 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSED:Lightweight Saliency prediction for Event-based data via Distillation
Jun 12, 2026Event-based saliency prediction has gained attention recently, as combining event cameras with saliency estimation can act as an upstream stage that naturally improves the efficiency of downstream eventbased perception at the edge. However, current approaches are either neuromorphic, underperforming on event-based saliency benchmarks, or too heavy for resource-constrained edge applications due to their reliance on transformers or 3D convolutions. Drawing inspiration from efficient convolutional modules, SED and aiming to exploit the temporal information in event data, we propose a lightweight network, trained through knowledge distillation, built on a Depthwise Spatio-Temporal Block (DSTconv) -- a factorization of the 3D depthwise separable convolution. Relative to its teacher, our model reduces the model size from 180 MB to 0.32 MB (562x) and the parameter count from 45M to 81k (554x), while matching or outperforming it on the N-DHF1K and N-UCF Sports datasets. Moreover, it generalizes strongly beyond its training distribution, transferring from synthetic to real event data where a model trained from scratch fails.
Exploring deep learning for Event-Based Saliency Prediction with a Transformer-based model
May 22, 2026Saliency prediction has been extensively studied in RGB images and videos as a computational model of human visual attention. In contrast, predicting saliency from event-based data remains largely unexplored, despite the biological inspiration and favorable sensing properties of event cameras. Two obstacles have held this direction back: the absence of large-scale event saliency datasets, and the lack of a strong baseline. In this paper, we introduce SEST (Swin Event-based Saliency Transformer), a transformer-based model for saliency prediction from event data, bridging the data scarcity barrier through event-native pretraining and synthetic supervision. SEST leverages a self-supervised pretrained event-based Swin Transformer backbone combined with a lightweight CNN decoder to produce dynamic saliency maps. To address the scarcity of annotated event-based saliency data, we introduce two new benchmark datasets, N-DHF1K and N-UCF Sports, generated from large-scale RGB saliency benchmarks. Experimental results show that SEST clearly outperforms existing event-based saliency methods and narrows the performance gap with state-of-the-art RGB models. Zero-shot evaluation on a real event camera dataset further demonstrates that our model trained on synthetic data remains transferable on real event streams. To the best of our knowledge, this work is the first to apply deep learning to event-based saliency prediction, opening a new research direction at the intersection of event-based vision and neuromorphic visual attention.
HFGaussian: Learning Generalizable Gaussian Human with Integrated Human Features
Nov 05, 2024



Recent advancements in radiance field rendering show promising results in 3D scene representation, where Gaussian splatting-based techniques emerge as state-of-the-art due to their quality and efficiency. Gaussian splatting is widely used for various applications, including 3D human representation. However, previous 3D Gaussian splatting methods either use parametric body models as additional information or fail to provide any underlying structure, like human biomechanical features, which are essential for different applications. In this paper, we present a novel approach called HFGaussian that can estimate novel views and human features, such as the 3D skeleton, 3D key points, and dense pose, from sparse input images in real time at 25 FPS. The proposed method leverages generalizable Gaussian splatting technique to represent the human subject and its associated features, enabling efficient and generalizable reconstruction. By incorporating a pose regression network and the feature splatting technique with Gaussian splatting, HFGaussian demonstrates improved capabilities over existing 3D human methods, showcasing the potential of 3D human representations with integrated biomechanics. We thoroughly evaluate our HFGaussian method against the latest state-of-the-art techniques in human Gaussian splatting and pose estimation, demonstrating its real-time, state-of-the-art performance.
EvSegSNN: Neuromorphic Semantic Segmentation for Event Data
Jun 20, 2024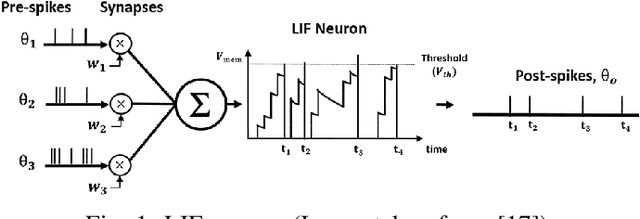

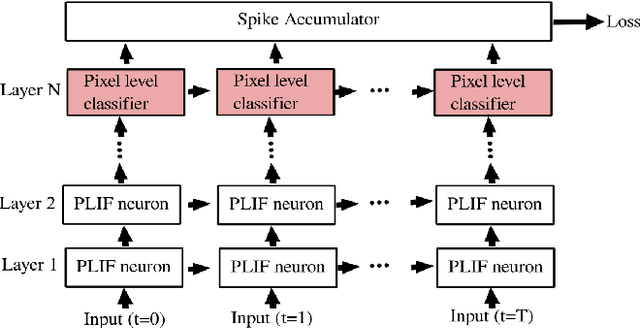
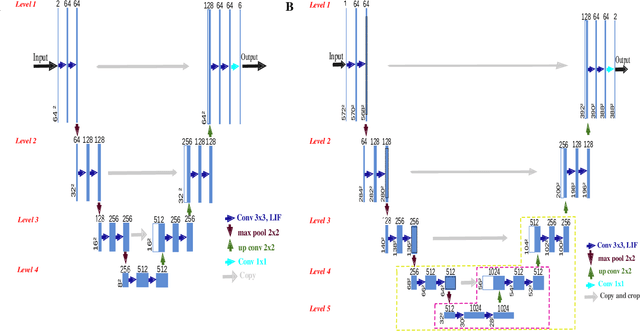
Semantic segmentation is an important computer vision task, particularly for scene understanding and navigation of autonomous vehicles and UAVs. Several variations of deep neural network architectures have been designed to tackle this task. However, due to their huge computational costs and their high memory consumption, these models are not meant to be deployed on resource-constrained systems. To address this limitation, we introduce an end-to-end biologically inspired semantic segmentation approach by combining Spiking Neural Networks (SNNs, a low-power alternative to classical neural networks) with event cameras whose output data can directly feed these neural network inputs. We have designed EvSegSNN, a biologically plausible encoder-decoder U-shaped architecture relying on Parametric Leaky Integrate and Fire neurons in an objective to trade-off resource usage against performance. The experiments conducted on DDD17 demonstrate that EvSegSNN outperforms the closest state-of-the-art model in terms of MIoU while reducing the number of parameters by a factor of $1.6$ and sparing a batch normalization stage.
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Apr 09, 2024



Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields
Apr 09, 2024In recent advancements in novel view synthesis, generalizable Neural Radiance Fields (NeRF) based methods applied to human subjects have shown remarkable results in generating novel views from few images. However, this generalization ability cannot capture the underlying structural features of the skeleton shared across all instances. Building upon this, we introduce HFNeRF: a novel generalizable human feature NeRF aimed at generating human biomechanic features using a pre-trained image encoder. While previous human NeRF methods have shown promising results in the generation of photorealistic virtual avatars, such methods lack underlying human structure or biomechanic features such as skeleton or joint information that are crucial for downstream applications including Augmented Reality (AR)/Virtual Reality (VR). HFNeRF leverages 2D pre-trained foundation models toward learning human features in 3D using neural rendering, and then volume rendering towards generating 2D feature maps. We evaluate HFNeRF in the skeleton estimation task by predicting heatmaps as features. The proposed method is fully differentiable, allowing to successfully learn color, geometry, and human skeleton in a simultaneous manner. This paper presents preliminary results of HFNeRF, illustrating its potential in generating realistic virtual avatars with biomechanic features using NeRF.
Bio-inspired visual attention for silicon retinas based on spiking neural networks applied to pattern classification
May 31, 2021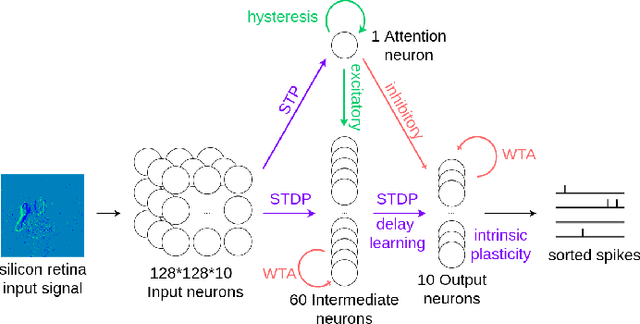
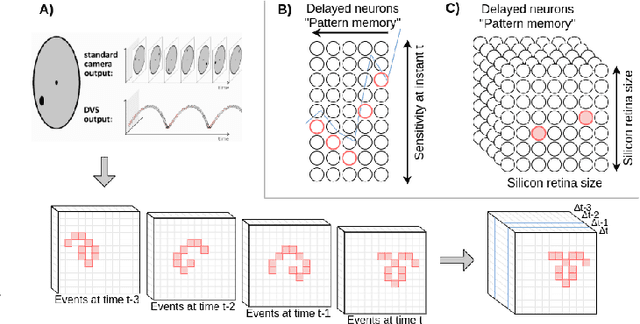
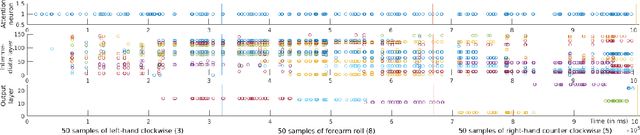
Visual attention can be defined as the behavioral and cognitive process of selectively focusing on a discrete aspect of sensory cues while disregarding other perceivable information. This biological mechanism, more specifically saliency detection, has long been used in multimedia indexing to drive the analysis only on relevant parts of images or videos for further processing. The recent advent of silicon retinas (or event cameras -- sensors that measure pixel-wise changes in brightness and output asynchronous events accordingly) raises the question of how to adapt attention and saliency to the unconventional type of such sensors' output. Silicon retina aims to reproduce the biological retina behaviour. In that respect, they produce punctual events in time that can be construed as neural spikes and interpreted as such by a neural network. In particular, Spiking Neural Networks (SNNs) represent an asynchronous type of artificial neural network closer to biology than traditional artificial networks, mainly because they seek to mimic the dynamics of neural membrane and action potentials over time. SNNs receive and process information in the form of spike trains. Therefore, they make for a suitable candidate for the efficient processing and classification of incoming event patterns measured by silicon retinas. In this paper, we review the biological background behind the attentional mechanism, and introduce a case study of event videos classification with SNNs, using a biology-grounded low-level computational attention mechanism, with interesting preliminary results.