 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM3T: Framework for Efficient Multimodal Learning for Inhomogeneous Interaction Datasets
Jan 06, 2025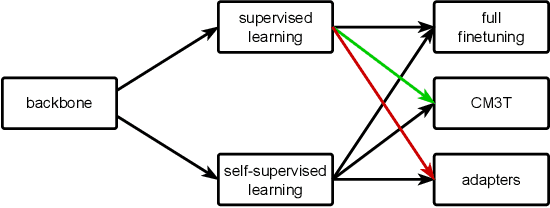
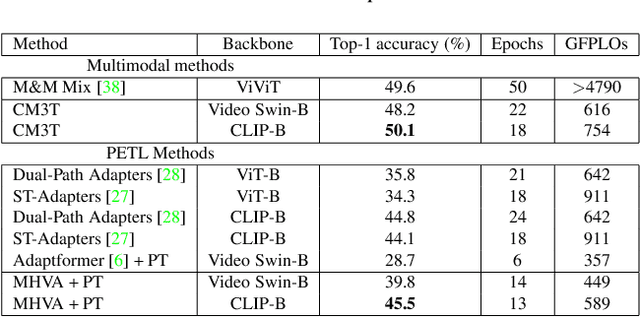
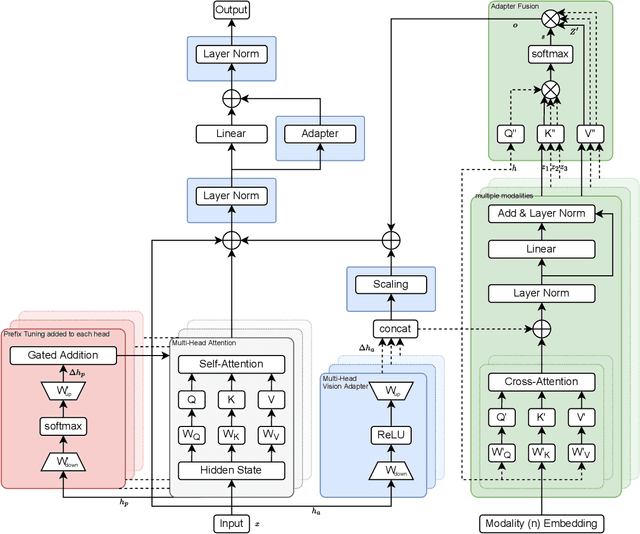
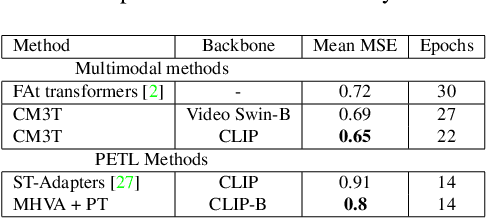
Challenges in cross-learning involve inhomogeneous or even inadequate amount of training data and lack of resources for retraining large pretrained models. Inspired by transfer learning techniques in NLP, adapters and prefix tuning, this paper presents a new model-agnostic plugin architecture for cross-learning, called CM3T, that adapts transformer-based models to new or missing information. We introduce two adapter blocks: multi-head vision adapters for transfer learning and cross-attention adapters for multimodal learning. Training becomes substantially efficient as the backbone and other plugins do not need to be finetuned along with these additions. Comparative and ablation studies on three datasets Epic-Kitchens-100, MPIIGroupInteraction and UDIVA v0.5 show efficacy of this framework on different recording settings and tasks. With only 12.8% trainable parameters compared to the backbone to process video input and only 22.3% trainable parameters for two additional modalities, we achieve comparable and even better results than the state-of-the-art. CM3T has no specific requirements for training or pretraining and is a step towards bridging the gap between a general model and specific practical applications of video classification.
JOADAA: joint online action detection and action anticipation
Sep 12, 2023
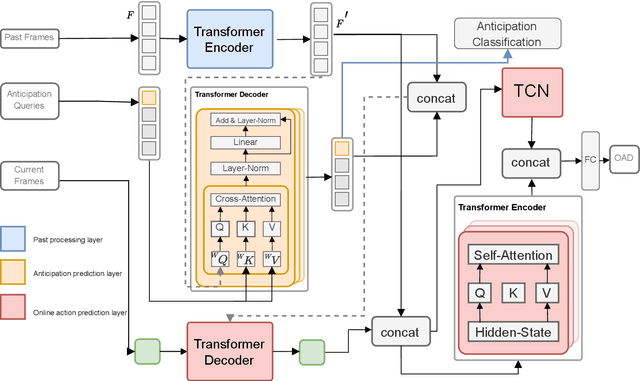
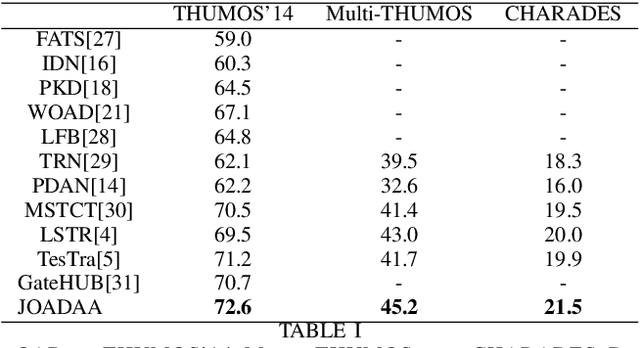
Action anticipation involves forecasting future actions by connecting past events to future ones. However, this reasoning ignores the real-life hierarchy of events which is considered to be composed of three main parts: past, present, and future. We argue that considering these three main parts and their dependencies could improve performance. On the other hand, online action detection is the task of predicting actions in a streaming manner. In this case, one has access only to the past and present information. Therefore, in online action detection (OAD) the existing approaches miss semantics or future information which limits their performance. To sum up, for both of these tasks, the complete set of knowledge (past-present-future) is missing, which makes it challenging to infer action dependencies, therefore having low performances. To address this limitation, we propose to fuse both tasks into a single uniform architecture. By combining action anticipation and online action detection, our approach can cover the missing dependencies of future information in online action detection. This method referred to as JOADAA, presents a uniform model that jointly performs action anticipation and online action detection. We validate our proposed model on three challenging datasets: THUMOS'14, which is a sparsely annotated dataset with one action per time step, CHARADES, and Multi-THUMOS, two densely annotated datasets with more complex scenarios. JOADAA achieves SOTA results on these benchmarks for both tasks.
MultiMediate'23: Engagement Estimation and Bodily Behaviour Recognition in Social Interactions
Aug 16, 2023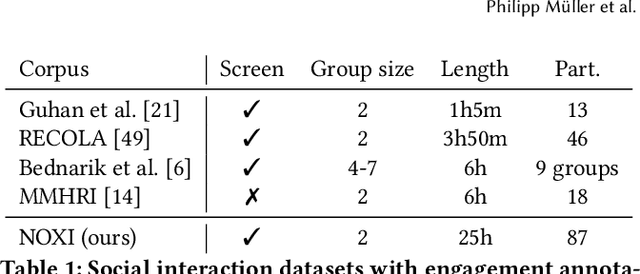
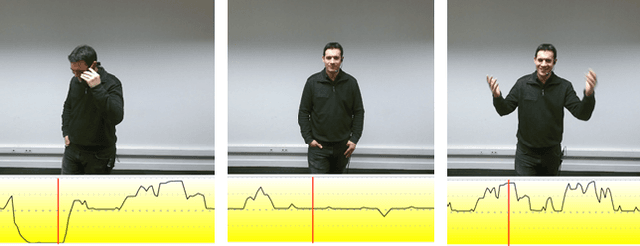

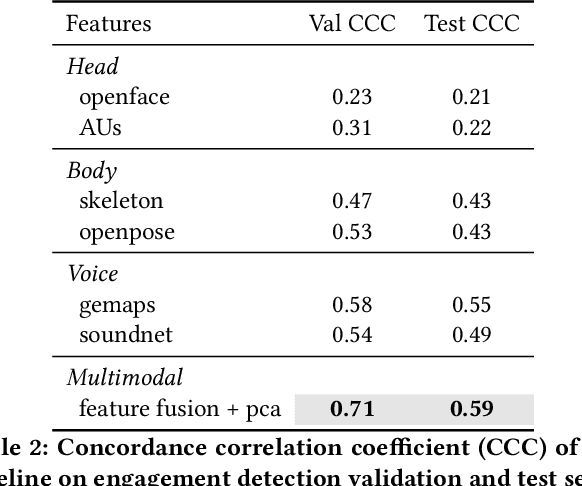
Automatic analysis of human behaviour is a fundamental prerequisite for the creation of machines that can effectively interact with- and support humans in social interactions. In MultiMediate'23, we address two key human social behaviour analysis tasks for the first time in a controlled challenge: engagement estimation and bodily behaviour recognition in social interactions. This paper describes the MultiMediate'23 challenge and presents novel sets of annotations for both tasks. For engagement estimation we collected novel annotations on the NOvice eXpert Interaction (NOXI) database. For bodily behaviour recognition, we annotated test recordings of the MPIIGroupInteraction corpus with the BBSI annotation scheme. In addition, we present baseline results for both challenge tasks.
THORN: Temporal Human-Object Relation Network for Action Recognition
Apr 20, 2022
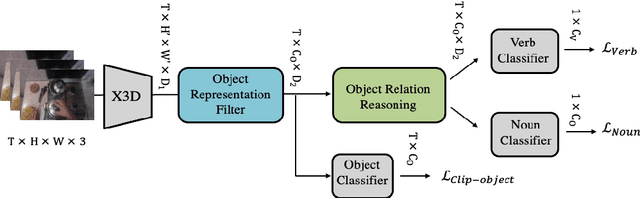
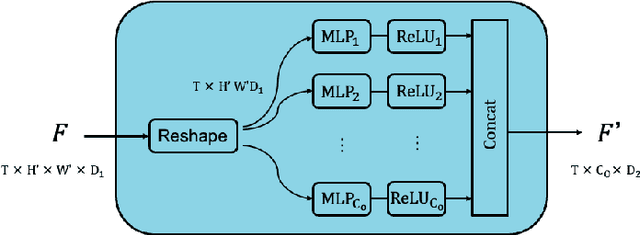

Most action recognition models treat human activities as unitary events. However, human activities often follow a certain hierarchy. In fact, many human activities are compositional. Also, these actions are mostly human-object interactions. In this paper we propose to recognize human action by leveraging the set of interactions that define an action. In this work, we present an end-to-end network: THORN, that can leverage important human-object and object-object interactions to predict actions. This model is built on top of a 3D backbone network. The key components of our model are: 1) An object representation filter for modeling object. 2) An object relation reasoning module to capture object relations. 3) A classification layer to predict the action labels. To show the robustness of THORN, we evaluate it on EPIC-Kitchen55 and EGTEA Gaze+, two of the largest and most challenging first-person and human-object interaction datasets. THORN achieves state-of-the-art performance on both datasets.