 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGA: Non-autoregressive Generative Auction with Global Externalities for Advertising Systems
Jun 06, 2025


Online advertising auctions are fundamental to internet commerce, demanding solutions that not only maximize revenue but also ensure incentive compatibility, high-quality user experience, and real-time efficiency. While recent learning-based auction frameworks have improved context modeling by capturing intra-list dependencies among ads, they remain limited in addressing global externalities and often suffer from inefficiencies caused by sequential processing. In this work, we introduce the Non-autoregressive Generative Auction with global externalities (NGA), a novel end-to-end framework designed for industrial online advertising. NGA explicitly models global externalities by jointly capturing the relationships among ads as well as the effects of adjacent organic content. To further enhance efficiency, NGA utilizes a non-autoregressive, constraint-based decoding strategy and a parallel multi-tower evaluator for unified list-wise reward and payment computation. Extensive offline experiments and large-scale online A/B testing on commercial advertising platforms demonstrate that NGA consistently outperforms existing methods in both effectiveness and efficiency.
Beyond Cascaded Architectures: An End-to-end Generative Framework for Industrial Advertising
May 26, 2025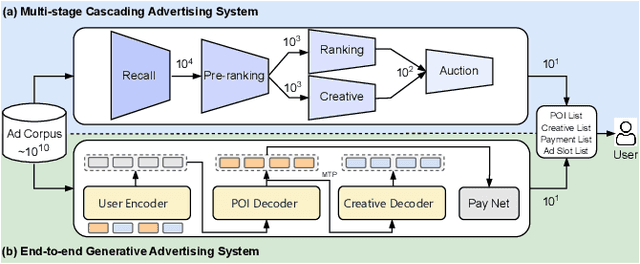
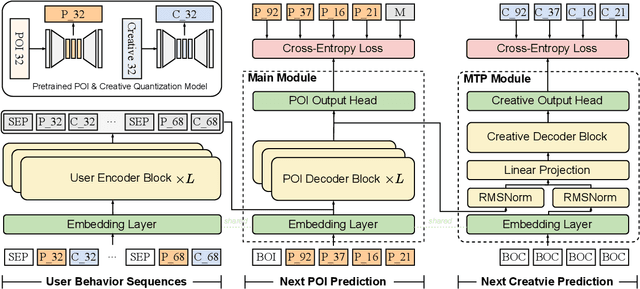
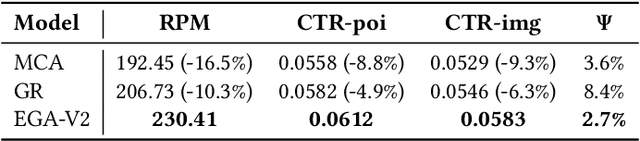
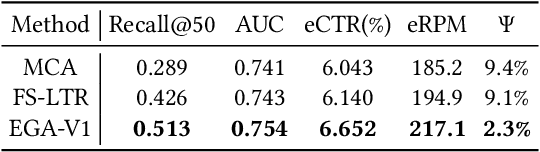
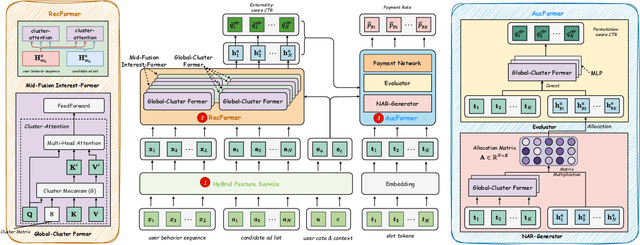
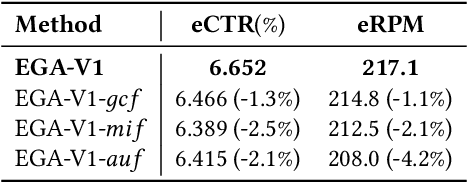
Traditional online industrial advertising systems suffer from the limitations of multi-stage cascaded architectures, which often discard high-potential candidates prematurely and distribute decision logic across disconnected modules. While recent generative recommendation approaches provide end-to-end solutions, they fail to address critical advertising requirements of key components for real-world deployment, such as explicit bidding, creative selection, ad allocation, and payment computation. To bridge this gap, we introduce End-to-End Generative Advertising (EGA), the first unified framework that holistically models user interests, point-of-interest (POI) and creative generation, ad allocation, and payment optimization within a single generative model. Our approach employs hierarchical tokenization and multi-token prediction to jointly generate POI recommendations and ad creatives, while a permutation-aware reward model and token-level bidding strategy ensure alignment with both user experiences and advertiser objectives. Additionally, we decouple allocation from payment using a differentiable ex-post regret minimization mechanism, guaranteeing approximate incentive compatibility at the POI level. Through extensive offline evaluations and large-scale online experiments on real-world advertising platforms, we demonstrate that EGA significantly outperforms traditional cascaded systems in both performance and practicality. Our results highlight its potential as a pioneering fully generative advertising solution, paving the way for next-generation industrial ad systems.
One Model to Rank Them All: Unifying Online Advertising with End-to-End Learning
May 26, 2025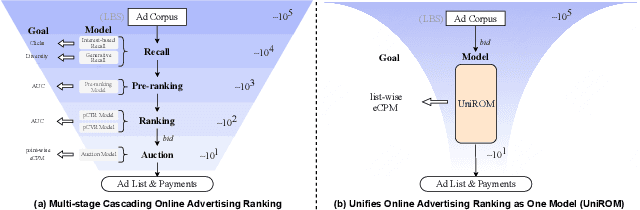
Modern industrial advertising systems commonly employ Multi-stage Cascading Architectures (MCA) to balance computational efficiency with ranking accuracy. However, this approach presents two fundamental challenges: (1) performance inconsistencies arising from divergent optimization targets and capability differences between stages, and (2) failure to account for advertisement externalities - the complex interactions between candidate ads during ranking. These limitations ultimately compromise system effectiveness and reduce platform profitability. In this paper, we present UniROM, an end-to-end generative architecture that Unifies online advertising Ranking as One Model. UniROM replaces cascaded stages with a single model to directly generate optimal ad sequences from the full candidate ad corpus in location-based services (LBS). The primary challenges associated with this approach stem from high costs of feature processing and computational bottlenecks in modeling externalities of large-scale candidate pools. To address these challenges, UniROM introduces an algorithm and engine co-designed hybrid feature service to decouple user and ad feature processing, reducing latency while preserving expressiveness. To efficiently extract intra- and cross-sequence mutual information, we propose RecFormer with an innovative cluster-attention mechanism as its core architectural component. Furthermore, we propose a bi-stage training strategy that integrates pre-training with reinforcement learning-based post-training to meet sophisticated platform and advertising objectives. Extensive offline evaluations on public benchmarks and large-scale online A/B testing on industrial advertising platform have demonstrated the superior performance of UniROM over state-of-the-art MCAs.
AutoAttention: Automatic Field Pair Selection for Attention in User Behavior Modeling
Oct 27, 2022In Click-through rate (CTR) prediction models, a user's interest is usually represented as a fixed-length vector based on her history behaviors. Recently, several methods are proposed to learn an attentive weight for each user behavior and conduct weighted sum pooling. However, these methods only manually select several fields from the target item side as the query to interact with the behaviors, neglecting the other target item fields, as well as user and context fields. Directly including all these fields in the attention may introduce noise and deteriorate the performance. In this paper, we propose a novel model named AutoAttention, which includes all item/user/context side fields as the query, and assigns a learnable weight for each field pair between behavior fields and query fields. Pruning on these field pairs via these learnable weights lead to automatic field pair selection, so as to identify and remove noisy field pairs. Though including more fields, the computation cost of AutoAttention is still low due to using a simple attention function and field pair selection. Extensive experiments on the public dataset and Tencent's production dataset demonstrate the effectiveness of the proposed approach.
HIEN: Hierarchical Intention Embedding Network for Click-Through Rate Prediction
Jun 01, 2022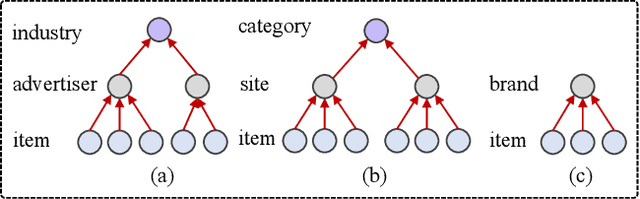

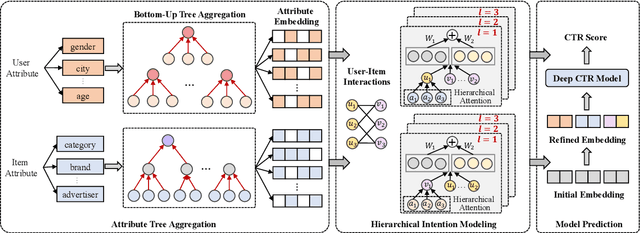
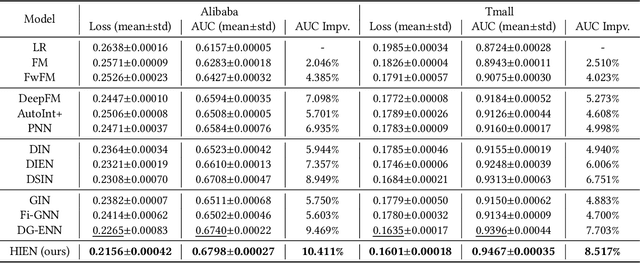
Click-through rate (CTR) prediction plays an important role in online advertising and recommendation systems, which aims at estimating the probability of a user clicking on a specific item. Feature interaction modeling and user interest modeling methods are two popular domains in CTR prediction, and they have been studied extensively in recent years. However, these methods still suffer from two limitations. First, traditional methods regard item attributes as ID features, while neglecting structure information and relation dependencies among attributes. Second, when mining user interests from user-item interactions, current models ignore user intents and item intents for different attributes, which lacks interpretability. Based on this observation, in this paper, we propose a novel approach Hierarchical Intention Embedding Network (HIEN), which considers dependencies of attributes based on bottom-up tree aggregation in the constructed attribute graph. HIEN also captures user intents for different item attributes as well as item intents based on our proposed hierarchical attention mechanism. Extensive experiments on both public and production datasets show that the proposed model significantly outperforms the state-of-the-art methods. In addition, HIEN can be applied as an input module to state-of-the-art CTR prediction methods, bringing further performance lift for these existing models that might already be intensively used in real systems.