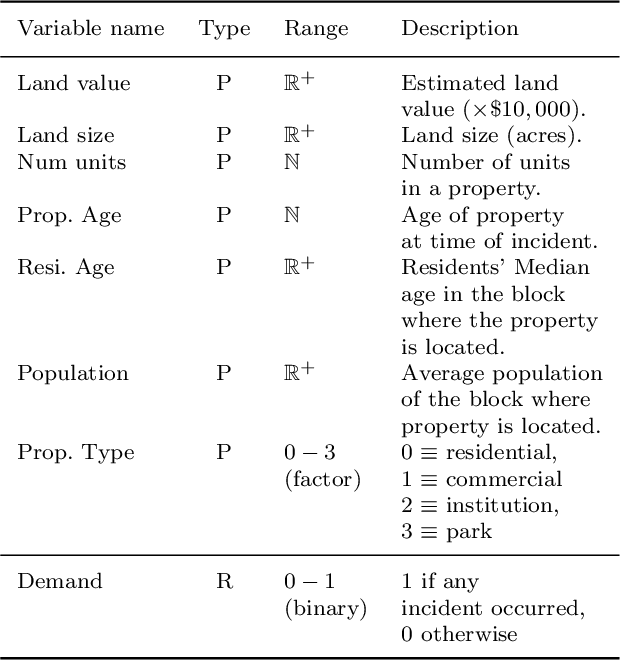
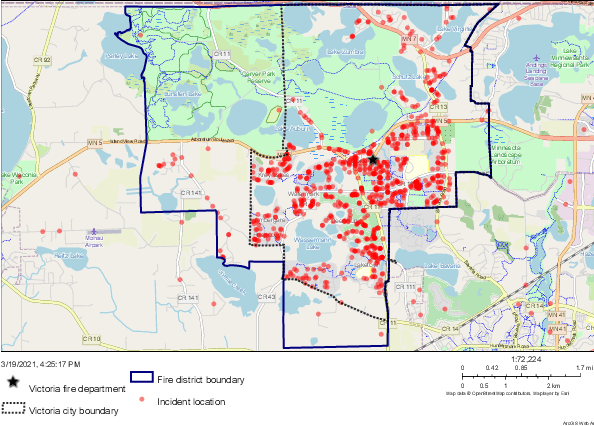
In this article, we propose a systematic approach for fire station location planning. We develop a machine learning model, based on Random Forest, for demand prediction and utilize the model further to define a generalized index to measure quality of fire service in urban settings. Our model is built upon spatial data collected from multiple different sources. Efficacy of proper facility planning depends on choice of candidates where fire stations can be located along with existing stations, if any. Also, the travel time from these candidates to demand locations need to be taken care of to maintain fire safety standard. Here, we propose a travel time based clustering technique to identify suitable candidates. Finally, we develop an optimization problem to select best locations to install new fire stations. Our optimization problem is built upon maximum coverage problem, based on integer programming. We present a detailed experimental study of our proposed approach in collaboration with city of Victoria Fire Department, MN, USA. Our demand prediction model achieves true positive rate of 70% and false positive rate of 22% approximately. We aid Victoria Fire Department to select a location for a new fire station using our approach. We present detailed results on improvement statistics by locating a new facility, as suggested by our methodology, in the city of Victoria.