 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Patching: Toward Source-Level Mechanistic Localization in LLMs
Apr 15, 2026Mechanistic interpretability seeks to localize model behavior to the internal components that causally realize it. Prior work has advanced activation-space localization and causal tracing, but modules that appear important in activation space may merely aggregate or amplify upstream signals rather than encode the target capability in their own parameters. To address this gap, we propose Weight Patching, a parameter-space intervention method for source-oriented analysis in paired same-architecture models that differ in how strongly they express a target capability under the inputs of interest. Given a base model and a behavior-specialized counterpart, Weight Patching replaces selected module weights from the specialized model into the base model under a fixed input. We instantiate the method on instruction following and introduce a framework centered on a vector-anchor behavioral interface that provides a shared internal criterion for whether a task-relevant control state has been formed or recovered in open-ended generation. Under this framework, the analysis reveals a hierarchy from shallow candidate source-side carriers to aggregation and routing modules, and further to downstream execution circuits. The recovered component scores can also guide mechanism-aware model merging, improving selective fusion across the evaluated expert combinations and providing additional external validation.
Code2World: A GUI World Model via Renderable Code Generation
Feb 10, 2026Autonomous GUI agents interact with environments by perceiving interfaces and executing actions. As a virtual sandbox, the GUI World model empowers agents with human-like foresight by enabling action-conditioned prediction. However, existing text- and pixel-based approaches struggle to simultaneously achieve high visual fidelity and fine-grained structural controllability. To this end, we propose Code2World, a vision-language coder that simulates the next visual state via renderable code generation. Specifically, to address the data scarcity problem, we construct AndroidCode by translating GUI trajectories into high-fidelity HTML and refining synthesized code through a visual-feedback revision mechanism, yielding a corpus of over 80K high-quality screen-action pairs. To adapt existing VLMs into code prediction, we first perform SFT as a cold start for format layout following, then further apply Render-Aware Reinforcement Learning which uses rendered outcome as the reward signal by enforcing visual semantic fidelity and action consistency. Extensive experiments demonstrate that Code2World-8B achieves the top-performing next UI prediction, rivaling the competitive GPT-5 and Gemini-3-Pro-Image. Notably, Code2World significantly enhances downstream navigation success rates in a flexible manner, boosting Gemini-2.5-Flash by +9.5% on AndroidWorld navigation. The code is available at https://github.com/AMAP-ML/Code2World.
Q-Hawkeye: Reliable Visual Policy Optimization for Image Quality Assessment
Jan 30, 2026Image Quality Assessment (IQA) predicts perceptual quality scores consistent with human judgments. Recent RL-based IQA methods built on MLLMs focus on generating visual quality descriptions and scores, ignoring two key reliability limitations: (i) although the model's prediction stability varies significantly across training samples, existing GRPO-based methods apply uniform advantage weighting, thereby amplifying noisy signals from unstable samples in gradient updates; (ii) most works emphasize text-grounded reasoning over images while overlooking the model's visual perception ability of image content. In this paper, we propose Q-Hawkeye, an RL-based reliable visual policy optimization framework that redesigns the learning signal through unified Uncertainty-Aware Dynamic Optimization and Perception-Aware Optimization. Q-Hawkeye estimates predictive uncertainty using the variance of predicted scores across multiple rollouts and leverages this uncertainty to reweight each sample's update strength, stabilizing policy optimization. To strengthen perceptual reliability, we construct paired inputs of degraded images and their original images and introduce an Implicit Perception Loss that constrains the model to ground its quality judgments in genuine visual evidence. Extensive experiments demonstrate that Q-Hawkeye outperforms state-of-the-art methods and generalizes better across multiple datasets. The code and models will be made available.
Urban Socio-Semantic Segmentation with Vision-Language Reasoning
Jan 15, 2026As hubs of human activity, urban surfaces consist of a wealth of semantic entities. Segmenting these various entities from satellite imagery is crucial for a range of downstream applications. Current advanced segmentation models can reliably segment entities defined by physical attributes (e.g., buildings, water bodies) but still struggle with socially defined categories (e.g., schools, parks). In this work, we achieve socio-semantic segmentation by vision-language model reasoning. To facilitate this, we introduce the Urban Socio-Semantic Segmentation dataset named SocioSeg, a new resource comprising satellite imagery, digital maps, and pixel-level labels of social semantic entities organized in a hierarchical structure. Additionally, we propose a novel vision-language reasoning framework called SocioReasoner that simulates the human process of identifying and annotating social semantic entities via cross-modal recognition and multi-stage reasoning. We employ reinforcement learning to optimize this non-differentiable process and elicit the reasoning capabilities of the vision-language model. Experiments demonstrate our approach's gains over state-of-the-art models and strong zero-shot generalization. Our dataset and code are available in https://github.com/AMAP-ML/SocioReasoner.
A Task-Driven, Planner-in-the-Loop Computational Design Framework for Modular Manipulators
Dec 18, 2025Modular manipulators composed of pre-manufactured and interchangeable modules offer high adaptability across diverse tasks. However, their deployment requires generating feasible motions while jointly optimizing morphology and mounted pose under kinematic, dynamic, and physical constraints. Moreover, traditional single-branch designs often extend reach by increasing link length, which can easily violate torque limits at the base joint. To address these challenges, we propose a unified task-driven computational framework that integrates trajectory planning across varying morphologies with the co-optimization of morphology and mounted pose. Within this framework, a hierarchical model predictive control (HMPC) strategy is developed to enable motion planning for both redundant and non-redundant manipulators. For design optimization, the CMA-ES is employed to efficiently explore a hybrid search space consisting of discrete morphology configurations and continuous mounted poses. Meanwhile, a virtual module abstraction is introduced to enable bi-branch morphologies, allowing an auxiliary branch to offload torque from the primary branch and extend the achievable workspace without increasing the capacity of individual joint modules. Extensive simulations and hardware experiments on polishing, drilling, and pick-and-place tasks demonstrate the effectiveness of the proposed framework. The results show that: 1) the framework can generate multiple feasible designs that satisfy kinematic and dynamic constraints while avoiding environmental collisions for given tasks; 2) flexible design objectives, such as maximizing manipulability, minimizing joint effort, or reducing the number of modules, can be achieved by customizing the cost functions; and 3) a bi-branch morphology capable of operating in a large workspace can be realized without requiring more powerful basic modules.
Safe Learning for Contact-Rich Robot Tasks: A Survey from Classical Learning-Based Methods to Safe Foundation Models
Dec 10, 2025Contact-rich tasks pose significant challenges for robotic systems due to inherent uncertainty, complex dynamics, and the high risk of damage during interaction. Recent advances in learning-based control have shown great potential in enabling robots to acquire and generalize complex manipulation skills in such environments, but ensuring safety, both during exploration and execution, remains a critical bottleneck for reliable real-world deployment. This survey provides a comprehensive overview of safe learning-based methods for robot contact-rich tasks. We categorize existing approaches into two main domains: safe exploration and safe execution. We review key techniques, including constrained reinforcement learning, risk-sensitive optimization, uncertainty-aware modeling, control barrier functions, and model predictive safety shields, and highlight how these methods incorporate prior knowledge, task structure, and online adaptation to balance safety and efficiency. A particular emphasis of this survey is on how these safe learning principles extend to and interact with emerging robotic foundation models, especially vision-language models (VLMs) and vision-language-action models (VLAs), which unify perception, language, and control for contact-rich manipulation. We discuss both the new safety opportunities enabled by VLM/VLA-based methods, such as language-level specification of constraints and multimodal grounding of safety signals, and the amplified risks and evaluation challenges they introduce. Finally, we outline current limitations and promising future directions toward deploying reliable, safety-aligned, and foundation-model-enabled robots in complex contact-rich environments. More details and materials are available at our \href{ https://github.com/jack-sherman01/Awesome-Learning4Safe-Contact-rich-tasks}{Project GitHub Repository}.
INTENTION: Inferring Tendencies of Humanoid Robot Motion Through Interactive Intuition and Grounded VLM
Aug 06, 2025Traditional control and planning for robotic manipulation heavily rely on precise physical models and predefined action sequences. While effective in structured environments, such approaches often fail in real-world scenarios due to modeling inaccuracies and struggle to generalize to novel tasks. In contrast, humans intuitively interact with their surroundings, demonstrating remarkable adaptability, making efficient decisions through implicit physical understanding. In this work, we propose INTENTION, a novel framework enabling robots with learned interactive intuition and autonomous manipulation in diverse scenarios, by integrating Vision-Language Models (VLMs) based scene reasoning with interaction-driven memory. We introduce Memory Graph to record scenes from previous task interactions which embodies human-like understanding and decision-making about different tasks in real world. Meanwhile, we design an Intuitive Perceptor that extracts physical relations and affordances from visual scenes. Together, these components empower robots to infer appropriate interaction behaviors in new scenes without relying on repetitive instructions. Videos: https://robo-intention.github.io
Effective Probabilistic Time Series Forecasting with Fourier Adaptive Noise-Separated Diffusion
May 16, 2025We propose the Fourier Adaptive Lite Diffusion Architecture (FALDA), a novel probabilistic framework for time series forecasting. First, we introduce the Diffusion Model for Residual Regression (DMRR) framework, which unifies diffusion-based probabilistic regression methods. Within this framework, FALDA leverages Fourier-based decomposition to incorporate a component-specific architecture, enabling tailored modeling of individual temporal components. A conditional diffusion model is utilized to estimate the future noise term, while our proposed lightweight denoiser, DEMA (Decomposition MLP with AdaLN), conditions on the historical noise term to enhance denoising performance. Through mathematical analysis and empirical validation, we demonstrate that FALDA effectively reduces epistemic uncertainty, allowing probabilistic learning to primarily focus on aleatoric uncertainty. Experiments on six real-world benchmarks demonstrate that FALDA consistently outperforms existing probabilistic forecasting approaches across most datasets for long-term time series forecasting while achieving enhanced computational efficiency without compromising accuracy. Notably, FALDA also achieves superior overall performance compared to state-of-the-art (SOTA) point forecasting approaches, with improvements of up to 9%.
Leveraging Submodule Linearity Enhances Task Arithmetic Performance in LLMs
Apr 15, 2025
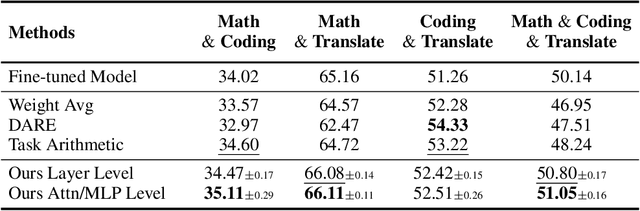

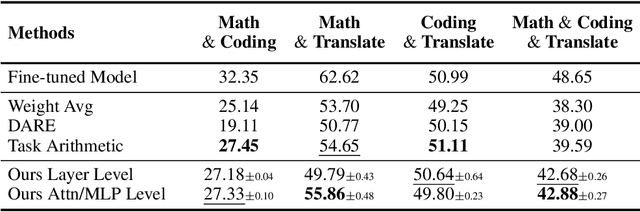
Task arithmetic is a straightforward yet highly effective strategy for model merging, enabling the resultant model to exhibit multi-task capabilities. Recent research indicates that models demonstrating linearity enhance the performance of task arithmetic. In contrast to existing methods that rely on the global linearization of the model, we argue that this linearity already exists within the model's submodules. In particular, we present a statistical analysis and show that submodules (e.g., layers, self-attentions, and MLPs) exhibit significantly higher linearity than the overall model. Based on these findings, we propose an innovative model merging strategy that independently merges these submodules. Especially, we derive a closed-form solution for optimal merging weights grounded in the linear properties of these submodules. Experimental results demonstrate that our method consistently outperforms the standard task arithmetic approach and other established baselines across different model scales and various tasks. This result highlights the benefits of leveraging the linearity of submodules and provides a new perspective for exploring solutions for effective and practical multi-task model merging.
Loose Social-Interaction Recognition in Real-world Therapy Scenarios
Sep 30, 2024



The computer vision community has explored dyadic interactions for atomic actions such as pushing, carrying-object, etc. However, with the advancement in deep learning models, there is a need to explore more complex dyadic situations such as loose interactions. These are interactions where two people perform certain atomic activities to complete a global action irrespective of temporal synchronisation and physical engagement, like cooking-together for example. Analysing these types of dyadic-interactions has several useful applications in the medical domain for social-skills development and mental health diagnosis. To achieve this, we propose a novel dual-path architecture to capture the loose interaction between two individuals. Our model learns global abstract features from each stream via a CNNs backbone and fuses them using a new Global-Layer-Attention module based on a cross-attention strategy. We evaluate our model on real-world autism diagnoses such as our Loose-Interaction dataset, and the publicly available Autism dataset for loose interactions. Our network achieves baseline results on the Loose-Interaction and SOTA results on the Autism datasets. Moreover, we study different social interactions by experimenting on a publicly available dataset i.e. NTU-RGB+D (interactive classes from both NTU-60 and NTU-120). We have found that different interactions require different network designs. We also compare a slightly different version of our method by incorporating time information to address tight interactions achieving SOTA results.