 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategy-Supervised Autonomous Laparoscopic Camera Control via Event-Driven Graph Mining
Feb 24, 2026Autonomous laparoscopic camera control must maintain a stable and safe surgical view under rapid tool-tissue interactions while remaining interpretable to surgeons. We present a strategy-grounded framework that couples high-level vision-language inference with low-level closed-loop control. Offline, raw surgical videos are parsed into camera-relevant temporal events (e.g., interaction, working-distance deviation, and view-quality degradation) and structured as attributed event graphs. Mining these graphs yields a compact set of reusable camera-handling strategy primitives, which provide structured supervision for learning. Online, a fine-tuned Vision-Language Model (VLM) processes the live laparoscopic view to predict the dominant strategy and discrete image-based motion commands, executed by an IBVS-RCM controller under strict safety constraints; optional speech input enables intuitive human-in-the-loop conditioning. On a surgeon-annotated dataset, event parsing achieves reliable temporal localization (F1-score 0.86), and the mined strategies show strong semantic alignment with expert interpretation (cluster purity 0.81). Extensive ex vivo experiments on silicone phantoms and porcine tissues demonstrate that the proposed system outperforms junior surgeons in standardized camera-handling evaluations, reducing field-of-view centering error by 35.26% and image shaking by 62.33%, while preserving smooth motion and stable working-distance regulation.
Graph-Fused Vision-Language-Action for Policy Reasoning in Multi-Arm Robotic Manipulation
Sep 09, 2025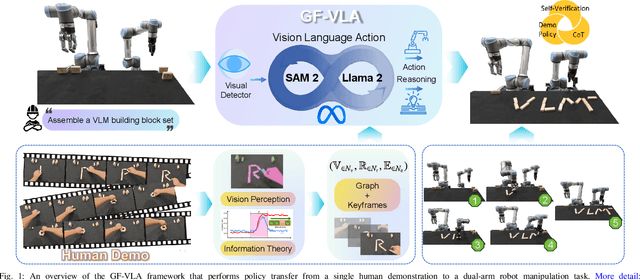
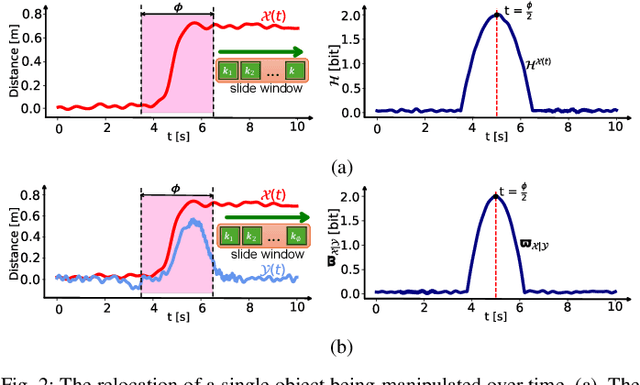
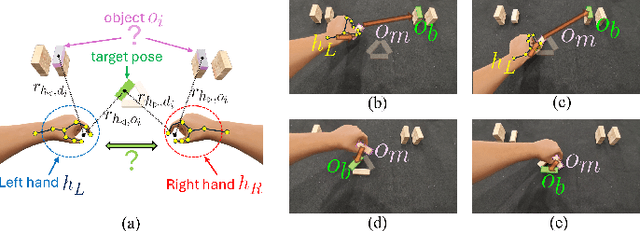
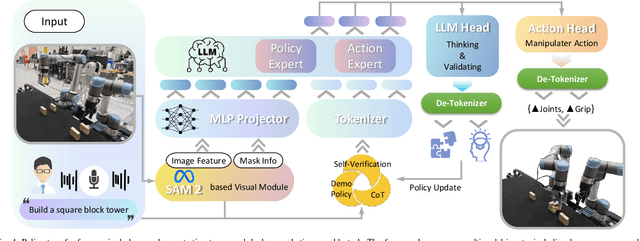
Acquiring dexterous robotic skills from human video demonstrations remains a significant challenge, largely due to conventional reliance on low-level trajectory replication, which often fails to generalize across varying objects, spatial layouts, and manipulator configurations. To address this limitation, we introduce Graph-Fused Vision-Language-Action (GF-VLA), a unified framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB-D human demonstrations. GF-VLA employs an information-theoretic approach to extract task-relevant cues, selectively highlighting critical hand-object and object-object interactions. These cues are structured into temporally ordered scene graphs, which are subsequently integrated with a language-conditioned transformer to produce hierarchical behavior trees and interpretable Cartesian motion primitives. To enhance efficiency in bimanual execution, we propose a cross-arm allocation strategy that autonomously determines gripper assignment without requiring explicit geometric modeling. We validate GF-VLA on four dual-arm block assembly benchmarks involving symbolic structure construction and spatial generalization. Empirical results demonstrate that the proposed representation achieves over 95% graph accuracy and 93% subtask segmentation, enabling the language-action planner to generate robust, interpretable task policies. When deployed on a dual-arm robot, these policies attain 94% grasp reliability, 89% placement accuracy, and 90% overall task success across stacking, letter-formation, and geometric reconfiguration tasks, evidencing strong generalization and robustness under diverse spatial and semantic variations.
Information-Theoretic Graph Fusion with Vision-Language-Action Model for Policy Reasoning and Dual Robotic Control
Aug 07, 2025Teaching robots dexterous skills from human videos remains challenging due to the reliance on low-level trajectory imitation, which fails to generalize across object types, spatial layouts, and manipulator configurations. We propose Graph-Fused Vision-Language-Action (GF-VLA), a framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB and Depth human demonstrations. GF-VLA first extracts Shannon-information-based cues to identify hands and objects with the highest task relevance, then encodes these cues into temporally ordered scene graphs that capture both hand-object and object-object interactions. These graphs are fused with a language-conditioned transformer that generates hierarchical behavior trees and interpretable Cartesian motion commands. To improve execution efficiency in bimanual settings, we further introduce a cross-hand selection policy that infers optimal gripper assignment without explicit geometric reasoning. We evaluate GF-VLA on four structured dual-arm block assembly tasks involving symbolic shape construction and spatial generalization. Experimental results show that the information-theoretic scene representation achieves over 95 percent graph accuracy and 93 percent subtask segmentation, supporting the LLM planner in generating reliable and human-readable task policies. When executed by the dual-arm robot, these policies yield 94 percent grasp success, 89 percent placement accuracy, and 90 percent overall task success across stacking, letter-building, and geometric reconfiguration scenarios, demonstrating strong generalization and robustness across diverse spatial and semantic variations.
RoboNurse-VLA: Robotic Scrub Nurse System based on Vision-Language-Action Model
Sep 29, 2024



In modern healthcare, the demand for autonomous robotic assistants has grown significantly, particularly in the operating room, where surgical tasks require precision and reliability. Robotic scrub nurses have emerged as a promising solution to improve efficiency and reduce human error during surgery. However, challenges remain in terms of accurately grasping and handing over surgical instruments, especially when dealing with complex or difficult objects in dynamic environments. In this work, we introduce a novel robotic scrub nurse system, RoboNurse-VLA, built on a Vision-Language-Action (VLA) model by integrating the Segment Anything Model 2 (SAM 2) and the Llama 2 language model. The proposed RoboNurse-VLA system enables highly precise grasping and handover of surgical instruments in real-time based on voice commands from the surgeon. Leveraging state-of-the-art vision and language models, the system can address key challenges for object detection, pose optimization, and the handling of complex and difficult-to-grasp instruments. Through extensive evaluations, RoboNurse-VLA demonstrates superior performance compared to existing models, achieving high success rates in surgical instrument handovers, even with unseen tools and challenging items. This work presents a significant step forward in autonomous surgical assistance, showcasing the potential of integrating VLA models for real-world medical applications. More details can be found at https://robonurse-vla.github.io.
Compressive Image Scanning Microscope
Jul 19, 2023



We present a novel approach to implement compressive sensing in laser scanning microscopes (LSM), specifically in image scanning microscopy (ISM), using a single-photon avalanche diode (SPAD) array detector. Our method addresses two significant limitations in applying compressive sensing to LSM: the time to compute the sampling matrix and the quality of reconstructed images. We employ a fixed sampling strategy, skipping alternate rows and columns during data acquisition, which reduces the number of points scanned by a factor of four and eliminates the need to compute different sampling matrices. By exploiting the parallel images generated by the SPAD array, we improve the quality of the reconstructed compressive-ISM images compared to standard compressive confocal LSM images. Our results demonstrate the effectiveness of our approach in producing higher-quality images with reduced data acquisition time and potential benefits in reducing photobleaching.