 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shared Control Framework for Mobile Robots with Planning-Level Intention Prediction
Nov 12, 2025In mobile robot shared control, effectively understanding human motion intention is critical for seamless human-robot collaboration. This paper presents a novel shared control framework featuring planning-level intention prediction. A path replanning algorithm is designed to adjust the robot's desired trajectory according to inferred human intentions. To represent future motion intentions, we introduce the concept of an intention domain, which serves as a constraint for path replanning. The intention-domain prediction and path replanning problems are jointly formulated as a Markov Decision Process and solved through deep reinforcement learning. In addition, a Voronoi-based human trajectory generation algorithm is developed, allowing the model to be trained entirely in simulation without human participation or demonstration data. Extensive simulations and real-world user studies demonstrate that the proposed method significantly reduces operator workload and enhances safety, without compromising task efficiency compared with existing assistive teleoperation approaches.
FreeDriveRF: Monocular RGB Dynamic NeRF without Poses for Autonomous Driving via Point-Level Dynamic-Static Decoupling
May 14, 2025Dynamic scene reconstruction for autonomous driving enables vehicles to perceive and interpret complex scene changes more precisely. Dynamic Neural Radiance Fields (NeRFs) have recently shown promising capability in scene modeling. However, many existing methods rely heavily on accurate poses inputs and multi-sensor data, leading to increased system complexity. To address this, we propose FreeDriveRF, which reconstructs dynamic driving scenes using only sequential RGB images without requiring poses inputs. We innovatively decouple dynamic and static parts at the early sampling level using semantic supervision, mitigating image blurring and artifacts. To overcome the challenges posed by object motion and occlusion in monocular camera, we introduce a warped ray-guided dynamic object rendering consistency loss, utilizing optical flow to better constrain the dynamic modeling process. Additionally, we incorporate estimated dynamic flow to constrain the pose optimization process, improving the stability and accuracy of unbounded scene reconstruction. Extensive experiments conducted on the KITTI and Waymo datasets demonstrate the superior performance of our method in dynamic scene modeling for autonomous driving.
Learning a General Model: Folding Clothing with Topological Dynamics
Apr 29, 2025The high degrees of freedom and complex structure of garments present significant challenges for clothing manipulation. In this paper, we propose a general topological dynamics model to fold complex clothing. By utilizing the visible folding structure as the topological skeleton, we design a novel topological graph to represent the clothing state. This topological graph is low-dimensional and applied for complex clothing in various folding states. It indicates the constraints of clothing and enables predictions regarding clothing movement. To extract graphs from self-occlusion, we apply semantic segmentation to analyze the occlusion relationships and decompose the clothing structure. The decomposed structure is then combined with keypoint detection to generate the topological graph. To analyze the behavior of the topological graph, we employ an improved Graph Neural Network (GNN) to learn the general dynamics. The GNN model can predict the deformation of clothing and is employed to calculate the deformation Jacobi matrix for control. Experiments using jackets validate the algorithm's effectiveness to recognize and fold complex clothing with self-occlusion.
Efficient Robot Skill Learning with Imitation from a Single Video for Contact-Rich Fabric Manipulation
Apr 24, 2023



Classical policy search algorithms for robotics typically require performing extensive explorations, which are time-consuming and expensive to implement with real physical platforms. To facilitate the efficient learning of robot manipulation skills, in this work, we propose a new approach comprised of three modules: (1) learning of general prior knowledge with random explorations in simulation, including state representations, dynamic models, and the constrained action space of the task; (2) extraction of a state alignment-based reward function from a single demonstration video; (3) real-time optimization of the imitation policy under systematic safety constraints with sampling-based model predictive control. This solution results in an efficient one-shot imitation-from-video strategy that simplifies the learning and execution of robot skills in real applications. Specifically, we learn priors in a scene of a task family and then deploy the policy in a novel scene immediately following a single demonstration, preventing time-consuming and risky explorations in the environment. As we do not make a strong assumption of dynamic consistency between the scenes, learning priors can be conducted in simulation to avoid collecting data in real-world circumstances. We evaluate the effectiveness of our approach in the context of contact-rich fabric manipulation, which is a common scenario in industrial and domestic tasks. Detailed numerical simulations and real-world hardware experiments reveal that our method can achieve rapid skill acquisition for challenging manipulation tasks.
Action Planning for Packing Long Linear Elastic Objects into Compact Boxes with Bimanual Robotic Manipulation
Oct 22, 2021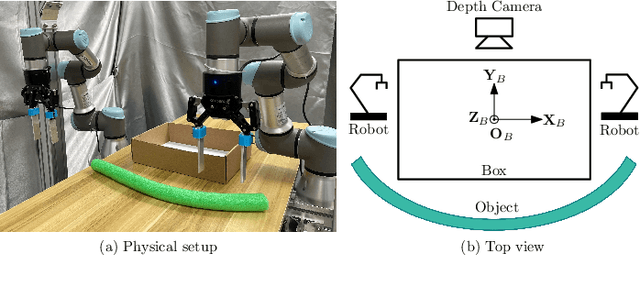
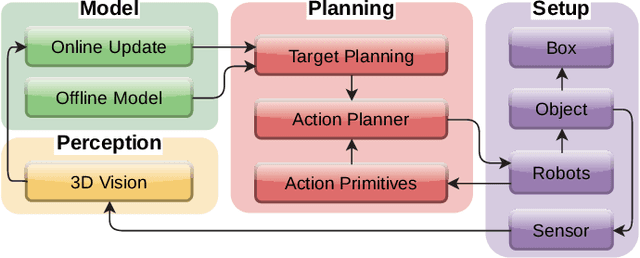
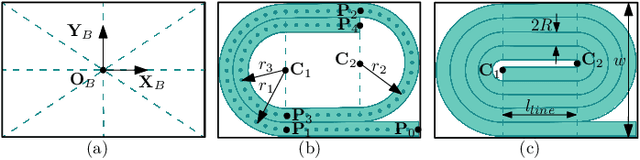
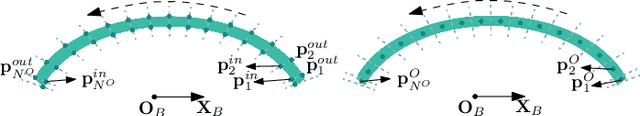
Automatic packing of objects is a critical component for efficient shipping in the Industry 4.0 era. Although robots have shown great success in pick-and-place operations with rigid products, the autonomous shaping and packing of elastic materials into compact boxes remains one of the most challenging problems in robotics; The automation of packing tasks is crucial at this moment given the accelerating shift towards e-commerce (which requires to manipulate multiple types of materials). In this paper, we propose a new action planning approach to automatically pack long linear elastic objects into common-size boxes with a bimanual robotic system. For that, we developed an efficient vision-based method to compute the objects' geometry and track its deformation in real-time and without special markers; The algorithm filters and orders the feedback point cloud that is captured by a depth sensor. A reference object model is introduced to plan the manipulation targets and to complete occluded parts of the object. Action primitives are used to construct high-level behaviors, which enable the execution of all packing steps. To validate the proposed theory, we conduct a detailed experimental study with multiple types and lengths of objects and packing boxes. The proposed methodology is original and its demonstrated manipulation capabilities have not (to the best of the authors knowledge) been previously reported in the literature.