 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoSeek: Long-Horizon Video Agent with Tool-Guided Seeking
Mar 20, 2026Video agentic models have advanced challenging video-language tasks. However, most agentic approaches still heavily rely on greedy parsing over densely sampled video frames, resulting in high computational cost. We present VideoSeek, a long-horizon video agent that leverages video logic flow to actively seek answer-critical evidence instead of exhaustively parsing the full video. This insight allows the model to use far fewer frames while maintaining, or even improving, its video understanding capability. VideoSeek operates in a think-act-observe loop with a well-designed toolkit for collecting multi-granular video observations. This design enables query-aware exploration over accumulated observations and supports practical video understanding and reasoning. Experiments on four challenging video understanding and reasoning benchmarks demonstrate that VideoSeek achieves strong accuracy while using far fewer frames than prior video agents and standalone LMMs. Notably, VideoSeek achieves a 10.2 absolute points improvement on LVBench over its base model, GPT-5, while using 93% fewer frames. Further analysis highlights the significance of leveraging video logic flow, strong reasoning capability, and the complementary roles of toolkit design.
NormCode Canvas: Making LLM Agentic Workflows Development Sustainable via Case-Based Reasoning
Mar 13, 2026We present NormCode Canvas (v1.1.3), a deployed system realizing Case-Based Reasoning at two levels for multi-step LLM workflows. The foundation is NormCode, a semi-formal planning language whose compiler-verified scope rule ensures every execution checkpoint is a genuinely self-contained case -- eliminating the implicit shared state that makes retrieval unreliable and failure non-localizable in standard orchestration frameworks. Level 1 treats each checkpoint as a concrete case (suspended runtime); Fork implements retrieve-and-reuse, Value Override implements revision with automatic stale-boundary propagation. Level 2 treats each compiled plan as an abstract case; the compilation pipeline is itself a NormCode plan, enabling recursive case learning. Three structural properties follow: (C1) direct checkpoint inspection; (C2) pre-execution review via compiler-generated narrative; (C3) scope-bounded selective re-execution. Four deployed plans serve as structured evidence: PPT Generation produces presentation decks at ~40s per slide on commercial APIs; Code Assistant carries out multi-step software-engineering tasks spanning up to ten reasoning cycles; NC Compilations converts natural-language specifications into executable NormCode plans; and Canvas Assistant, when connected to an external AI code editor, automates plan debugging. Together these plans form a self-sustaining ecosystem in which plans produce, debug, and refine one another -- realizing cumulative case-based learning at system scale.
ICHOR: A Robust Representation Learning Approach for ASL CBF Maps with Self-Supervised Masked Autoencoders
Mar 05, 2026Arterial spin labeling (ASL) perfusion MRI allows direct quantification of regional cerebral blood flow (CBF) without exogenous contrast, enabling noninvasive measurements that can be repeated without constraints imposed by contrast injection. ASL is increasingly acquired in research studies and clinical MRI protocols. Building on successes in structural imaging, recent efforts have implemented deep learning based methods to improve image quality, enable automated quality control, and derive robust quantitative and predictive biomarkers with ASL derived CBF. However, progress has been limited by variable image quality, substantial inter-site, vendor and protocol differences, and limited availability of labeled datasets needed to train models that generalize across cohorts. To address these challenges, we introduce ICHOR, a self supervised pre-training approach for ASL CBF maps that learns transferable representations using 3D masked autoencoders. ICHOR is pretrained via masked image modeling using a Vision Transformer backbone and can be used as a general-purpose encoder for downstream ASL tasks. For pre-training, we curated one of the largest ASL datasets to date, comprising 11,405 ASL CBF scans from 14 studies spanning multiple sites and acquisition protocols. We evaluated the pre-trained ICHOR encoder on three downstream diagnostic classification tasks and one ASL CBF map quality prediction regression task. Across all evaluations, ICHOR outperformed existing neuroimaging self-supervised pre-training methods adapted to ASL. Pre-trained weights and code will be made publicly available.
Reliable Use of Lemmas via Eligibility Reasoning and Section$-$Aware Reinforcement Learning
Feb 01, 2026Recent large language models (LLMs) perform strongly on mathematical benchmarks yet often misapply lemmas, importing conclusions without validating assumptions. We formalize lemma$-$judging as a structured prediction task: given a statement and a candidate lemma, the model must output a precondition check and a conclusion$-$utility check, from which a usefulness decision is derived. We present RULES, which encodes this specification via a two$-$section output and trains with reinforcement learning plus section$-$aware loss masking to assign penalty to the section responsible for errors. Training and evaluation draw on diverse natural language and formal proof corpora; robustness is assessed with a held$-$out perturbation suite; and end$-$to$-$end evaluation spans competition$-$style, perturbation$-$aligned, and theorem$-$based problems across various LLMs. Results show consistent in$-$domain gains over both a vanilla model and a single$-$label RL baseline, larger improvements on applicability$-$breaking perturbations, and parity or modest gains on end$-$to$-$end tasks; ablations indicate that the two$-$section outputs and section$-$aware reinforcement are both necessary for robustness.
CD4LM: Consistency Distillation and aDaptive Decoding for Diffusion Language Models
Jan 05, 2026Autoregressive large language models achieve strong results on many benchmarks, but decoding remains fundamentally latency-limited by sequential dependence on previously generated tokens. Diffusion language models (DLMs) promise parallel generation but suffer from a fundamental static-to-dynamic misalignment: Training optimizes local transitions under fixed schedules, whereas efficient inference requires adaptive "long-jump" refinements through unseen states. Our goal is to enable highly parallel decoding for DLMs with low number of function evaluations while preserving generation quality. To achieve this, we propose CD4LM, a framework that decouples training from inference via Discrete-Space Consistency Distillation (DSCD) and Confidence-Adaptive Decoding (CAD). Unlike standard objectives, DSCD trains a student to be trajectory-invariant, mapping diverse noisy states directly to the clean distribution. This intrinsic robustness enables CAD to dynamically allocate compute resources based on token confidence, aggressively skipping steps without the quality collapse typical of heuristic acceleration. On GSM8K, CD4LM matches the LLaDA baseline with a 5.18x wall-clock speedup; across code and math benchmarks, it strictly dominates the accuracy-efficiency Pareto frontier, achieving a 3.62x mean speedup while improving average accuracy. Code is available at https://github.com/yihao-liang/CDLM
Instella: Fully Open Language Models with Stellar Performance
Nov 14, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks, yet the majority of high-performing models remain closed-source or partially open, limiting transparency and reproducibility. In this work, we introduce Instella, a family of fully open three billion parameter language models trained entirely on openly available data and codebase. Powered by AMD Instinct MI300X GPUs, Instella is developed through large-scale pre-training, general-purpose instruction tuning, and alignment with human preferences. Despite using substantially fewer pre-training tokens than many contemporaries, Instella achieves state-of-the-art results among fully open models and is competitive with leading open-weight models of comparable size. We further release two specialized variants: Instella-Long, capable of handling context lengths up to 128K tokens, and Instella-Math, a reasoning-focused model enhanced through supervised fine-tuning and reinforcement learning on mathematical tasks. Together, these contributions establish Instella as a transparent, performant, and versatile alternative for the community, advancing the goal of open and reproducible language modeling research.
Learning from Online Videos at Inference Time for Computer-Use Agents
Nov 06, 2025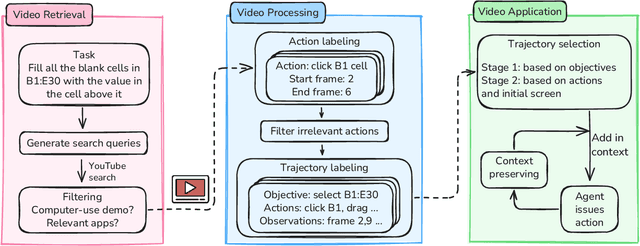



Computer-use agents can operate computers and automate laborious tasks, but despite recent rapid progress, they still lag behind human users, especially when tasks require domain-specific procedural knowledge about particular applications, platforms, and multi-step workflows. Humans can bridge this gap by watching video tutorials: we search, skim, and selectively imitate short segments that match our current subgoal. In this paper, we study how to enable computer-use agents to learn from online videos at inference time effectively. We propose a framework that retrieves and filters tutorial videos, converts them into structured demonstration trajectories, and dynamically selects trajectories as in-context guidance during execution. Particularly, using a VLM, we infer UI actions, segment videos into short subsequences of actions, and assign each subsequence a textual objective. At inference time, a two-stage selection mechanism dynamically chooses a single trajectory to add in context at each step, focusing the agent on the most helpful local guidance for its next decision. Experiments on two widely used benchmarks show that our framework consistently outperforms strong base agents and variants that use only textual tutorials or transcripts. Analyses highlight the importance of trajectory segmentation and selection, action filtering, and visual information, suggesting that abundant online videos can be systematically distilled into actionable guidance that improves computer-use agents at inference time. Our code is available at https://github.com/UCSB-NLP-Chang/video_demo.
OneOcc: Semantic Occupancy Prediction for Legged Robots with a Single Panoramic Camera
Nov 05, 2025Robust 3D semantic occupancy is crucial for legged/humanoid robots, yet most semantic scene completion (SSC) systems target wheeled platforms with forward-facing sensors. We present OneOcc, a vision-only panoramic SSC framework designed for gait-introduced body jitter and 360{\deg} continuity. OneOcc combines: (i) Dual-Projection fusion (DP-ER) to exploit the annular panorama and its equirectangular unfolding, preserving 360{\deg} continuity and grid alignment; (ii) Bi-Grid Voxelization (BGV) to reason in Cartesian and cylindrical-polar spaces, reducing discretization bias and sharpening free/occupied boundaries; (iii) a lightweight decoder with Hierarchical AMoE-3D for dynamic multi-scale fusion and better long-range/occlusion reasoning; and (iv) plug-and-play Gait Displacement Compensation (GDC) learning feature-level motion correction without extra sensors. We also release two panoramic occupancy benchmarks: QuadOcc (real quadruped, first-person 360{\deg}) and Human360Occ (H3O) (CARLA human-ego 360{\deg} with RGB, Depth, semantic occupancy; standardized within-/cross-city splits). OneOcc sets new state-of-the-art (SOTA): on QuadOcc it beats strong vision baselines and popular LiDAR ones; on H3O it gains +3.83 mIoU (within-city) and +8.08 (cross-city). Modules are lightweight, enabling deployable full-surround perception for legged/humanoid robots. Datasets and code will be publicly available at https://github.com/MasterHow/OneOcc.
Adversarial Distilled Retrieval-Augmented Guarding Model for Online Malicious Intent Detection
Sep 18, 2025



With the deployment of Large Language Models (LLMs) in interactive applications, online malicious intent detection has become increasingly critical. However, existing approaches fall short of handling diverse and complex user queries in real time. To address these challenges, we introduce ADRAG (Adversarial Distilled Retrieval-Augmented Guard), a two-stage framework for robust and efficient online malicious intent detection. In the training stage, a high-capacity teacher model is trained on adversarially perturbed, retrieval-augmented inputs to learn robust decision boundaries over diverse and complex user queries. In the inference stage, a distillation scheduler transfers the teacher's knowledge into a compact student model, with a continually updated knowledge base collected online. At deployment, the compact student model leverages top-K similar safety exemplars retrieved from the online-updated knowledge base to enable both online and real-time malicious query detection. Evaluations across ten safety benchmarks demonstrate that ADRAG, with a 149M-parameter model, achieves 98.5% of WildGuard-7B's performance, surpasses GPT-4 by 3.3% and Llama-Guard-3-8B by 9.5% on out-of-distribution detection, while simultaneously delivering up to 5.6x lower latency at 300 queries per second (QPS) in real-time applications.
Knowledge Collapse in LLMs: When Fluency Survives but Facts Fail under Recursive Synthetic Training
Sep 05, 2025Large language models increasingly rely on synthetic data due to human-written content scarcity, yet recursive training on model-generated outputs leads to model collapse, a degenerative process threatening factual reliability. We define knowledge collapse as a distinct three-stage phenomenon where factual accuracy deteriorates while surface fluency persists, creating "confidently wrong" outputs that pose critical risks in accuracy-dependent domains. Through controlled experiments with recursive synthetic training, we demonstrate that collapse trajectory and timing depend critically on instruction format, distinguishing instruction-following collapse from traditional model collapse through its conditional, prompt-dependent nature. We propose domain-specific synthetic training as a targeted mitigation strategy that achieves substantial improvements in collapse resistance while maintaining computational efficiency. Our evaluation framework combines model-centric indicators with task-centric metrics to detect distinct degradation phases, enabling reproducible assessment of epistemic deterioration across different language models. These findings provide both theoretical insights into collapse dynamics and practical guidance for sustainable AI training in knowledge-intensive applications where accuracy is paramount.