 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRose-SQL: Role-State Evolution Guided Structured Reasoning for Multi-Turn Text-to-SQL
May 05, 2026Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought have demonstrated remarkable capabilities in code generation and mathematical reasoning. However, their potential in multi-turn Text-to-SQL tasks remains largely underexplored. Existing approaches typically rely on unstable API-based inference or require expensive fine-tuning on small-scale models. In this work, we present Rose-SQL, a training-free framework that leverages small-scale LRMs through in-context learning to enable accurate context-dependent parsing. We introduce the Role-State, a fine-grained representation that bridges the structural gap between schema linking and SQL generation by serving as a structural blueprint. To handle conversational dependencies, Rose-SQL traces the evolution of Role-State through historical context via structural isomorphism checks, guiding the model to infer the possible SQL composition for the current question through verified interaction trajectories. Experiments on the SParC and CoSQL benchmarks show that, within the Qwen3 series, Rose-SQL outperforms in-context learning baselines at the 4B scale and substantially surpasses state-of-the-art fine-tuned models at the 8B and 14B scales, while showing consistent gains on additional reasoning backbones.
Think Proprioceptively: Embodied Visual Reasoning for VLA Manipulation
Feb 06, 2026Vision-language-action (VLA) models typically inject proprioception only as a late conditioning signal, which prevents robot state from shaping instruction understanding and from influencing which visual tokens are attended throughout the policy. We introduce ThinkProprio, which converts proprioception into a sequence of text tokens in the VLM embedding space and fuses them with the task instruction at the input. This early fusion lets embodied state participate in subsequent visual reasoning and token selection, biasing computation toward action-critical evidence while suppressing redundant visual tokens. In a systematic ablation over proprioception encoding, state entry point, and action-head conditioning, we find that text tokenization is more effective than learned projectors, and that retaining roughly 15% of visual tokens can match the performance of using the full token set. Across CALVIN, LIBERO, and real-world manipulation, ThinkProprio matches or improves over strong baselines while reducing end-to-end inference latency over 50%.
HuBE: Cross-Embodiment Human-like Behavior Execution for Humanoid Robots
Aug 26, 2025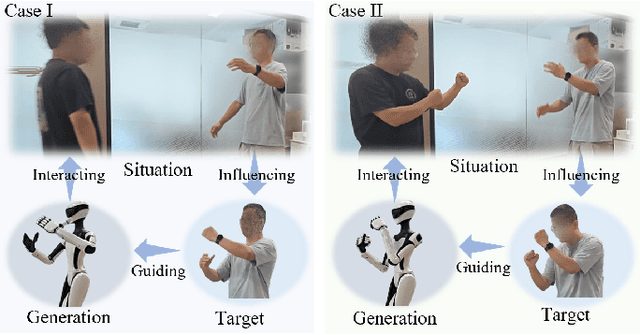
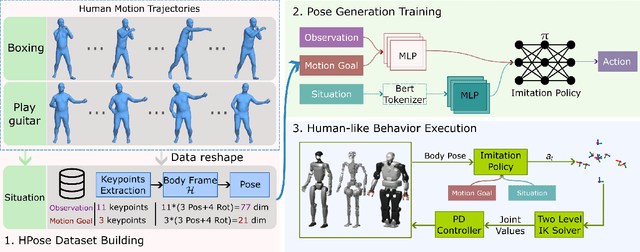

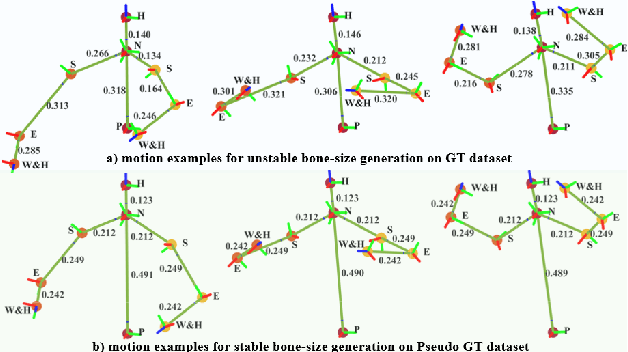
Achieving both behavioral similarity and appropriateness in human-like motion generation for humanoid robot remains an open challenge, further compounded by the lack of cross-embodiment adaptability. To address this problem, we propose HuBE, a bi-level closed-loop framework that integrates robot state, goal poses, and contextual situations to generate human-like behaviors, ensuring both behavioral similarity and appropriateness, and eliminating structural mismatches between motion generation and execution. To support this framework, we construct HPose, a context-enriched dataset featuring fine-grained situational annotations. Furthermore, we introduce a bone scaling-based data augmentation strategy that ensures millimeter-level compatibility across heterogeneous humanoid robots. Comprehensive evaluations on multiple commercial platforms demonstrate that HuBE significantly improves motion similarity, behavioral appropriateness, and computational efficiency over state-of-the-art baselines, establishing a solid foundation for transferable and human-like behavior execution across diverse humanoid robots.
Instruction-Augmented Long-Horizon Planning: Embedding Grounding Mechanisms in Embodied Mobile Manipulation
Mar 11, 2025Enabling humanoid robots to perform long-horizon mobile manipulation planning in real-world environments based on embodied perception and comprehension abilities has been a longstanding challenge. With the recent rise of large language models (LLMs), there has been a notable increase in the development of LLM-based planners. These approaches either utilize human-provided textual representations of the real world or heavily depend on prompt engineering to extract such representations, lacking the capability to quantitatively understand the environment, such as determining the feasibility of manipulating objects. To address these limitations, we present the Instruction-Augmented Long-Horizon Planning (IALP) system, a novel framework that employs LLMs to generate feasible and optimal actions based on real-time sensor feedback, including grounded knowledge of the environment, in a closed-loop interaction. Distinct from prior works, our approach augments user instructions into PDDL problems by leveraging both the abstract reasoning capabilities of LLMs and grounding mechanisms. By conducting various real-world long-horizon tasks, each consisting of seven distinct manipulatory skills, our results demonstrate that the IALP system can efficiently solve these tasks with an average success rate exceeding 80%. Our proposed method can operate as a high-level planner, equipping robots with substantial autonomy in unstructured environments through the utilization of multi-modal sensor inputs.
* 17 pages, 11 figures
VIPS-Odom: Visual-Inertial Odometry Tightly-coupled with Parking Slots for Autonomous Parking
Jul 06, 2024Precise localization is of great importance for autonomous parking task since it provides service for the downstream planning and control modules, which significantly affects the system performance. For parking scenarios, dynamic lighting, sparse textures, and the instability of global positioning system (GPS) signals pose challenges for most traditional localization methods. To address these difficulties, we propose VIPS-Odom, a novel semantic visual-inertial odometry framework for underground autonomous parking, which adopts tightly-coupled optimization to fuse measurements from multi-modal sensors and solves odometry. Our VIPS-Odom integrates parking slots detected from the synthesized bird-eye-view (BEV) image with traditional feature points in the frontend, and conducts tightly-coupled optimization with joint constraints introduced by measurements from the inertial measurement unit, wheel speed sensor and parking slots in the backend. We develop a multi-object tracking framework to robustly track parking slots' states. To prove the superiority of our method, we equip an electronic vehicle with related sensors and build an experimental platform based on ROS2 system. Extensive experiments demonstrate the efficacy and advantages of our method compared with other baselines for parking scenarios.
Implicit Subgoal Planning with Variational Autoencoders for Long-Horizon Sparse Reward Robotic Tasks
Dec 25, 2023



The challenges inherent to long-horizon tasks in robotics persist due to the typical inefficient exploration and sparse rewards in traditional reinforcement learning approaches. To alleviate these challenges, we introduce a novel algorithm, Variational Autoencoder-based Subgoal Inference (VAESI), to accomplish long-horizon tasks through a divide-and-conquer manner. VAESI consists of three components: a Variational Autoencoder (VAE)-based Subgoal Generator, a Hindsight Sampler, and a Value Selector. The VAE-based Subgoal Generator draws inspiration from the human capacity to infer subgoals and reason about the final goal in the context of these subgoals. It is composed of an explicit encoder model, engineered to generate subgoals, and an implicit decoder model, designed to enhance the quality of the generated subgoals by predicting the final goal. Additionally, the Hindsight Sampler selects valid subgoals from an offline dataset to enhance the feasibility of the generated subgoals. The Value Selector utilizes the value function in reinforcement learning to filter the optimal subgoals from subgoal candidates. To validate our method, we conduct several long-horizon tasks in both simulation and the real world, including one locomotion task and three manipulation tasks. The obtained quantitative and qualitative data indicate that our approach achieves promising performance compared to other baseline methods. These experimental results can be seen in the website \url{https://sites.google.com/view/vaesi/home}.
ApproBiVT: Lead ASR Models to Generalize Better Using Approximated Bias-Variance Tradeoff Guided Early Stopping and Checkpoint Averaging
Aug 05, 2023
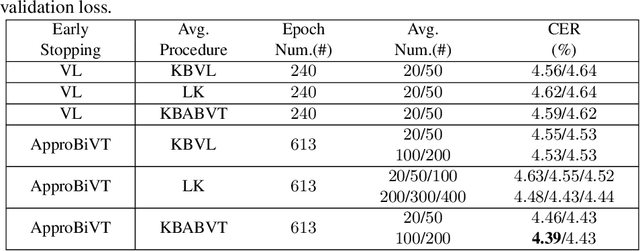

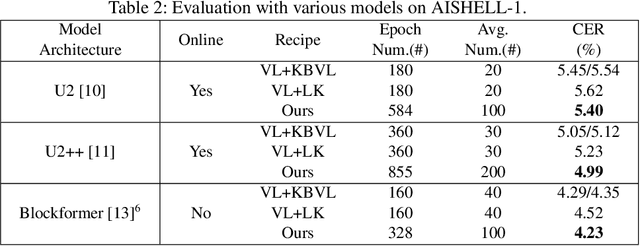
The conventional recipe for Automatic Speech Recognition (ASR) models is to 1) train multiple checkpoints on a training set while relying on a validation set to prevent overfitting using early stopping and 2) average several last checkpoints or that of the lowest validation losses to obtain the final model. In this paper, we rethink and update the early stopping and checkpoint averaging from the perspective of the bias-variance tradeoff. Theoretically, the bias and variance represent the fitness and variability of a model and the tradeoff of them determines the overall generalization error. But, it's impractical to evaluate them precisely. As an alternative, we take the training loss and validation loss as proxies of bias and variance and guide the early stopping and checkpoint averaging using their tradeoff, namely an Approximated Bias-Variance Tradeoff (ApproBiVT). When evaluating with advanced ASR models, our recipe provides 2.5%-3.7% and 3.1%-4.6% CER reduction on the AISHELL-1 and AISHELL-2, respectively.
P-vectors: A Parallel-Coupled TDNN/Transformer Network for Speaker Verification
May 25, 2023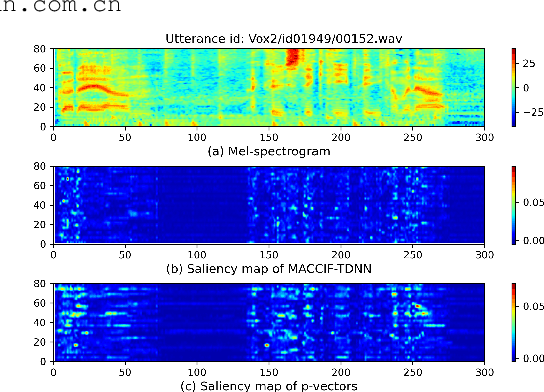
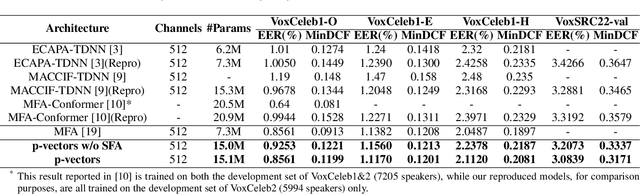
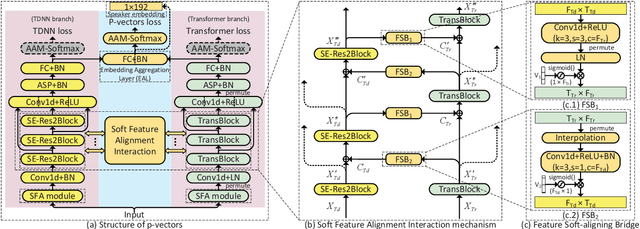

Typically, the Time-Delay Neural Network (TDNN) and Transformer can serve as a backbone for Speaker Verification (SV). Both of them have advantages and disadvantages from the perspective of global and local feature modeling. How to effectively integrate these two style features is still an open issue. In this paper, we explore a Parallel-coupled TDNN/Transformer Network (p-vectors) to replace the serial hybrid networks. The p-vectors allows TDNN and Transformer to learn the complementary information from each other through Soft Feature Alignment Interaction (SFAI) under the premise of preserving local and global features. Also, p-vectors uses the Spatial Frequency-channel Attention (SFA) to enhance the spatial interdependence modeling for input features. Finally, the outputs of dual branches of p-vectors are combined by Embedding Aggregation Layer (EAL). Experiments show that p-vectors outperforms MACCIF-TDNN and MFA-Conformer with relative improvements of 11.5% and 13.9% in EER on VoxCeleb1-O.
Sequentially Sampled Chunk Conformer for Streaming End-to-End ASR
Nov 22, 2022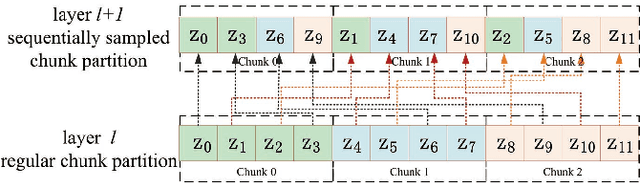
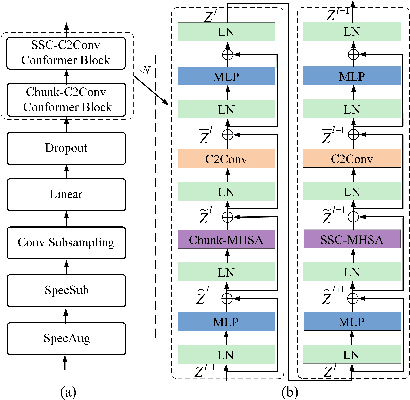
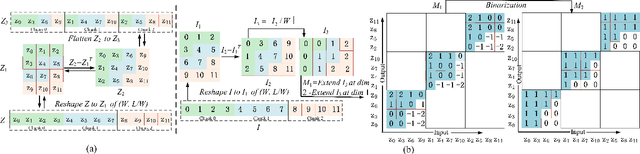
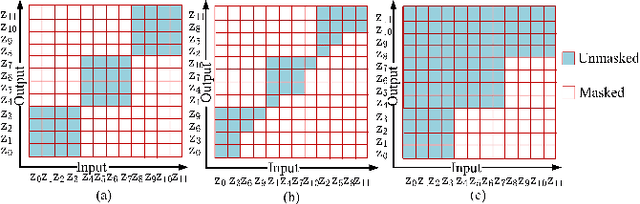
This paper presents an in-depth study on a Sequentially Sampled Chunk Conformer, SSC-Conformer, for streaming End-to-End (E2E) ASR. The SSC-Conformer first demonstrates the significant performance gains from using the sequentially sampled chunk-wise multi-head self-attention (SSC-MHSA) in the Conformer encoder by allowing efficient cross-chunk interactions while keeping linear complexities. Furthermore, it explores taking advantage of chunked convolution to make use of the chunk-wise future context and integrates with casual convolution in the convolution layers to further reduce CER. We verify the proposed SSC-Conformer on the AISHELL-1 benchmark and experimental results show that a state-of-the-art performance for streaming E2E ASR is achieved with CER 5.33% without LM rescoring. And, owing to its linear complexity, the SSC-Conformer can train with large batch sizes and infer more efficiently.
A Dual-Arm Collaborative Framework for Dexterous Manipulation in Unstructured Environments with Contrastive Planning
Sep 13, 2022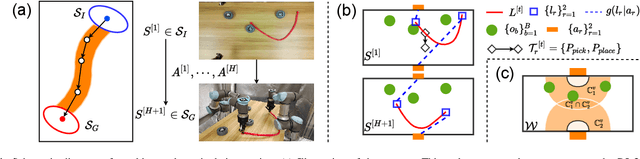
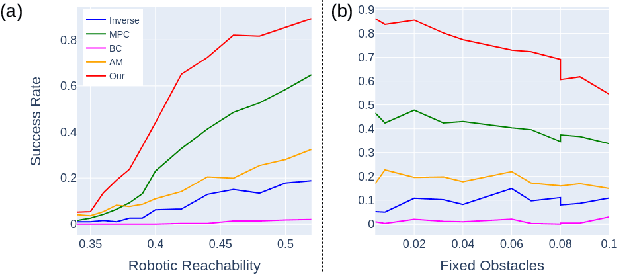
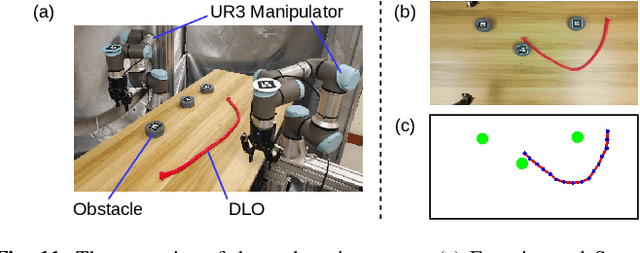
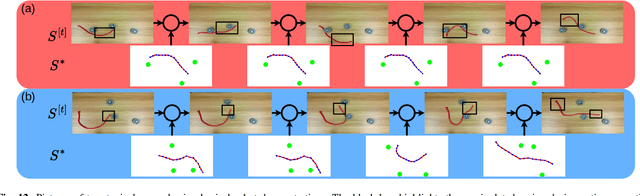
Most object manipulation strategies for robots are based on the assumption that the object is rigid (i.e., with fixed geometry) and the goal's details have been fully specified (e.g., the exact target pose). However, there are many tasks that involve spatial relations in human environments where these conditions may be hard to satisfy, e.g., bending and placing a cable inside an unknown container. To develop advanced robotic manipulation capabilities in unstructured environments that avoid these assumptions, we propose a novel long-horizon framework that exploits contrastive planning in finding promising collaborative actions. Using simulation data collected by random actions, we learn an embedding model in a contrastive manner that encodes the spatio-temporal information from successful experiences, which facilitates the subgoal planning through clustering in the latent space. Based on the keypoint correspondence-based action parameterization, we design a leader-follower control scheme for the collaboration between dual arms. All models of our policy are automatically trained in simulation and can be directly transferred to real-world environments. To validate the proposed framework, we conduct a detailed experimental study on a complex scenario subject to environmental and reachability constraints in both simulation and real environments.