 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Quality Control of Medical Image Segmentations across Organs
Nov 12, 2025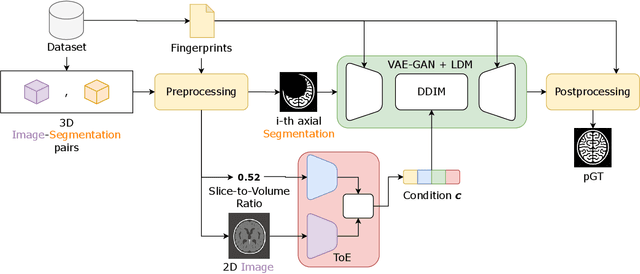
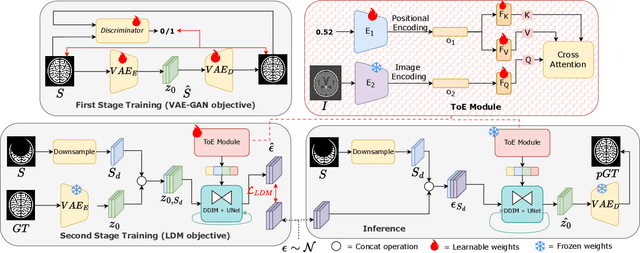
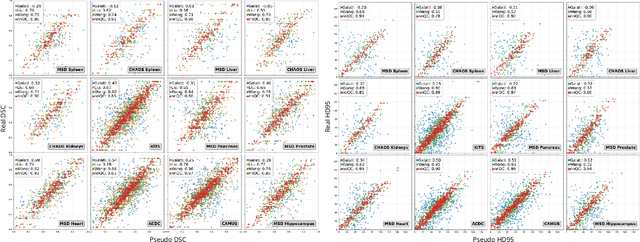
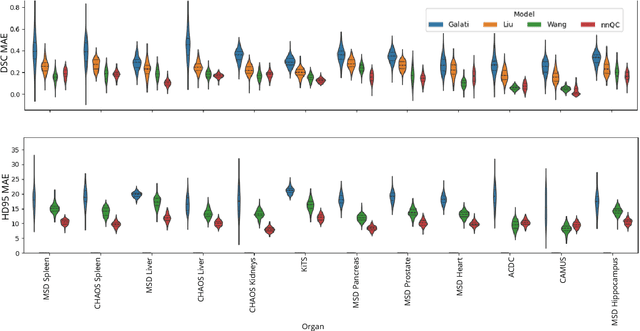
Medical image segmentation using deep learning (DL) has enabled the development of automated analysis pipelines for large-scale population studies. However, state-of-the-art DL methods are prone to hallucinations, which can result in anatomically implausible segmentations. With manual correction impractical at scale, automated quality control (QC) techniques have to address the challenge. While promising, existing QC methods are organ-specific, limiting their generalizability and usability beyond their original intended task. To overcome this limitation, we propose no-new Quality Control (nnQC), a robust QC framework based on a diffusion-generative paradigm that self-adapts to any input organ dataset. Central to nnQC is a novel Team of Experts (ToE) architecture, where two specialized experts independently encode 3D spatial awareness, represented by the relative spatial position of an axial slice, and anatomical information derived from visual features from the original image. A weighted conditional module dynamically combines the pair of independent embeddings, or opinions to condition the sampling mechanism within a diffusion process, enabling the generation of a spatially aware pseudo-ground truth for predicting QC scores. Within its framework, nnQC integrates fingerprint adaptation to ensure adaptability across organs, datasets, and imaging modalities. We evaluated nnQC on seven organs using twelve publicly available datasets. Our results demonstrate that nnQC consistently outperforms state-of-the-art methods across all experiments, including cases where segmentation masks are highly degraded or completely missing, confirming its versatility and effectiveness across different organs.
MVP: Multimodal Emotion Recognition based on Video and Physiological Signals
Jan 06, 2025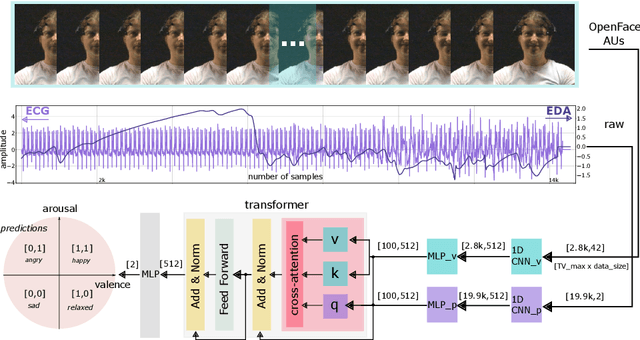
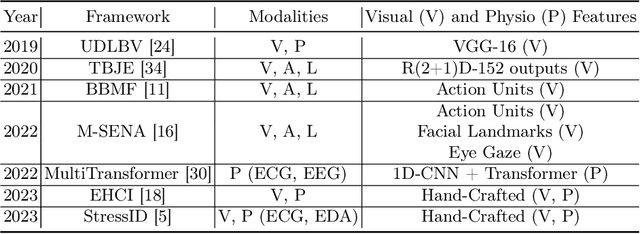
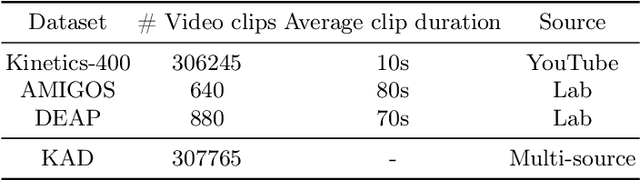
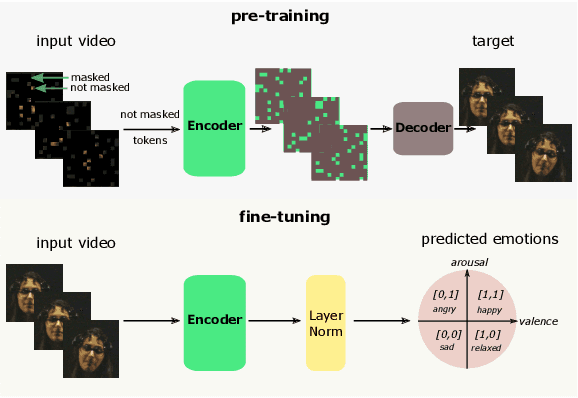
Human emotions entail a complex set of behavioral, physiological and cognitive changes. Current state-of-the-art models fuse the behavioral and physiological components using classic machine learning, rather than recent deep learning techniques. We propose to fill this gap, designing the Multimodal for Video and Physio (MVP) architecture, streamlined to fuse video and physiological signals. Differently then others approaches, MVP exploits the benefits of attention to enable the use of long input sequences (1-2 minutes). We have studied video and physiological backbones for inputting long sequences and evaluated our method with respect to the state-of-the-art. Our results show that MVP outperforms former methods for emotion recognition based on facial videos, EDA, and ECG/PPG.
HyperMM : Robust Multimodal Learning with Varying-sized Inputs
Jul 30, 2024



Combining multiple modalities carrying complementary information through multimodal learning (MML) has shown considerable benefits for diagnosing multiple pathologies. However, the robustness of multimodal models to missing modalities is often overlooked. Most works assume modality completeness in the input data, while in clinical practice, it is common to have incomplete modalities. Existing solutions that address this issue rely on modality imputation strategies before using supervised learning models. These strategies, however, are complex, computationally costly and can strongly impact subsequent prediction models. Hence, they should be used with parsimony in sensitive applications such as healthcare. We propose HyperMM, an end-to-end framework designed for learning with varying-sized inputs. Specifically, we focus on the task of supervised MML with missing imaging modalities without using imputation before training. We introduce a novel strategy for training a universal feature extractor using a conditional hypernetwork, and propose a permutation-invariant neural network that can handle inputs of varying dimensions to process the extracted features, in a two-phase task-agnostic framework. We experimentally demonstrate the advantages of our method in two tasks: Alzheimer's disease detection and breast cancer classification. We demonstrate that our strategy is robust to high rates of missing data and that its flexibility allows it to handle varying-sized datasets beyond the scenario of missing modalities.