 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Permutation for Structured Sparsity on Transformer Models
Jan 30, 2026Structured sparsity has emerged as a popular model pruning technique, widely adopted in various architectures, including CNNs, Transformer models, and especially large language models (LLMs) in recent years. A promising direction to further improve post-pruning performance is weight permutation, which reorders model weights into patterns more amenable to pruning. However, the exponential growth of the permutation search space with the scale of Transformer architectures forces most methods to rely on greedy or heuristic algorithms, limiting the effectiveness of reordering. In this work, we propose a novel end-to-end learnable permutation framework. Our method introduces a learnable permutation cost matrix to quantify the cost of swapping any two input channels of a given weight matrix, a differentiable bipartite matching solver to obtain the optimal binary permutation matrix given a cost matrix, and a sparsity optimization loss function to directly optimize the permutation operator. We extensively validate our approach on vision and language Transformers, demonstrating that our method achieves state-of-the-art permutation results for structured sparsity.
DiffBench Meets DiffAgent: End-to-End LLM-Driven Diffusion Acceleration Code Generation
Jan 06, 2026Diffusion models have achieved remarkable success in image and video generation. However, their inherently multiple step inference process imposes substantial computational overhead, hindering real-world deployment. Accelerating diffusion models is therefore essential, yet determining how to combine multiple model acceleration techniques remains a significant challenge. To address this issue, we introduce a framework driven by large language models (LLMs) for automated acceleration code generation and evaluation. First, we present DiffBench, a comprehensive benchmark that implements a three stage automated evaluation pipeline across diverse diffusion architectures, optimization combinations and deployment scenarios. Second, we propose DiffAgent, an agent that generates optimal acceleration strategies and codes for arbitrary diffusion models. DiffAgent employs a closed-loop workflow in which a planning component and a debugging component iteratively refine the output of a code generation component, while a genetic algorithm extracts performance feedback from the execution environment to guide subsequent code refinements. We provide a detailed explanation of the DiffBench construction and the design principles underlying DiffAgent. Extensive experiments show that DiffBench offers a thorough evaluation of generated codes and that DiffAgent significantly outperforms existing LLMs in producing effective diffusion acceleration strategies.
CD4LM: Consistency Distillation and aDaptive Decoding for Diffusion Language Models
Jan 05, 2026Autoregressive large language models achieve strong results on many benchmarks, but decoding remains fundamentally latency-limited by sequential dependence on previously generated tokens. Diffusion language models (DLMs) promise parallel generation but suffer from a fundamental static-to-dynamic misalignment: Training optimizes local transitions under fixed schedules, whereas efficient inference requires adaptive "long-jump" refinements through unseen states. Our goal is to enable highly parallel decoding for DLMs with low number of function evaluations while preserving generation quality. To achieve this, we propose CD4LM, a framework that decouples training from inference via Discrete-Space Consistency Distillation (DSCD) and Confidence-Adaptive Decoding (CAD). Unlike standard objectives, DSCD trains a student to be trajectory-invariant, mapping diverse noisy states directly to the clean distribution. This intrinsic robustness enables CAD to dynamically allocate compute resources based on token confidence, aggressively skipping steps without the quality collapse typical of heuristic acceleration. On GSM8K, CD4LM matches the LLaDA baseline with a 5.18x wall-clock speedup; across code and math benchmarks, it strictly dominates the accuracy-efficiency Pareto frontier, achieving a 3.62x mean speedup while improving average accuracy. Code is available at https://github.com/yihao-liang/CDLM
FarSkip-Collective: Unhobbling Blocking Communication in Mixture of Experts Models
Nov 14, 2025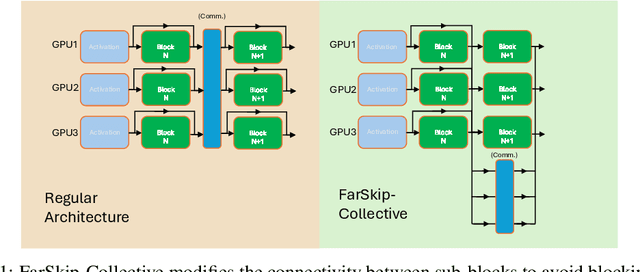
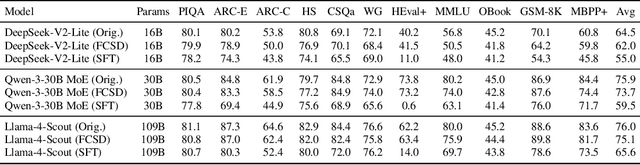
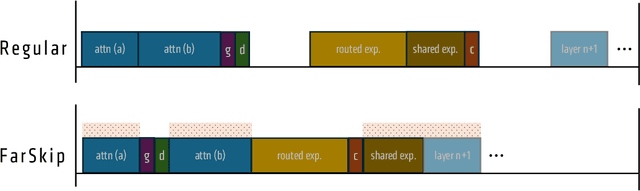
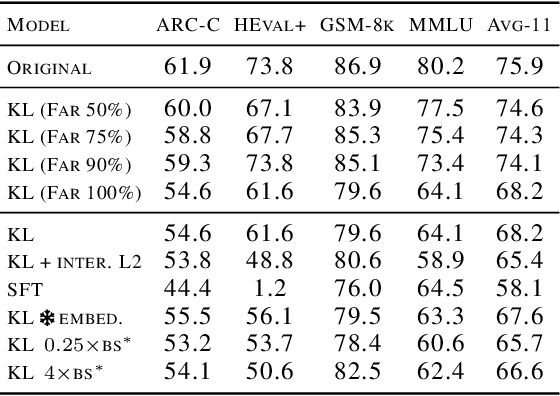
Blocking communication presents a major hurdle in running MoEs efficiently in distributed settings. To address this, we present FarSkip-Collective which modifies the architecture of modern models to enable overlapping of their computation with communication. Our approach modifies the architecture to skip connections in the model and it is unclear a priori whether the modified model architecture can remain as capable, especially for large state-of-the-art models and while modifying all of the model layers. We answer this question in the affirmative and fully convert a series of state-of-the-art models varying from 16B to 109B parameters to enable overlapping of their communication while achieving accuracy on par with their original open-source releases. For example, we convert Llama 4 Scout (109B) via self-distillation and achieve average accuracy within 1% of its instruction tuned release averaged across a wide range of downstream evaluations. In addition to demonstrating retained accuracy of the large modified models, we realize the benefits of FarSkip-Collective through optimized implementations that explicitly overlap communication with computation, accelerating both training and inference in existing frameworks.
Instella: Fully Open Language Models with Stellar Performance
Nov 14, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks, yet the majority of high-performing models remain closed-source or partially open, limiting transparency and reproducibility. In this work, we introduce Instella, a family of fully open three billion parameter language models trained entirely on openly available data and codebase. Powered by AMD Instinct MI300X GPUs, Instella is developed through large-scale pre-training, general-purpose instruction tuning, and alignment with human preferences. Despite using substantially fewer pre-training tokens than many contemporaries, Instella achieves state-of-the-art results among fully open models and is competitive with leading open-weight models of comparable size. We further release two specialized variants: Instella-Long, capable of handling context lengths up to 128K tokens, and Instella-Math, a reasoning-focused model enhanced through supervised fine-tuning and reinforcement learning on mathematical tasks. Together, these contributions establish Instella as a transparent, performant, and versatile alternative for the community, advancing the goal of open and reproducible language modeling research.
Learning from Online Videos at Inference Time for Computer-Use Agents
Nov 06, 2025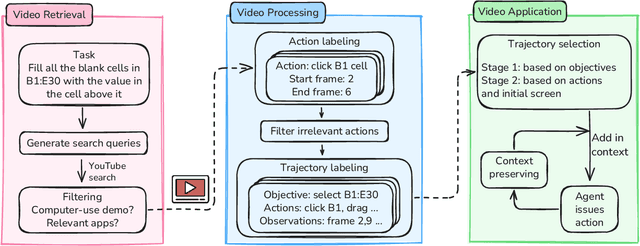



Computer-use agents can operate computers and automate laborious tasks, but despite recent rapid progress, they still lag behind human users, especially when tasks require domain-specific procedural knowledge about particular applications, platforms, and multi-step workflows. Humans can bridge this gap by watching video tutorials: we search, skim, and selectively imitate short segments that match our current subgoal. In this paper, we study how to enable computer-use agents to learn from online videos at inference time effectively. We propose a framework that retrieves and filters tutorial videos, converts them into structured demonstration trajectories, and dynamically selects trajectories as in-context guidance during execution. Particularly, using a VLM, we infer UI actions, segment videos into short subsequences of actions, and assign each subsequence a textual objective. At inference time, a two-stage selection mechanism dynamically chooses a single trajectory to add in context at each step, focusing the agent on the most helpful local guidance for its next decision. Experiments on two widely used benchmarks show that our framework consistently outperforms strong base agents and variants that use only textual tutorials or transcripts. Analyses highlight the importance of trajectory segmentation and selection, action filtering, and visual information, suggesting that abundant online videos can be systematically distilled into actionable guidance that improves computer-use agents at inference time. Our code is available at https://github.com/UCSB-NLP-Chang/video_demo.
E-MMDiT: Revisiting Multimodal Diffusion Transformer Design for Fast Image Synthesis under Limited Resources
Oct 31, 2025Diffusion models have shown strong capabilities in generating high-quality images from text prompts. However, these models often require large-scale training data and significant computational resources to train, or suffer from heavy structure with high latency. To this end, we propose Efficient Multimodal Diffusion Transformer (E-MMDiT), an efficient and lightweight multimodal diffusion model with only 304M parameters for fast image synthesis requiring low training resources. We provide an easily reproducible baseline with competitive results. Our model for 512px generation, trained with only 25M public data in 1.5 days on a single node of 8 AMD MI300X GPUs, achieves 0.66 on GenEval and easily reaches to 0.72 with some post-training techniques such as GRPO. Our design philosophy centers on token reduction as the computational cost scales significantly with the token count. We adopt a highly compressive visual tokenizer to produce a more compact representation and propose a novel multi-path compression module for further compression of tokens. To enhance our design, we introduce Position Reinforcement, which strengthens positional information to maintain spatial coherence, and Alternating Subregion Attention (ASA), which performs attention within subregions to further reduce computational cost. In addition, we propose AdaLN-affine, an efficient lightweight module for computing modulation parameters in transformer blocks. Our code is available at https://github.com/AMD-AGI/Nitro-E and we hope E-MMDiT serves as a strong and practical baseline for future research and contributes to democratization of generative AI models.
SparK: Query-Aware Unstructured Sparsity with Recoverable KV Cache Channel Pruning
Aug 21, 2025Long-context inference in large language models (LLMs) is increasingly constrained by the KV cache bottleneck: memory usage grows linearly with sequence length, while attention computation scales quadratically. Existing approaches address this issue by compressing the KV cache along the temporal axis through strategies such as token eviction or merging to reduce memory and computational overhead. However, these methods often neglect fine-grained importance variations across feature dimensions (i.e., the channel axis), thereby limiting their ability to effectively balance efficiency and model accuracy. In reality, we observe that channel saliency varies dramatically across both queries and positions: certain feature channels carry near-zero information for a given query, while others spike in relevance. To address this oversight, we propose SPARK, a training-free plug-and-play method that applies unstructured sparsity by pruning KV at the channel level, while dynamically restoring the pruned entries during attention score computation. Notably, our approach is orthogonal to existing KV compression and quantization techniques, making it compatible for integration with them to achieve further acceleration. By reducing channel-level redundancy, SPARK enables processing of longer sequences within the same memory budget. For sequences of equal length, SPARK not only preserves or improves model accuracy but also reduces KV cache storage by over 30% compared to eviction-based methods. Furthermore, even with an aggressive pruning ratio of 80%, SPARK maintains performance with less degradation than 5% compared to the baseline eviction method, demonstrating its robustness and effectiveness. Our code will be available at https://github.com/Xnhyacinth/SparK.
SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers
Jul 28, 2025The demand for Large Language Models (LLMs) capable of sophisticated mathematical reasoning is growing across industries. However, the development of performant mathematical LLMs is critically bottlenecked by the scarcity of difficult, novel training data. We introduce \textbf{SAND-Math} (Synthetic Augmented Novel and Difficult Mathematics problems and solutions), a pipeline that addresses this by first generating high-quality problems from scratch and then systematically elevating their complexity via a new \textbf{Difficulty Hiking} step. We demonstrate the effectiveness of our approach through two key findings. First, augmenting a strong baseline with SAND-Math data significantly boosts performance, outperforming the next-best synthetic dataset by \textbf{$\uparrow$ 17.85 absolute points} on the AIME25 benchmark. Second, in a dedicated ablation study, we show our Difficulty Hiking process is highly effective: by increasing average problem difficulty from 5.02 to 5.98, this step lifts AIME25 performance from 46.38\% to 49.23\%. The full generation pipeline, final dataset, and a fine-tuned model form a practical and scalable toolkit for building more capable and efficient mathematical reasoning LLMs. SAND-Math dataset is released here: \href{https://huggingface.co/datasets/amd/SAND-MATH}{https://huggingface.co/datasets/amd/SAND-MATH}
Instella-T2I: Pushing the Limits of 1D Discrete Latent Space Image Generation
Jun 26, 2025Image tokenization plays a critical role in reducing the computational demands of modeling high-resolution images, significantly improving the efficiency of image and multimodal understanding and generation. Recent advances in 1D latent spaces have reduced the number of tokens required by eliminating the need for a 2D grid structure. In this paper, we further advance compact discrete image representation by introducing 1D binary image latents. By representing each image as a sequence of binary vectors, rather than using traditional one-hot codebook tokens, our approach preserves high-resolution details while maintaining the compactness of 1D latents. To the best of our knowledge, our text-to-image models are the first to achieve competitive performance in both diffusion and auto-regressive generation using just 128 discrete tokens for images up to 1024x1024, demonstrating up to a 32-fold reduction in token numbers compared to standard VQ-VAEs. The proposed 1D binary latent space, coupled with simple model architectures, achieves marked improvements in speed training and inference speed. Our text-to-image models allow for a global batch size of 4096 on a single GPU node with 8 AMD MI300X GPUs, and the training can be completed within 200 GPU days. Our models achieve competitive performance compared to modern image generation models without any in-house private training data or post-training refinements, offering a scalable and efficient alternative to conventional tokenization methods.