 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Prehensile Tool-Object Manipulation by Integrating LLM-Based Planning and Manoeuvrability-Driven Controls
Dec 09, 2024The ability to wield tools was once considered exclusive to human intelligence, but it's now known that many other animals, like crows, possess this capability. Yet, robotic systems still fall short of matching biological dexterity. In this paper, we investigate the use of Large Language Models (LLMs), tool affordances, and object manoeuvrability for non-prehensile tool-based manipulation tasks. Our novel method leverages LLMs based on scene information and natural language instructions to enable symbolic task planning for tool-object manipulation. This approach allows the system to convert the human language sentence into a sequence of feasible motion functions. We have developed a novel manoeuvrability-driven controller using a new tool affordance model derived from visual feedback. This controller helps guide the robot's tool utilization and manipulation actions, even within confined areas, using a stepping incremental approach. The proposed methodology is evaluated with experiments to prove its effectiveness under various manipulation scenarios.
RoboNurse-VLA: Robotic Scrub Nurse System based on Vision-Language-Action Model
Sep 29, 2024



In modern healthcare, the demand for autonomous robotic assistants has grown significantly, particularly in the operating room, where surgical tasks require precision and reliability. Robotic scrub nurses have emerged as a promising solution to improve efficiency and reduce human error during surgery. However, challenges remain in terms of accurately grasping and handing over surgical instruments, especially when dealing with complex or difficult objects in dynamic environments. In this work, we introduce a novel robotic scrub nurse system, RoboNurse-VLA, built on a Vision-Language-Action (VLA) model by integrating the Segment Anything Model 2 (SAM 2) and the Llama 2 language model. The proposed RoboNurse-VLA system enables highly precise grasping and handover of surgical instruments in real-time based on voice commands from the surgeon. Leveraging state-of-the-art vision and language models, the system can address key challenges for object detection, pose optimization, and the handling of complex and difficult-to-grasp instruments. Through extensive evaluations, RoboNurse-VLA demonstrates superior performance compared to existing models, achieving high success rates in surgical instrument handovers, even with unseen tools and challenging items. This work presents a significant step forward in autonomous surgical assistance, showcasing the potential of integrating VLA models for real-world medical applications. More details can be found at https://robonurse-vla.github.io.
Action Planning for Packing Long Linear Elastic Objects into Compact Boxes with Bimanual Robotic Manipulation
Oct 22, 2021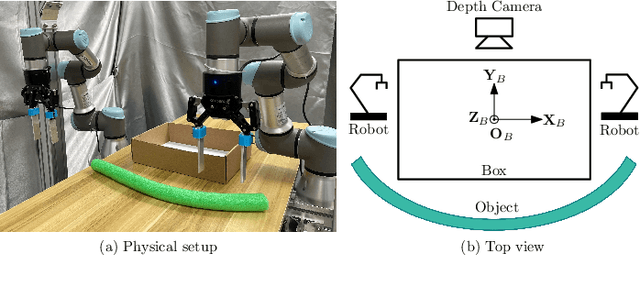
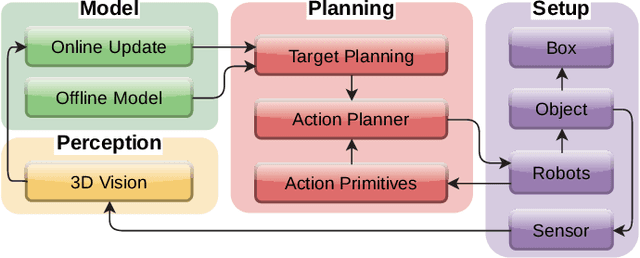
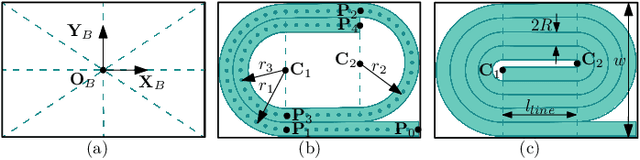
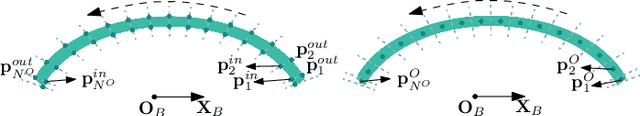
Automatic packing of objects is a critical component for efficient shipping in the Industry 4.0 era. Although robots have shown great success in pick-and-place operations with rigid products, the autonomous shaping and packing of elastic materials into compact boxes remains one of the most challenging problems in robotics; The automation of packing tasks is crucial at this moment given the accelerating shift towards e-commerce (which requires to manipulate multiple types of materials). In this paper, we propose a new action planning approach to automatically pack long linear elastic objects into common-size boxes with a bimanual robotic system. For that, we developed an efficient vision-based method to compute the objects' geometry and track its deformation in real-time and without special markers; The algorithm filters and orders the feedback point cloud that is captured by a depth sensor. A reference object model is introduced to plan the manipulation targets and to complete occluded parts of the object. Action primitives are used to construct high-level behaviors, which enable the execution of all packing steps. To validate the proposed theory, we conduct a detailed experimental study with multiple types and lengths of objects and packing boxes. The proposed methodology is original and its demonstrated manipulation capabilities have not (to the best of the authors knowledge) been previously reported in the literature.
Keypoint-Based Bimanual Shaping of Deformable Linear Objects under Environmental Constraints using Hierarchical Action Planning
Oct 18, 2021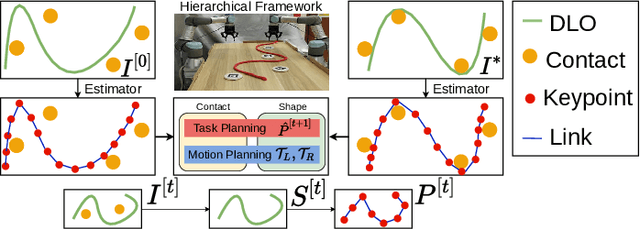
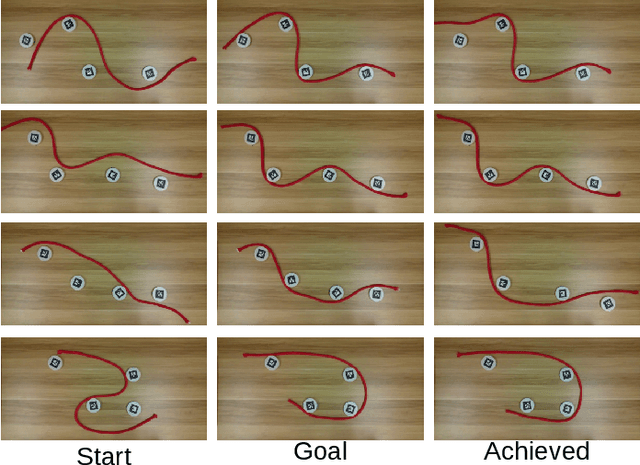
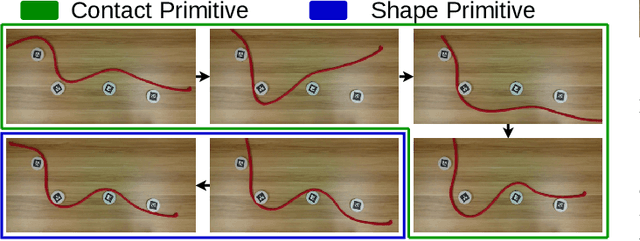
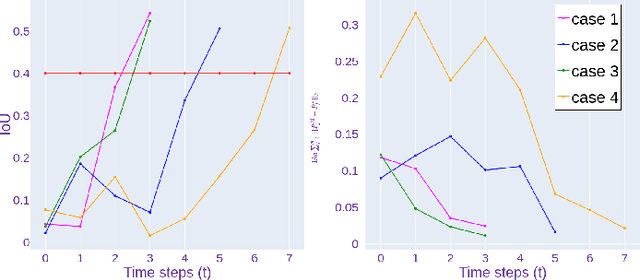
This paper addresses the problem of contact-based manipulation of deformable linear objects (DLOs) towards desired shapes with a dual-arm robotic system. To alleviate the burden of high-dimensional continuous state-action spaces, we model the DLO as a kinematic multibody system via our proposed keypoint detection network. This new perception network is trained on a synthetic labeled image dataset and transferred to real manipulation scenarios without conducting any manual annotations. Our goal-conditioned policy can efficiently learn to rearrange the configuration of the DLO based on the detected keypoints. The proposed hierarchical action framework tackles the manipulation problem in a coarse-to-fine manner (with high-level task planning and low-level motion control) by leveraging on two action primitives. The identification of deformation properties is avoided since the algorithm replans its motion after each bimanual execution. The conducted experimental results reveal that our method achieves high performance in state representation of the DLO, and is robust to uncertain environmental constraints.
Shape Control of Elastic Objects Based on Implicit Sensorimotor Models and Data-Driven Geometric Features
Jan 06, 2021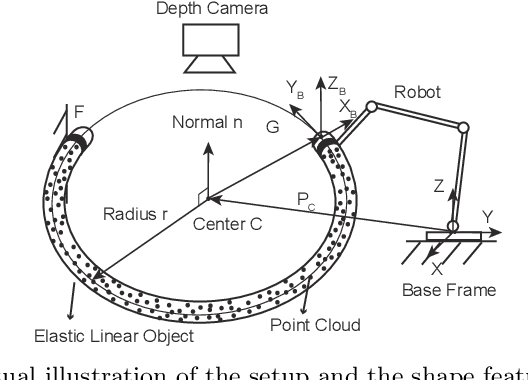
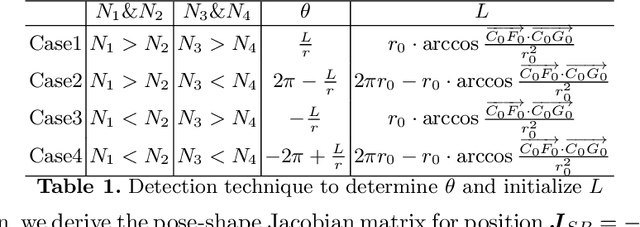
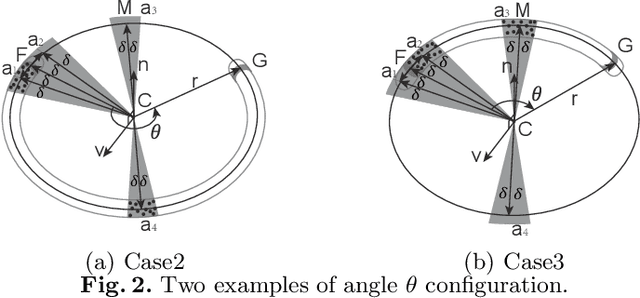
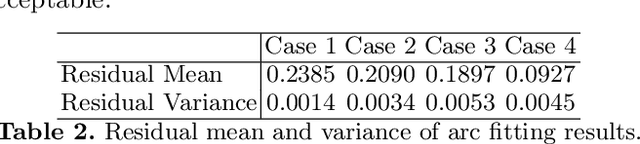
This paper proposes a general approach to design automatic controls to manipulate elastic objects into desired shapes. The object's geometric model is defined as the shape feature based on the specific task to globally describe the deformation. Raw visual feedback data is processed using classic regression methods to identify parameters of data-driven geometric models in real-time. Our proposed method is able to analytically compute a pose-shape Jacobian matrix based on implicit functions. This model is then used to derive a shape servoing controller. To validate the proposed method, we report a detailed experimental study with robotic manipulators deforming an elastic rod.
Adaptive Shape Servoing of Elastic Rods using Parameterized Regression Features and Auto-Tuning Motion Controls
Aug 16, 2020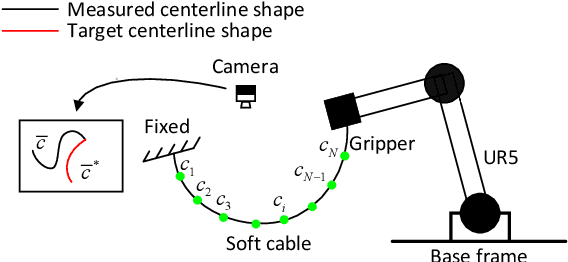
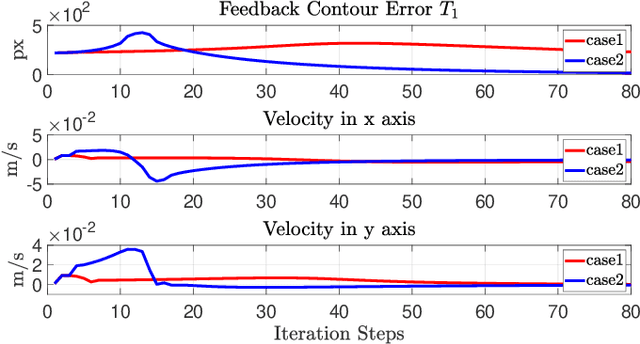
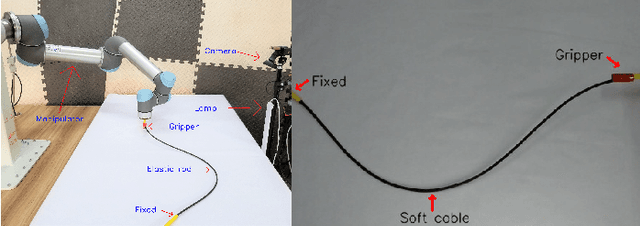

In this paper, we present a new vision-based method to control the shape of elastic rods with robot manipulators. Our new method computes parameterized regression features from online sensor measurements that enable to automatically quantify the object's configuration and establish an explicit shape servo-loop. To automatically deform the rod into a desired shape, our adaptive controller iteratively estimates the differential transformation between the robot's motion and the relative shape changes; This valuable capability allows to effectively manipulate objects with unknown mechanical models. An auto-tuning algorithm is introduced to adjust the robot's shaping motion in real-time based on optimal performance criteria. To validate the proposed theory, we present a detailed numerical and experimental study with vision-guided robotic manipulators.