 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld2Act: Latent Action Post-Training via Skill-Compositional World Models
Mar 11, 2026World Models (WMs) have emerged as a promising approach for post-training Vision-Language-Action (VLA) policies to improve robustness and generalization under environmental changes. However, most WM-based post-training methods rely on pixel-space supervision, making policies sensitive to pixel-level artifacts and hallucination from imperfect WM rollouts. We introduce World2Act, a post-training framework that aligns VLA actions directly with WM video-dynamics latents using a contrastive matching objective, reducing dependence on pixels. Post-training performance is tied to rollout quality, yet current WMs struggle with arbitrary-length video generation as they are mostly trained on fixed-length clips while robotic execution durations vary widely. To address this, we propose an automatic LLM-based skill-decomposition pipeline that segments high-level instructions into low-level prompts. Our pipeline produces RoboCasa-Skill and LIBERO-Skill, supporting skill-compositional WMs that remain temporally consistent across diverse task horizons. Empirically, applying World2Act to VLAs like GR00T-N1.6 and Cosmos Policy achieves state-of-the-art results on RoboCasa and LIBERO, and improves real-world performance by 6.7%, enhancing embodied agent generalization.
Choose What to Observe: Task-Aware Semantic-Geometric Representations for Visuomotor Policy
Mar 09, 2026Visuomotor policies learned from demonstrations often overfit to nuisance visual factors in raw RGB observations, resulting in brittle behavior under appearance shifts such as background changes and object recoloring. We propose a task-aware observation interface that canonicalizes visual input into a shared representation, improving robustness to out-of-distribution (OOD) appearance changes without modifying or fine-tuning the policy. Given an RGB image and an open-vocabulary specification of task-relevant entities, we use SAM3 to segment the target object and robot/gripper. We construct an L0 observation by repainting segmented entities with predefined semantic colors on a constant background. For tasks requiring stronger geometric cues, we further inject monocular depth from Depth Anything 3 into the segmented regions via depth-guided overwrite, yielding a unified semantic--geometric observation (L1) that remains a standard 3-channel, image-like input. We evaluate on RoboMimic (Lift), ManiSkill YCB grasping under clutter, four RLBench tasks under controlled appearance shifts, and two real-world Franka tasks (ReachX and CloseCabinet). Across benchmarks and policy backbones (Flow Matching Policy and SmolVLA), our interface preserves in-distribution performance while substantially improving robustness under OOD visual shifts.
Imagination at Inference: Synthesizing In-Hand Views for Robust Visuomotor Policy Inference
Sep 19, 2025Visual observations from different viewpoints can significantly influence the performance of visuomotor policies in robotic manipulation. Among these, egocentric (in-hand) views often provide crucial information for precise control. However, in some applications, equipping robots with dedicated in-hand cameras may pose challenges due to hardware constraints, system complexity, and cost. In this work, we propose to endow robots with imaginative perception - enabling them to 'imagine' in-hand observations from agent views at inference time. We achieve this via novel view synthesis (NVS), leveraging a fine-tuned diffusion model conditioned on the relative pose between the agent and in-hand views cameras. Specifically, we apply LoRA-based fine-tuning to adapt a pretrained NVS model (ZeroNVS) to the robotic manipulation domain. We evaluate our approach on both simulation benchmarks (RoboMimic and MimicGen) and real-world experiments using a Unitree Z1 robotic arm for a strawberry picking task. Results show that synthesized in-hand views significantly enhance policy inference, effectively recovering the performance drop caused by the absence of real in-hand cameras. Our method offers a scalable and hardware-light solution for deploying robust visuomotor policies, highlighting the potential of imaginative visual reasoning in embodied agents.
Towards Safe Imitation Learning via Potential Field-Guided Flow Matching
Aug 12, 2025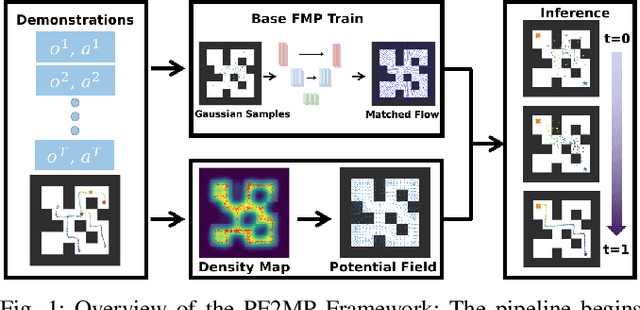
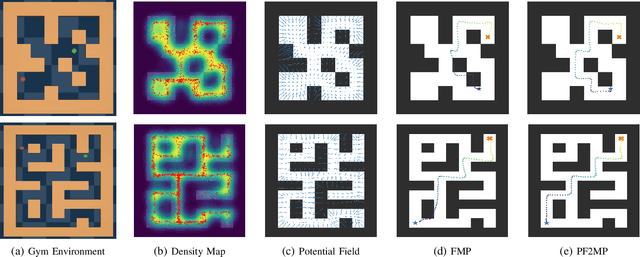
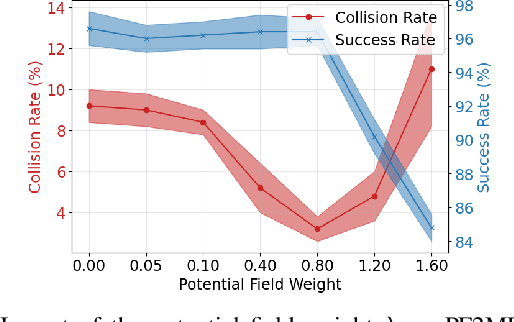

Deep generative models, particularly diffusion and flow matching models, have recently shown remarkable potential in learning complex policies through imitation learning. However, the safety of generated motions remains overlooked, particularly in complex environments with inherent obstacles. In this work, we address this critical gap by proposing Potential Field-Guided Flow Matching Policy (PF2MP), a novel approach that simultaneously learns task policies and extracts obstacle-related information, represented as a potential field, from the same set of successful demonstrations. During inference, PF2MP modulates the flow matching vector field via the learned potential field, enabling safe motion generation. By leveraging these complementary fields, our approach achieves improved safety without compromising task success across diverse environments, such as navigation tasks and robotic manipulation scenarios. We evaluate PF2MP in both simulation and real-world settings, demonstrating its effectiveness in task space and joint space control. Experimental results demonstrate that PF2MP enhances safety, achieving a significant reduction of collisions compared to baseline policies. This work paves the way for safer motion generation in unstructured and obstaclerich environments.
Instruction-Augmented Long-Horizon Planning: Embedding Grounding Mechanisms in Embodied Mobile Manipulation
Mar 11, 2025Enabling humanoid robots to perform long-horizon mobile manipulation planning in real-world environments based on embodied perception and comprehension abilities has been a longstanding challenge. With the recent rise of large language models (LLMs), there has been a notable increase in the development of LLM-based planners. These approaches either utilize human-provided textual representations of the real world or heavily depend on prompt engineering to extract such representations, lacking the capability to quantitatively understand the environment, such as determining the feasibility of manipulating objects. To address these limitations, we present the Instruction-Augmented Long-Horizon Planning (IALP) system, a novel framework that employs LLMs to generate feasible and optimal actions based on real-time sensor feedback, including grounded knowledge of the environment, in a closed-loop interaction. Distinct from prior works, our approach augments user instructions into PDDL problems by leveraging both the abstract reasoning capabilities of LLMs and grounding mechanisms. By conducting various real-world long-horizon tasks, each consisting of seven distinct manipulatory skills, our results demonstrate that the IALP system can efficiently solve these tasks with an average success rate exceeding 80%. Our proposed method can operate as a high-level planner, equipping robots with substantial autonomy in unstructured environments through the utilization of multi-modal sensor inputs.
* 17 pages, 11 figures
Non-Prehensile Tool-Object Manipulation by Integrating LLM-Based Planning and Manoeuvrability-Driven Controls
Dec 09, 2024The ability to wield tools was once considered exclusive to human intelligence, but it's now known that many other animals, like crows, possess this capability. Yet, robotic systems still fall short of matching biological dexterity. In this paper, we investigate the use of Large Language Models (LLMs), tool affordances, and object manoeuvrability for non-prehensile tool-based manipulation tasks. Our novel method leverages LLMs based on scene information and natural language instructions to enable symbolic task planning for tool-object manipulation. This approach allows the system to convert the human language sentence into a sequence of feasible motion functions. We have developed a novel manoeuvrability-driven controller using a new tool affordance model derived from visual feedback. This controller helps guide the robot's tool utilization and manipulation actions, even within confined areas, using a stepping incremental approach. The proposed methodology is evaluated with experiments to prove its effectiveness under various manipulation scenarios.
Implicit Subgoal Planning with Variational Autoencoders for Long-Horizon Sparse Reward Robotic Tasks
Dec 25, 2023



The challenges inherent to long-horizon tasks in robotics persist due to the typical inefficient exploration and sparse rewards in traditional reinforcement learning approaches. To alleviate these challenges, we introduce a novel algorithm, Variational Autoencoder-based Subgoal Inference (VAESI), to accomplish long-horizon tasks through a divide-and-conquer manner. VAESI consists of three components: a Variational Autoencoder (VAE)-based Subgoal Generator, a Hindsight Sampler, and a Value Selector. The VAE-based Subgoal Generator draws inspiration from the human capacity to infer subgoals and reason about the final goal in the context of these subgoals. It is composed of an explicit encoder model, engineered to generate subgoals, and an implicit decoder model, designed to enhance the quality of the generated subgoals by predicting the final goal. Additionally, the Hindsight Sampler selects valid subgoals from an offline dataset to enhance the feasibility of the generated subgoals. The Value Selector utilizes the value function in reinforcement learning to filter the optimal subgoals from subgoal candidates. To validate our method, we conduct several long-horizon tasks in both simulation and the real world, including one locomotion task and three manipulation tasks. The obtained quantitative and qualitative data indicate that our approach achieves promising performance compared to other baseline methods. These experimental results can be seen in the website \url{https://sites.google.com/view/vaesi/home}.
Learning Rhythmic Trajectories with Geometric Constraints for Laser-Based Skincare Procedures
Dec 21, 2023The increasing deployment of robots has significantly enhanced the automation levels across a wide and diverse range of industries. This paper investigates the automation challenges of laser-based dermatology procedures in the beauty industry; This group of related manipulation tasks involves delivering energy from a cosmetic laser onto the skin with repetitive patterns. To automate this procedure, we propose to use a robotic manipulator and endow it with the dexterity of a skilled dermatology practitioner through a learning-from-demonstration framework. To ensure that the cosmetic laser can properly deliver the energy onto the skin surface of an individual, we develop a novel structured prediction-based imitation learning algorithm with the merit of handling geometric constraints. Notably, our proposed algorithm effectively tackles the imitation challenges associated with quasi-periodic motions, a common feature of many laser-based cosmetic tasks. The conducted real-world experiments illustrate the performance of our robotic beautician in mimicking realistic dermatological procedures; Our new method is shown to not only replicate the rhythmic movements from the provided demonstrations but also to adapt the acquired skills to previously unseen scenarios and subjects.
A Structured Prediction Approach for Robot Imitation Learning
Sep 26, 2023We propose a structured prediction approach for robot imitation learning from demonstrations. Among various tools for robot imitation learning, supervised learning has been observed to have a prominent role. Structured prediction is a form of supervised learning that enables learning models to operate on output spaces with complex structures. Through the lens of structured prediction, we show how robots can learn to imitate trajectories belonging to not only Euclidean spaces but also Riemannian manifolds. Exploiting ideas from information theory, we propose a class of loss functions based on the f-divergence to measure the information loss between the demonstrated and reproduced probabilistic trajectories. Different types of f-divergence will result in different policies, which we call imitation modes. Furthermore, our approach enables the incorporation of spatial and temporal trajectory modulation, which is necessary for robots to be adaptive to the change in working conditions. We benchmark our algorithm against state-of-the-art methods in terms of trajectory reproduction and adaptation. The quantitative evaluation shows that our approach outperforms other algorithms regarding both accuracy and efficiency. We also report real-world experimental results on learning manifold trajectories in a polishing task with a KUKA LWR robot arm, illustrating the effectiveness of our algorithmic framework.
PSO-Based Optimal Coverage Path Planning for Surface Defect Inspection of 3C Components with a Robotic Line Scanner
Jul 10, 2023



The automatic inspection of surface defects is an important task for quality control in the computers, communications, and consumer electronics (3C) industry. Conventional devices for defect inspection (viz. line-scan sensors) have a limited field of view, thus, a robot-aided defect inspection system needs to scan the object from multiple viewpoints. Optimally selecting the robot's viewpoints and planning a path is regarded as coverage path planning (CPP), a problem that enables inspecting the object's complete surface while reducing the scanning time and avoiding misdetection of defects. However, the development of CPP strategies for robotic line scanners has not been sufficiently studied by researchers. To fill this gap in the literature, in this paper, we present a new approach for robotic line scanners to detect surface defects of 3C free-form objects automatically. Our proposed solution consists of generating a local path by a new hybrid region segmentation method and an adaptive planning algorithm to ensure the coverage of the complete object surface. An optimization method for the global path sequence is developed to maximize the scanning efficiency. To verify our proposed methodology, we conduct detailed simulation-based and experimental studies on various free-form workpieces, and compare its performance with a state-of-the-art solution. The reported results demonstrate the feasibility and effectiveness of our approach.