 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShifted Chunk Encoder for Transformer Based Streaming End-to-End ASR
Paper and Code
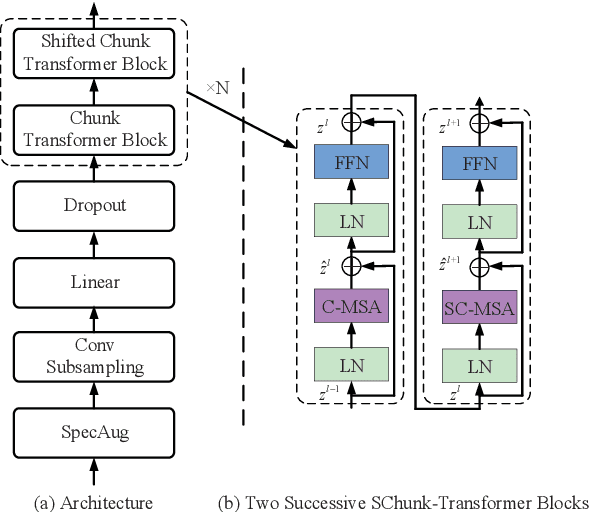
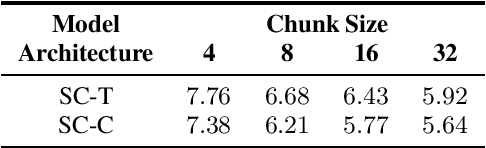
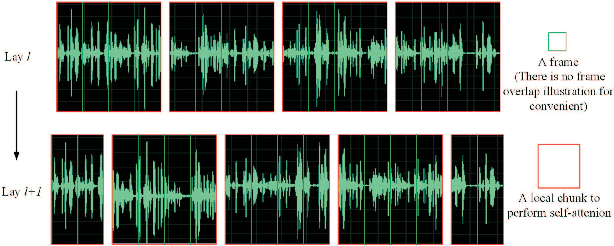

Currently, there are mainly three Transformer encoder based streaming End to End (E2E) Automatic Speech Recognition (ASR) approaches, namely time-restricted methods, chunk-wise methods, and memory based methods. However, all of them have some limitations in aspects of global context modeling, linear computational complexity, and model parallelism. In this work, we aim to build a single model to achieve the benefits of all the three aspects for streaming E2E ASR. Particularly, we propose to use a shifted chunk mechanism instead of the conventional chunk mechanism for streaming Transformer and Conformer. This shifted chunk mechanism can significantly enhance modeling power through allowing chunk self-attention to capture global context across local chunks, while keeping linear computational complexity and parallel trainable. We name the Shifted Chunk Transformer and Conformer as SChunk-Transofromer and SChunk-Conformer, respectively. And we verify their performance on the widely used AISHELL-1 benckmark. Experiments show that the SChunk-Transformer and SChunk-Conformer achieve CER 6.43% and 5.77%, respectively. That surpasses the existing chunk-wise and memory based methods by a large margin, and is competitive even compared with the state-of-the-art time-restricted methods which have quadratic computational complexity.