 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-MoE: A Body-Part-Aware Mixture-of-Experts "All Parts Matter" Approach to Micro-Action Recognition
Mar 25, 2026Micro-actions, fleeting and low-amplitude motions, such as glances, nods, or minor posture shifts, carry rich social meaning but remain difficult for current action recognition models to recognize due to their subtlety, short duration, and high inter-class ambiguity. In this paper, we introduce B-MoE, a Body-part-aware Mixture-of-Experts framework designed to explicitly model the structured nature of human motion. In B-MoE, each expert specializes in a distinct body region (head, body, upper limbs, lower limbs), and is based on the lightweight Macro-Micro Motion Encoder (M3E) that captures long-range contextual structure and fine-grained local motion. A cross-attention routing mechanism learns inter-region relationships and dynamically selects the most informative regions for each micro-action. B-MoE uses a dual-stream encoder that fuses these region-specific semantic cues with global motion features to jointly capture spatially localized cues and temporally subtle variations that characterize micro-actions. Experiments on three challenging benchmarks (MA-52, SocialGesture, and MPII-GroupInteraction) show consistent state-of-theart gains, with improvements in ambiguous, underrepresented, and low amplitude classes.
Not all Blends are Equal: The BLEMORE Dataset of Blended Emotion Expressions with Relative Salience Annotations
Jan 19, 2026Humans often experience not just a single basic emotion at a time, but rather a blend of several emotions with varying salience. Despite the importance of such blended emotions, most video-based emotion recognition approaches are designed to recognize single emotions only. The few approaches that have attempted to recognize blended emotions typically cannot assess the relative salience of the emotions within a blend. This limitation largely stems from the lack of datasets containing a substantial number of blended emotion samples annotated with relative salience. To address this shortcoming, we introduce BLEMORE, a novel dataset for multimodal (video, audio) blended emotion recognition that includes information on the relative salience of each emotion within a blend. BLEMORE comprises over 3,000 clips from 58 actors, performing 6 basic emotions and 10 distinct blends, where each blend has 3 different salience configurations (50/50, 70/30, and 30/70). Using this dataset, we conduct extensive evaluations of state-of-the-art video classification approaches on two blended emotion prediction tasks: (1) predicting the presence of emotions in a given sample, and (2) predicting the relative salience of emotions in a blend. Our results show that unimodal classifiers achieve up to 29% presence accuracy and 13% salience accuracy on the validation set, while multimodal methods yield clear improvements, with ImageBind + WavLM reaching 35% presence accuracy and HiCMAE 18% salience accuracy. On the held-out test set, the best models achieve 33% presence accuracy (VideoMAEv2 + HuBERT) and 18% salience accuracy (HiCMAE). In sum, the BLEMORE dataset provides a valuable resource to advancing research on emotion recognition systems that account for the complexity and significance of blended emotion expressions.
CM3T: Framework for Efficient Multimodal Learning for Inhomogeneous Interaction Datasets
Jan 06, 2025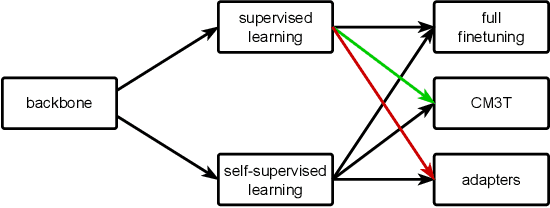
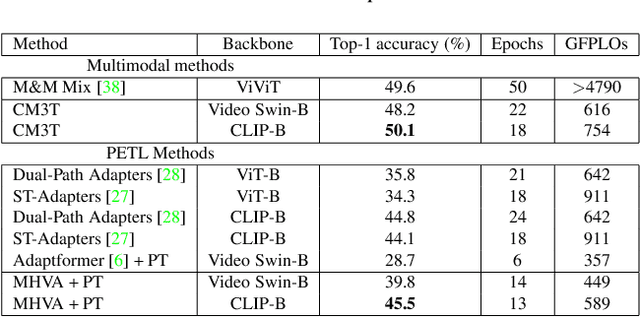
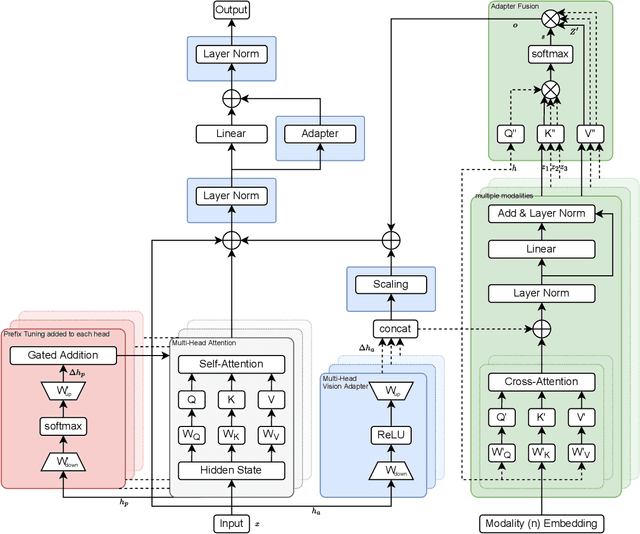
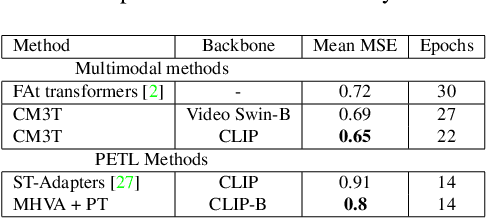
Challenges in cross-learning involve inhomogeneous or even inadequate amount of training data and lack of resources for retraining large pretrained models. Inspired by transfer learning techniques in NLP, adapters and prefix tuning, this paper presents a new model-agnostic plugin architecture for cross-learning, called CM3T, that adapts transformer-based models to new or missing information. We introduce two adapter blocks: multi-head vision adapters for transfer learning and cross-attention adapters for multimodal learning. Training becomes substantially efficient as the backbone and other plugins do not need to be finetuned along with these additions. Comparative and ablation studies on three datasets Epic-Kitchens-100, MPIIGroupInteraction and UDIVA v0.5 show efficacy of this framework on different recording settings and tasks. With only 12.8% trainable parameters compared to the backbone to process video input and only 22.3% trainable parameters for two additional modalities, we achieve comparable and even better results than the state-of-the-art. CM3T has no specific requirements for training or pretraining and is a step towards bridging the gap between a general model and specific practical applications of video classification.
MVP: Multimodal Emotion Recognition based on Video and Physiological Signals
Jan 06, 2025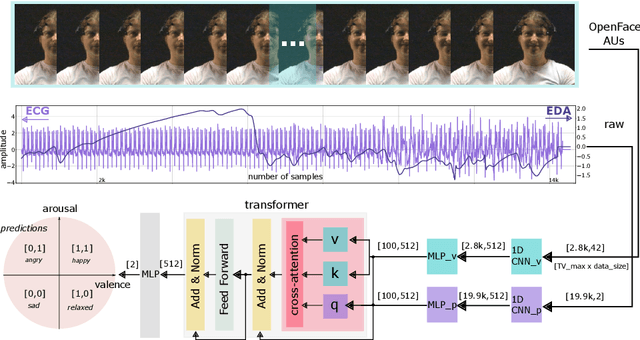
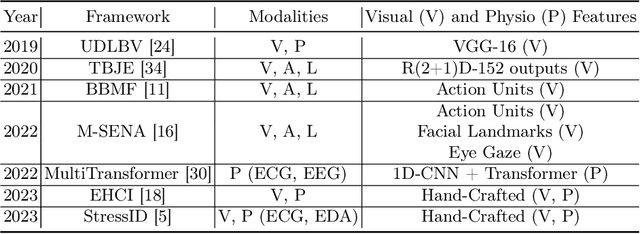
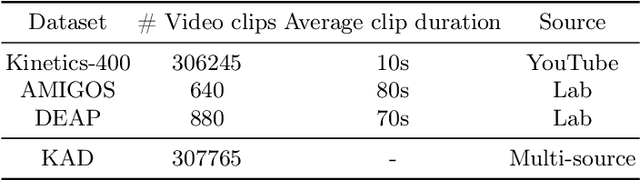
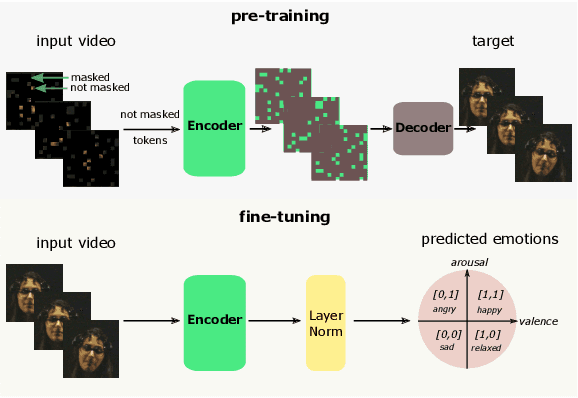
Human emotions entail a complex set of behavioral, physiological and cognitive changes. Current state-of-the-art models fuse the behavioral and physiological components using classic machine learning, rather than recent deep learning techniques. We propose to fill this gap, designing the Multimodal for Video and Physio (MVP) architecture, streamlined to fuse video and physiological signals. Differently then others approaches, MVP exploits the benefits of attention to enable the use of long input sequences (1-2 minutes). We have studied video and physiological backbones for inputting long sequences and evaluated our method with respect to the state-of-the-art. Our results show that MVP outperforms former methods for emotion recognition based on facial videos, EDA, and ECG/PPG.
Identifying Surgical Instruments in Pedagogical Cataract Surgery Videos through an Optimized Aggregation Network
Jan 05, 2025Instructional cataract surgery videos are crucial for ophthalmologists and trainees to observe surgical details repeatedly. This paper presents a deep learning model for real-time identification of surgical instruments in these videos, using a custom dataset scraped from open-access sources. Inspired by the architecture of YOLOV9, the model employs a Programmable Gradient Information (PGI) mechanism and a novel Generally-Optimized Efficient Layer Aggregation Network (Go-ELAN) to address the information bottleneck problem, enhancing Minimum Average Precision (mAP) at higher Non-Maximum Suppression Intersection over Union (NMS IoU) scores. The Go-ELAN YOLOV9 model, evaluated against YOLO v5, v7, v8, v9 vanilla, Laptool and DETR, achieves a superior mAP of 73.74 at IoU 0.5 on a dataset of 615 images with 10 instrument classes, demonstrating the effectiveness of the proposed model.
Introducing Gating and Context into Temporal Action Detection
Sep 06, 2024Temporal Action Detection (TAD), the task of localizing and classifying actions in untrimmed video, remains challenging due to action overlaps and variable action durations. Recent findings suggest that TAD performance is dependent on the structural design of transformers rather than on the self-attention mechanism. Building on this insight, we propose a refined feature extraction process through lightweight, yet effective operations. First, we employ a local branch that employs parallel convolutions with varying window sizes to capture both fine-grained and coarse-grained temporal features. This branch incorporates a gating mechanism to select the most relevant features. Second, we introduce a context branch that uses boundary frames as key-value pairs to analyze their relationship with the central frame through cross-attention. The proposed method captures temporal dependencies and improves contextual understanding. Evaluations of the gating mechanism and context branch on challenging datasets (THUMOS14 and EPIC-KITCHEN 100) show a consistent improvement over the baseline and existing methods.
What Matters in Autonomous Driving Anomaly Detection: A Weakly Supervised Horizon
Aug 10, 2024Video anomaly detection (VAD) in autonomous driving scenario is an important task, however it involves several challenges due to the ego-centric views and moving camera. Due to this, it remains largely under-explored. While recent developments in weakly-supervised VAD methods have shown remarkable progress in detecting critical real-world anomalies in static camera scenario, the development and validation of such methods are yet to be explored for moving camera VAD. This is mainly due to existing datasets like DoTA not following training pre-conditions of weakly-supervised learning. In this paper, we aim to promote weakly-supervised method development for autonomous driving VAD. We reorganize the DoTA dataset and aim to validate recent powerful weakly-supervised VAD methods on moving camera scenarios. Further, we provide a detailed analysis of what modifications on state-of-the-art methods can significantly improve the detection performance. Towards this, we propose a "feature transformation block" and through experimentation we show that our propositions can empower existing weakly-supervised VAD methods significantly in improving the VAD in autonomous driving. Our codes/dataset/demo will be released at github.com/ut21/WSAD-Driving
MultiMediate'23: Engagement Estimation and Bodily Behaviour Recognition in Social Interactions
Aug 16, 2023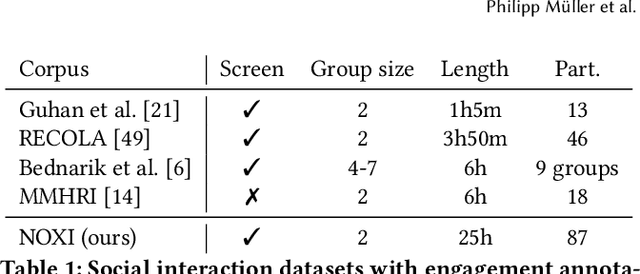

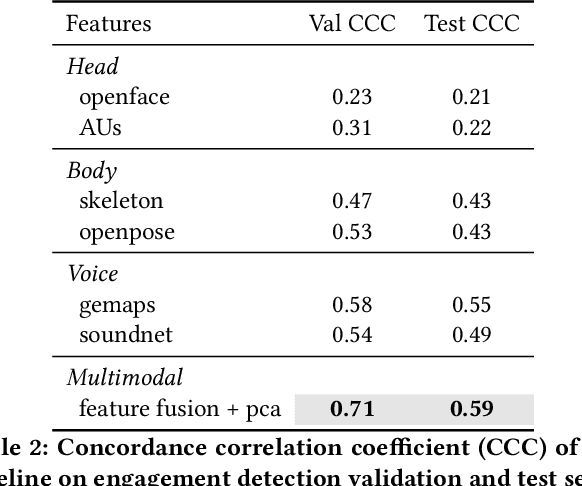
Automatic analysis of human behaviour is a fundamental prerequisite for the creation of machines that can effectively interact with- and support humans in social interactions. In MultiMediate'23, we address two key human social behaviour analysis tasks for the first time in a controlled challenge: engagement estimation and bodily behaviour recognition in social interactions. This paper describes the MultiMediate'23 challenge and presents novel sets of annotations for both tasks. For engagement estimation we collected novel annotations on the NOvice eXpert Interaction (NOXI) database. For bodily behaviour recognition, we annotated test recordings of the MPIIGroupInteraction corpus with the BBSI annotation scheme. In addition, we present baseline results for both challenge tasks.
Multimodal Vision Transformers with Forced Attention for Behavior Analysis
Dec 07, 2022Human behavior understanding requires looking at minute details in the large context of a scene containing multiple input modalities. It is necessary as it allows the design of more human-like machines. While transformer approaches have shown great improvements, they face multiple challenges such as lack of data or background noise. To tackle these, we introduce the Forced Attention (FAt) Transformer which utilize forced attention with a modified backbone for input encoding and a use of additional inputs. In addition to improving the performance on different tasks and inputs, the modification requires less time and memory resources. We provide a model for a generalised feature extraction for tasks concerning social signals and behavior analysis. Our focus is on understanding behavior in videos where people are interacting with each other or talking into the camera which simulates the first person point of view in social interaction. FAt Transformers are applied to two downstream tasks: personality recognition and body language recognition. We achieve state-of-the-art results for Udiva v0.5, First Impressions v2 and MPII Group Interaction datasets. We further provide an extensive ablation study of the proposed architecture.
Bodily Behaviors in Social Interaction: Novel Annotations and State-of-the-Art Evaluation
Jul 26, 2022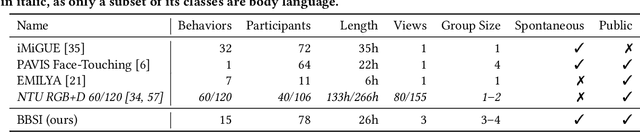
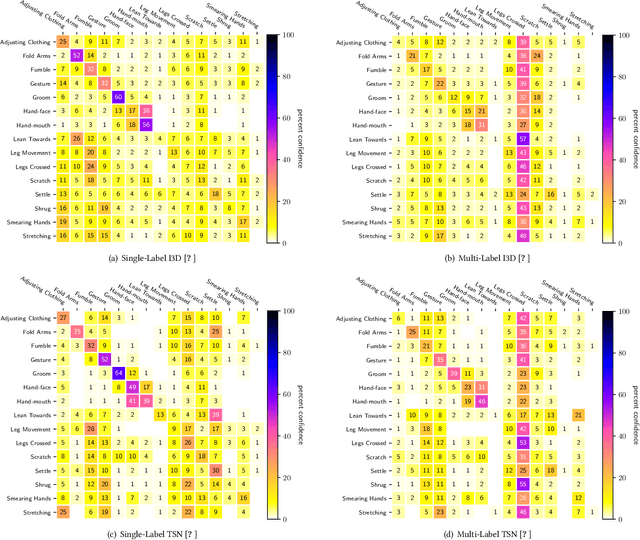
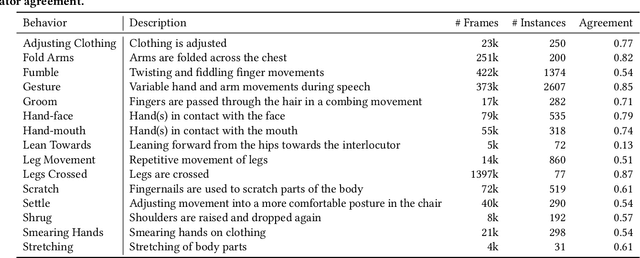
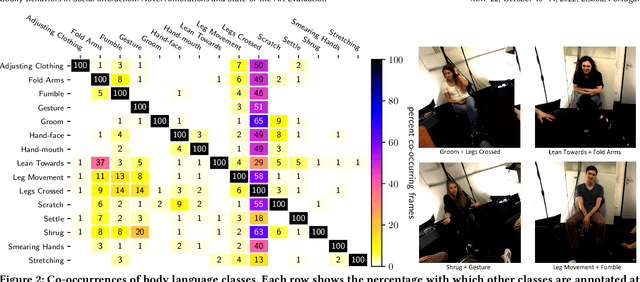
Body language is an eye-catching social signal and its automatic analysis can significantly advance artificial intelligence systems to understand and actively participate in social interactions. While computer vision has made impressive progress in low-level tasks like head and body pose estimation, the detection of more subtle behaviors such as gesturing, grooming, or fumbling is not well explored. In this paper we present BBSI, the first set of annotations of complex Bodily Behaviors embedded in continuous Social Interactions in a group setting. Based on previous work in psychology, we manually annotated 26 hours of spontaneous human behavior in the MPIIGroupInteraction dataset with 15 distinct body language classes. We present comprehensive descriptive statistics on the resulting dataset as well as results of annotation quality evaluations. For automatic detection of these behaviors, we adapt the Pyramid Dilated Attention Network (PDAN), a state-of-the-art approach for human action detection. We perform experiments using four variants of spatial-temporal features as input to PDAN: Two-Stream Inflated 3D CNN, Temporal Segment Networks, Temporal Shift Module and Swin Transformer. Results are promising and indicate a great room for improvement in this difficult task. Representing a key piece in the puzzle towards automatic understanding of social behavior, BBSI is fully available to the research community.