 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Foundation Model for Ads Recommendation
Aug 20, 2025


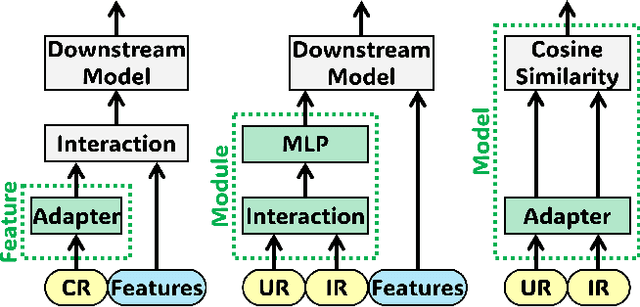
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
Pre-train, Align, and Disentangle: Empowering Sequential Recommendation with Large Language Models
Dec 05, 2024Sequential recommendation (SR) aims to model the sequential dependencies in users' historical interactions to better capture their evolving interests. However, existing SR approaches primarily rely on collaborative data, which leads to limitations such as the cold-start problem and sub-optimal performance. Meanwhile, despite the success of large language models (LLMs), their application in industrial recommender systems is hindered by high inference latency, inability to capture all distribution statistics, and catastrophic forgetting. To this end, we propose a novel Pre-train, Align, and Disentangle (PAD) paradigm to empower recommendation models with LLMs. Specifically, we first pre-train both the SR and LLM models to get collaborative and textual embeddings. Next, a characteristic recommendation-anchored alignment loss is proposed using multi-kernel maximum mean discrepancy with Gaussian kernels. Finally, a triple-experts architecture, consisting aligned and modality-specific experts with disentangled embeddings, is fine-tuned in a frequency-aware manner. Experiments conducted on three public datasets demonstrate the effectiveness of PAD, showing significant improvements and compatibility with various SR backbone models, especially on cold items. The implementation code and datasets will be publicly available.
LEADRE: Multi-Faceted Knowledge Enhanced LLM Empowered Display Advertisement Recommender System
Nov 21, 2024



Display advertising provides significant value to advertisers, publishers, and users. Traditional display advertising systems utilize a multi-stage architecture consisting of retrieval, coarse ranking, and final ranking. However, conventional retrieval methods rely on ID-based learning to rank mechanisms and fail to adequately utilize the content information of ads, which hampers their ability to provide diverse recommendation lists. To address this limitation, we propose leveraging the extensive world knowledge of LLMs. However, three key challenges arise when attempting to maximize the effectiveness of LLMs: "How to capture user interests", "How to bridge the knowledge gap between LLMs and advertising system", and "How to efficiently deploy LLMs". To overcome these challenges, we introduce a novel LLM-based framework called LLM Empowered Display ADvertisement REcommender system (LEADRE). LEADRE consists of three core modules: (1) The Intent-Aware Prompt Engineering introduces multi-faceted knowledge and designs intent-aware <Prompt, Response> pairs that fine-tune LLMs to generate ads tailored to users' personal interests. (2) The Advertising-Specific Knowledge Alignment incorporates auxiliary fine-tuning tasks and Direct Preference Optimization (DPO) to align LLMs with ad semantic and business value. (3) The Efficient System Deployment deploys LEADRE in an online environment by integrating both latency-tolerant and latency-sensitive service. Extensive offline experiments demonstrate the effectiveness of LEADRE and validate the contributions of individual modules. Online A/B test shows that LEADRE leads to a 1.57% and 1.17% GMV lift for serviced users on WeChat Channels and Moments separately. LEADRE has been deployed on both platforms, serving tens of billions of requests each day.
Signal-SGN: A Spiking Graph Convolutional Network for Skeletal Action Recognition via Learning Temporal-Frequency Dynamics
Aug 03, 2024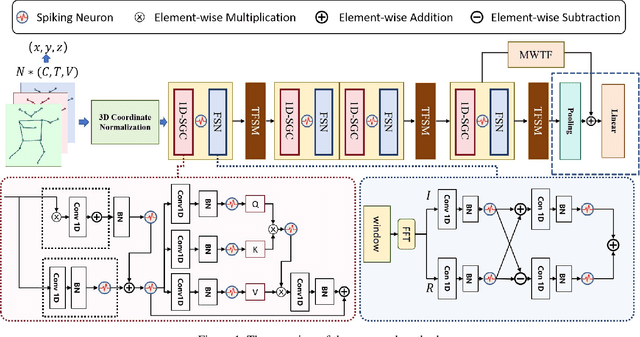
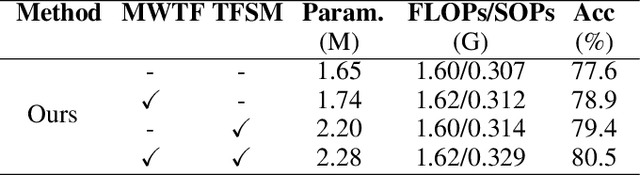
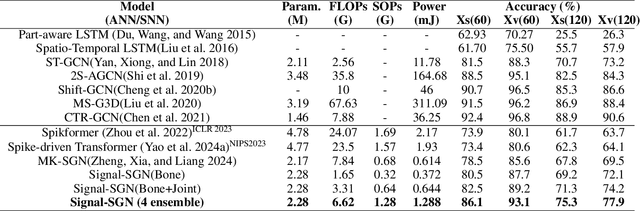
In skeletal-based action recognition, Graph Convolutional Networks (GCNs) based methods face limitations due to their complexity and high energy consumption. Spiking Neural Networks (SNNs) have gained attention in recent years for their low energy consumption, but existing methods combining GCNs and SNNs fail to fully utilize the temporal characteristics of skeletal sequences, leading to increased storage and computational costs. To address this issue, we propose a Signal-SGN(Spiking Graph Convolutional Network), which leverages the temporal dimension of skeletal sequences as the spiking timestep and treats features as discrete stochastic signals. The core of the network consists of a 1D Spiking Graph Convolutional Network (1D-SGN) and a Frequency Spiking Convolutional Network (FSN). The SGN performs graph convolution on single frames and incorporates spiking network characteristics to capture inter-frame temporal relationships, while the FSN uses Fast Fourier Transform (FFT) and complex convolution to extract temporal-frequency features. We also introduce a multi-scale wavelet transform feature fusion module(MWTF) to capture spectral features of temporal signals, enhancing the model's classification capability. We propose a pluggable temporal-frequency spatial semantic feature extraction module(TFSM) to enhance the model's ability to distinguish features without increasing inference-phase consumption. Our numerous experiments on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets demonstrate that the proposed models not only surpass existing SNN-based methods in accuracy but also reduce computational and storage costs during training. Furthermore, they achieve competitive accuracy compared to corresponding GCN-based methods, which is quite remarkable.
Deep Pattern Network for Click-Through Rate Prediction
Apr 17, 2024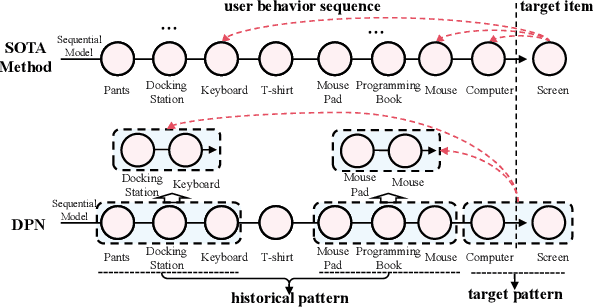
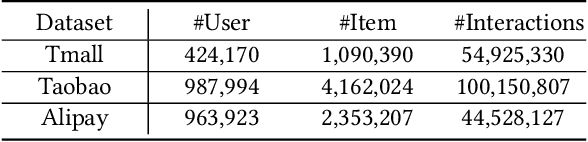
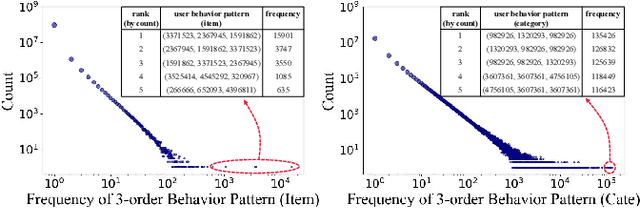
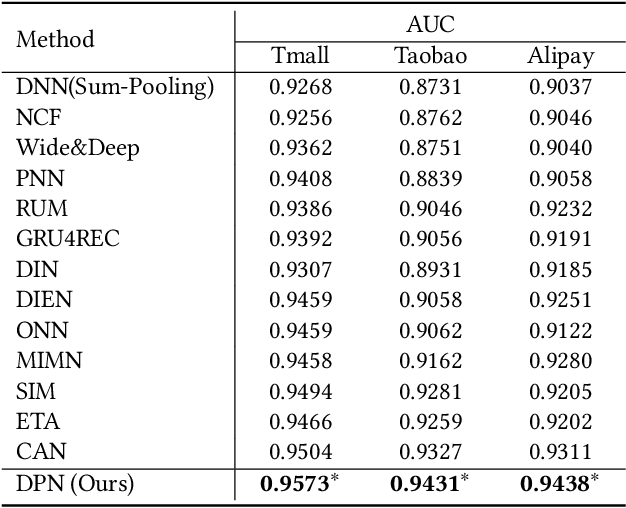
Click-through rate (CTR) prediction tasks play a pivotal role in real-world applications, particularly in recommendation systems and online advertising. A significant research branch in this domain focuses on user behavior modeling. Current research predominantly centers on modeling co-occurrence relationships between the target item and items previously interacted with by users in their historical data. However, this focus neglects the intricate modeling of user behavior patterns. In reality, the abundance of user interaction records encompasses diverse behavior patterns, indicative of a spectrum of habitual paradigms. These patterns harbor substantial potential to significantly enhance CTR prediction performance. To harness the informational potential within user behavior patterns, we extend Target Attention (TA) to Target Pattern Attention (TPA) to model pattern-level dependencies. Furthermore, three critical challenges demand attention: the inclusion of unrelated items within behavior patterns, data sparsity in behavior patterns, and computational complexity arising from numerous patterns. To address these challenges, we introduce the Deep Pattern Network (DPN), designed to comprehensively leverage information from user behavior patterns. DPN efficiently retrieves target-related user behavior patterns using a target-aware attention mechanism. Additionally, it contributes to refining user behavior patterns through a pre-training paradigm based on self-supervised learning while promoting dependency learning within sparse patterns. Our comprehensive experiments, conducted across three public datasets, substantiate the superior performance and broad compatibility of DPN.
Ad Recommendation in a Collapsed and Entangled World
Feb 22, 2024



In this paper, we present an industry ad recommendation system, paying attention to the challenges and practices of learning appropriate representations. Our study begins by showcasing our approaches to preserving priors when encoding features of diverse types into embedding representations. Specifically, we address sequence features, numeric features, pre-trained embedding features, as well as sparse ID features. Moreover, we delve into two pivotal challenges associated with feature representation: the dimensional collapse of embeddings and the interest entanglement across various tasks or scenarios. Subsequently, we propose several practical approaches to effectively tackle these two challenges. We then explore several training techniques to facilitate model optimization, reduce bias, and enhance exploration. Furthermore, we introduce three analysis tools that enable us to comprehensively study feature correlation, dimensional collapse, and interest entanglement. This work builds upon the continuous efforts of Tencent's ads recommendation team in the last decade. It not only summarizes general design principles but also presents a series of off-the-shelf solutions and analysis tools. The reported performance is based on our online advertising platform, which handles hundreds of billions of requests daily, serving millions of ads to billions of users.
AllSpark: a multimodal spatiotemporal general model
Dec 31, 2023



For a long time, due to the high heterogeneity in structure and semantics among various spatiotemporal modal data, the joint interpretation of multimodal spatiotemporal data has been an extremely challenging problem. The primary challenge resides in striking a trade-off between the cohesion and autonomy of diverse modalities, and this trade-off exhibits a progressively nonlinear nature as the number of modalities expands. We introduce the Language as Reference Framework (LaRF), a fundamental principle for constructing a multimodal unified model, aiming to strike a trade-off between the cohesion and autonomy among different modalities. We propose a multimodal spatiotemporal general artificial intelligence model, called AllSpark. Our model integrates thirteen different modalities into a unified framework, including 1D (text, code), 2D (RGB, infrared, SAR, multispectral, hyperspectral, tables, graphs, trajectory, oblique photography), and 3D (point clouds, videos) modalities. To achieve modal cohesion, AllSpark uniformly maps diverse modal features to the language modality. In addition, we design modality-specific prompts to guide multi-modal large language models in accurately perceiving multimodal data. To maintain modality autonomy, AllSpark introduces modality-specific encoders to extract the tokens of various spatiotemporal modalities. And modal bridge is employed to achieve dimensional projection from each modality to the language modality. Finally, observing a gap between the model's interpretation and downstream tasks, we designed task heads to enhance the model's generalization capability on specific downstream tasks. Experiments indicate that AllSpark achieves competitive accuracy in modalities such as RGB and trajectory compared to state-of-the-art models.
Decoupled Training: Return of Frustratingly Easy Multi-Domain Learning
Sep 19, 2023Multi-domain learning (MDL) aims to train a model with minimal average risk across multiple overlapping but non-identical domains. To tackle the challenges of dataset bias and domain domination, numerous MDL approaches have been proposed from the perspectives of seeking commonalities by aligning distributions to reduce domain gap or reserving differences by implementing domain-specific towers, gates, and even experts. MDL models are becoming more and more complex with sophisticated network architectures or loss functions, introducing extra parameters and enlarging computation costs. In this paper, we propose a frustratingly easy and hyperparameter-free multi-domain learning method named Decoupled Training(D-Train). D-Train is a tri-phase general-to-specific training strategy that first pre-trains on all domains to warm up a root model, then post-trains on each domain by splitting into multi heads, and finally fine-tunes the heads by fixing the backbone, enabling decouple training to achieve domain independence. Despite its extraordinary simplicity and efficiency, D-Train performs remarkably well in extensive evaluations of various datasets from standard benchmarks to applications of satellite imagery and recommender systems.
Generic and Robust Root Cause Localization for Multi-Dimensional Data in Online Service Systems
May 05, 2023



Localizing root causes for multi-dimensional data is critical to ensure online service systems' reliability. When a fault occurs, only the measure values within specific attribute combinations are abnormal. Such attribute combinations are substantial clues to the underlying root causes and thus are called root causes of multidimensional data. This paper proposes a generic and robust root cause localization approach for multi-dimensional data, PSqueeze. We propose a generic property of root cause for multi-dimensional data, generalized ripple effect (GRE). Based on it, we propose a novel probabilistic cluster method and a robust heuristic search method. Moreover, we identify the importance of determining external root causes and propose an effective method for the first time in literature. Our experiments on two real-world datasets with 5400 faults show that the F1-score of PSqueeze outperforms baselines by 32.89%, while the localization time is around 10 seconds across all cases. The F1-score in determining external root causes of PSqueeze achieves 0.90. Furthermore, case studies in several production systems demonstrate that PSqueeze is helpful to fault diagnosis in the real world.
AutoAttention: Automatic Field Pair Selection for Attention in User Behavior Modeling
Oct 27, 2022In Click-through rate (CTR) prediction models, a user's interest is usually represented as a fixed-length vector based on her history behaviors. Recently, several methods are proposed to learn an attentive weight for each user behavior and conduct weighted sum pooling. However, these methods only manually select several fields from the target item side as the query to interact with the behaviors, neglecting the other target item fields, as well as user and context fields. Directly including all these fields in the attention may introduce noise and deteriorate the performance. In this paper, we propose a novel model named AutoAttention, which includes all item/user/context side fields as the query, and assigns a learnable weight for each field pair between behavior fields and query fields. Pruning on these field pairs via these learnable weights lead to automatic field pair selection, so as to identify and remove noisy field pairs. Though including more fields, the computation cost of AutoAttention is still low due to using a simple attention function and field pair selection. Extensive experiments on the public dataset and Tencent's production dataset demonstrate the effectiveness of the proposed approach.