 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenVisCoM: Dense Vision Correspondence Mamba for Efficient and Real-time Optical Flow and Stereo Estimation
Feb 02, 2026In this work, we propose a novel Mamba block DenVisCoM, as well as a novel hybrid architecture specifically tailored for accurate and real-time estimation of optical flow and disparity estimation. Given that such multi-view geometry and motion tasks are fundamentally related, we propose a unified architecture to tackle them jointly. Specifically, the proposed hybrid architecture is based on DenVisCoM and a Transformer-based attention block that efficiently addresses real-time inference, memory footprint, and accuracy at the same time for joint estimation of motion and 3D dense perception tasks. We extensively analyze the benchmark trade-off of accuracy and real-time processing on a large number of datasets. Our experimental results and related analysis suggest that our proposed model can accurately estimate optical flow and disparity estimation in real time. All models and associated code are available at https://github.com/vimstereo/DenVisCoM.
Now You See Me, Now You Don't: A Unified Framework for Expression Consistent Anonymization in Talking Head Videos
Jan 14, 2026Face video anonymization is aimed at privacy preservation while allowing for the analysis of videos in a number of computer vision downstream tasks such as expression recognition, people tracking, and action recognition. We propose here a novel unified framework referred to as Anon-NET, streamlined to de-identify facial videos, while preserving age, gender, race, pose, and expression of the original video. Specifically, we inpaint faces by a diffusion-based generative model guided by high-level attribute recognition and motion-aware expression transfer. We then animate deidentified faces by video-driven animation, which accepts the de-identified face and the original video as input. Extensive experiments on the datasets VoxCeleb2, CelebV-HQ, and HDTF, which include diverse facial dynamics, demonstrate the effectiveness of AnonNET in obfuscating identity while retaining visual realism and temporal consistency. The code of AnonNet will be publicly released.
THEval. Evaluation Framework for Talking Head Video Generation
Nov 06, 2025Video generation has achieved remarkable progress, with generated videos increasingly resembling real ones. However, the rapid advance in generation has outpaced the development of adequate evaluation metrics. Currently, the assessment of talking head generation primarily relies on limited metrics, evaluating general video quality, lip synchronization, and on conducting user studies. Motivated by this, we propose a new evaluation framework comprising 8 metrics related to three dimensions (i) quality, (ii) naturalness, and (iii) synchronization. In selecting the metrics, we place emphasis on efficiency, as well as alignment with human preferences. Based on this considerations, we streamline to analyze fine-grained dynamics of head, mouth, and eyebrows, as well as face quality. Our extensive experiments on 85,000 videos generated by 17 state-of-the-art models suggest that while many algorithms excel in lip synchronization, they face challenges with generating expressiveness and artifact-free details. These videos were generated based on a novel real dataset, that we have curated, in order to mitigate bias of training data. Our proposed benchmark framework is aimed at evaluating the improvement of generative methods. Original code, dataset and leaderboards will be publicly released and regularly updated with new methods, in order to reflect progress in the field.
LIA-X: Interpretable Latent Portrait Animator
Aug 13, 2025We introduce LIA-X, a novel interpretable portrait animator designed to transfer facial dynamics from a driving video to a source portrait with fine-grained control. LIA-X is an autoencoder that models motion transfer as a linear navigation of motion codes in latent space. Crucially, it incorporates a novel Sparse Motion Dictionary that enables the model to disentangle facial dynamics into interpretable factors. Deviating from previous 'warp-render' approaches, the interpretability of the Sparse Motion Dictionary allows LIA-X to support a highly controllable 'edit-warp-render' strategy, enabling precise manipulation of fine-grained facial semantics in the source portrait. This helps to narrow initial differences with the driving video in terms of pose and expression. Moreover, we demonstrate the scalability of LIA-X by successfully training a large-scale model with approximately 1 billion parameters on extensive datasets. Experimental results show that our proposed method outperforms previous approaches in both self-reenactment and cross-reenactment tasks across several benchmarks. Additionally, the interpretable and controllable nature of LIA-X supports practical applications such as fine-grained, user-guided image and video editing, as well as 3D-aware portrait video manipulation.
Just Dance with $π$! A Poly-modal Inductor for Weakly-supervised Video Anomaly Detection
May 19, 2025Weakly-supervised methods for video anomaly detection (VAD) are conventionally based merely on RGB spatio-temporal features, which continues to limit their reliability in real-world scenarios. This is due to the fact that RGB-features are not sufficiently distinctive in setting apart categories such as shoplifting from visually similar events. Therefore, towards robust complex real-world VAD, it is essential to augment RGB spatio-temporal features by additional modalities. Motivated by this, we introduce the Poly-modal Induced framework for VAD: "PI-VAD", a novel approach that augments RGB representations by five additional modalities. Specifically, the modalities include sensitivity to fine-grained motion (Pose), three dimensional scene and entity representation (Depth), surrounding objects (Panoptic masks), global motion (optical flow), as well as language cues (VLM). Each modality represents an axis of a polygon, streamlined to add salient cues to RGB. PI-VAD includes two plug-in modules, namely Pseudo-modality Generation module and Cross Modal Induction module, which generate modality-specific prototypical representation and, thereby, induce multi-modal information into RGB cues. These modules operate by performing anomaly-aware auxiliary tasks and necessitate five modality backbones -- only during training. Notably, PI-VAD achieves state-of-the-art accuracy on three prominent VAD datasets encompassing real-world scenarios, without requiring the computational overhead of five modality backbones at inference.
Dimitra: Audio-driven Diffusion model for Expressive Talking Head Generation
Feb 24, 2025We propose Dimitra, a novel framework for audio-driven talking head generation, streamlined to learn lip motion, facial expression, as well as head pose motion. Specifically, we train a conditional Motion Diffusion Transformer (cMDT) by modeling facial motion sequences with 3D representation. We condition the cMDT with only two input signals, an audio-sequence, as well as a reference facial image. By extracting additional features directly from audio, Dimitra is able to increase quality and realism of generated videos. In particular, phoneme sequences contribute to the realism of lip motion, whereas text transcript to facial expression and head pose realism. Quantitative and qualitative experiments on two widely employed datasets, VoxCeleb2 and HDTF, showcase that Dimitra is able to outperform existing approaches for generating realistic talking heads imparting lip motion, facial expression, and head pose.
MVP: Multimodal Emotion Recognition based on Video and Physiological Signals
Jan 06, 2025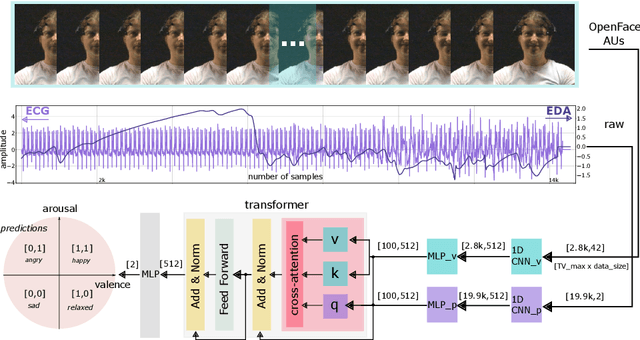
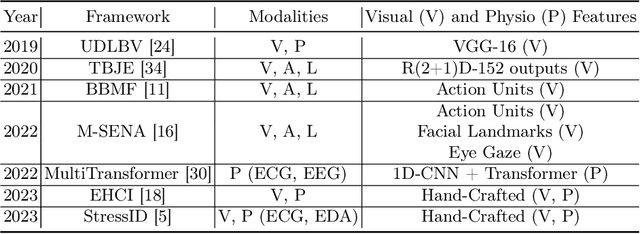
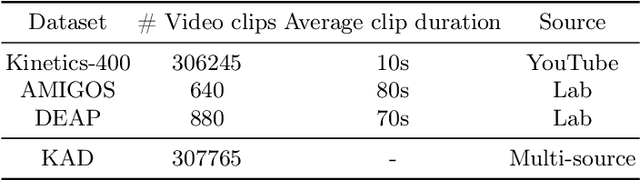
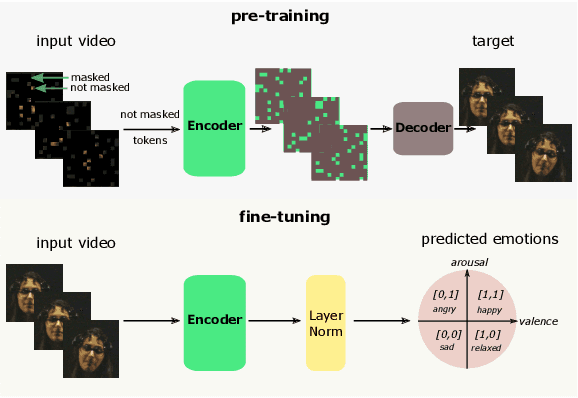
Human emotions entail a complex set of behavioral, physiological and cognitive changes. Current state-of-the-art models fuse the behavioral and physiological components using classic machine learning, rather than recent deep learning techniques. We propose to fill this gap, designing the Multimodal for Video and Physio (MVP) architecture, streamlined to fuse video and physiological signals. Differently then others approaches, MVP exploits the benefits of attention to enable the use of long input sequences (1-2 minutes). We have studied video and physiological backbones for inputting long sequences and evaluated our method with respect to the state-of-the-art. Our results show that MVP outperforms former methods for emotion recognition based on facial videos, EDA, and ECG/PPG.
AM Flow: Adapters for Temporal Processing in Action Recognition
Nov 04, 2024



Deep learning models, in particular \textit{image} models, have recently gained generalisability and robustness. %are becoming more general and robust by the day. In this work, we propose to exploit such advances in the realm of \textit{video} classification. Video foundation models suffer from the requirement of extensive pretraining and a large training time. Towards mitigating such limitations, we propose "\textit{Attention Map (AM) Flow}" for image models, a method for identifying pixels relevant to motion in each input video frame. In this context, we propose two methods to compute AM flow, depending on camera motion. AM flow allows the separation of spatial and temporal processing, while providing improved results over combined spatio-temporal processing (as in video models). Adapters, one of the popular techniques in parameter efficient transfer learning, facilitate the incorporation of AM flow into pretrained image models, mitigating the need for full-finetuning. We extend adapters to "\textit{temporal processing adapters}" by incorporating a temporal processing unit into the adapters. Our work achieves faster convergence, therefore reducing the number of epochs needed for training. Moreover, we endow an image model with the ability to achieve state-of-the-art results on popular action recognition datasets. This reduces training time and simplifies pretraining. We present experiments on Kinetics-400, Something-Something v2, and Toyota Smarthome datasets, showcasing state-of-the-art or comparable results.
HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields
Apr 09, 2024In recent advancements in novel view synthesis, generalizable Neural Radiance Fields (NeRF) based methods applied to human subjects have shown remarkable results in generating novel views from few images. However, this generalization ability cannot capture the underlying structural features of the skeleton shared across all instances. Building upon this, we introduce HFNeRF: a novel generalizable human feature NeRF aimed at generating human biomechanic features using a pre-trained image encoder. While previous human NeRF methods have shown promising results in the generation of photorealistic virtual avatars, such methods lack underlying human structure or biomechanic features such as skeleton or joint information that are crucial for downstream applications including Augmented Reality (AR)/Virtual Reality (VR). HFNeRF leverages 2D pre-trained foundation models toward learning human features in 3D using neural rendering, and then volume rendering towards generating 2D feature maps. We evaluate HFNeRF in the skeleton estimation task by predicting heatmaps as features. The proposed method is fully differentiable, allowing to successfully learn color, geometry, and human skeleton in a simultaneous manner. This paper presents preliminary results of HFNeRF, illustrating its potential in generating realistic virtual avatars with biomechanic features using NeRF.
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Apr 09, 2024



Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.