 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch as Node: Human-Centric Graph Representation Learning for Multimodal Action Recognition
Dec 26, 2025While human action recognition has witnessed notable achievements, multimodal methods fusing RGB and skeleton modalities still suffer from their inherent heterogeneity and fail to fully exploit the complementary potential between them. In this paper, we propose PAN, the first human-centric graph representation learning framework for multimodal action recognition, in which token embeddings of RGB patches containing human joints are represented as spatiotemporal graphs. The human-centric graph modeling paradigm suppresses the redundancy in RGB frames and aligns well with skeleton-based methods, thus enabling a more effective and semantically coherent fusion of multimodal features. Since the sampling of token embeddings heavily relies on 2D skeletal data, we further propose attention-based post calibration to reduce the dependency on high-quality skeletal data at a minimal cost interms of model performance. To explore the potential of PAN in integrating with skeleton-based methods, we present two variants: PAN-Ensemble, which employs dual-path graph convolution networks followed by late fusion, and PAN-Unified, which performs unified graph representation learning within a single network. On three widely used multimodal action recognition datasets, both PAN-Ensemble and PAN-Unified achieve state-of-the-art (SOTA) performance in their respective settings of multimodal fusion: separate and unified modeling, respectively.
SNN-Driven Multimodal Human Action Recognition via Event Camera and Skeleton Data Fusion
Feb 19, 2025Multimodal human action recognition based on RGB and skeleton data fusion, while effective, is constrained by significant limitations such as high computational complexity, excessive memory consumption, and substantial energy demands, particularly when implemented with Artificial Neural Networks (ANN). These limitations restrict its applicability in resource-constrained scenarios. To address these challenges, we propose a novel Spiking Neural Network (SNN)-driven framework for multimodal human action recognition, utilizing event camera and skeleton data. Our framework is centered on two key innovations: (1) a novel multimodal SNN architecture that employs distinct backbone networks for each modality-an SNN-based Mamba for event camera data and a Spiking Graph Convolutional Network (SGN) for skeleton data-combined with a spiking semantic extraction module to capture deep semantic representations; and (2) a pioneering SNN-based discretized information bottleneck mechanism for modality fusion, which effectively balances the preservation of modality-specific semantics with efficient information compression. To validate our approach, we propose a novel method for constructing a multimodal dataset that integrates event camera and skeleton data, enabling comprehensive evaluation. Extensive experiments demonstrate that our method achieves superior performance in both recognition accuracy and energy efficiency, offering a promising solution for practical applications.
Topological Symmetry Enhanced Graph Convolution for Skeleton-Based Action Recognition
Nov 20, 2024
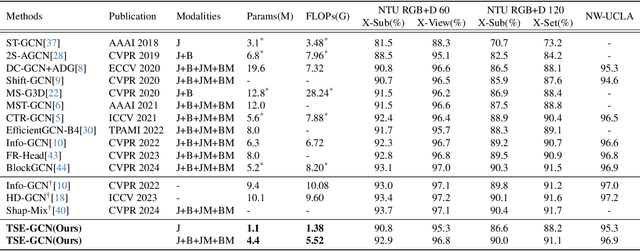

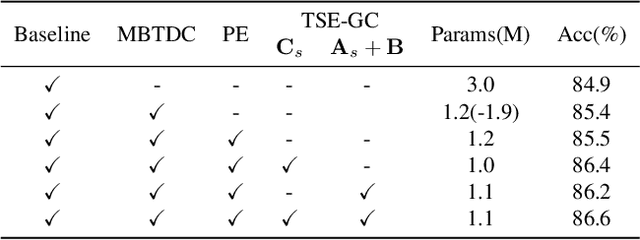
Skeleton-based action recognition has achieved remarkable performance with the development of graph convolutional networks (GCNs). However, most of these methods tend to construct complex topology learning mechanisms while neglecting the inherent symmetry of the human body. Additionally, the use of temporal convolutions with certain fixed receptive fields limits their capacity to effectively capture dependencies in time sequences. To address the issues, we (1) propose a novel Topological Symmetry Enhanced Graph Convolution (TSE-GC) to enable distinct topology learning across different channel partitions while incorporating topological symmetry awareness and (2) construct a Multi-Branch Deformable Temporal Convolution (MBDTC) for skeleton-based action recognition. The proposed TSE-GC emphasizes the inherent symmetry of the human body while enabling efficient learning of dynamic topologies. Meanwhile, the design of MBDTC introduces the concept of deformable modeling, leading to more flexible receptive fields and stronger modeling capacity of temporal dependencies. Combining TSE-GC with MBDTC, our final model, TSE-GCN, achieves competitive performance with fewer parameters compared with state-of-the-art methods on three large datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. On the cross-subject and cross-set evaluations of NTU RGB+D 120, the accuracies of our model reach 90.0\% and 91.1\%, with 1.1M parameters and 1.38 GFLOPS for one stream.
Signal-SGN: A Spiking Graph Convolutional Network for Skeletal Action Recognition via Learning Temporal-Frequency Dynamics
Aug 03, 2024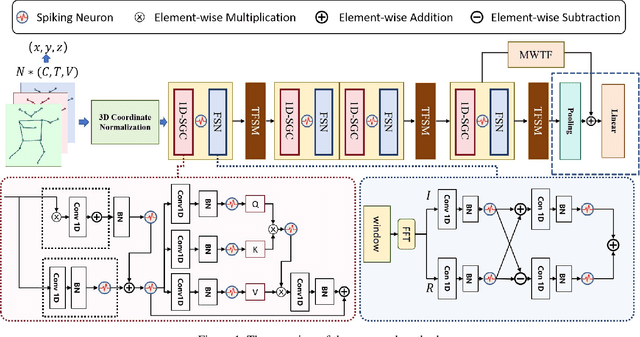
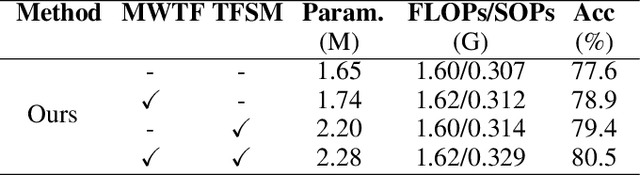
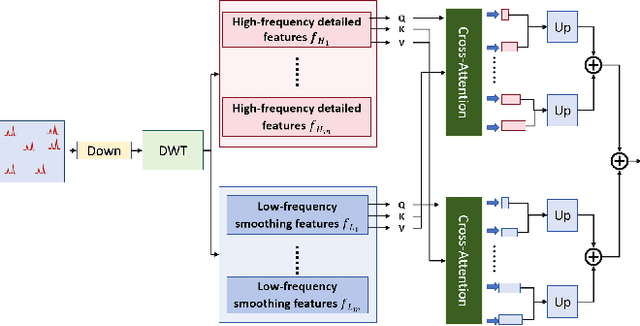
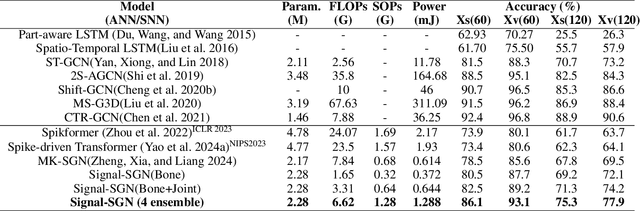
In skeletal-based action recognition, Graph Convolutional Networks (GCNs) based methods face limitations due to their complexity and high energy consumption. Spiking Neural Networks (SNNs) have gained attention in recent years for their low energy consumption, but existing methods combining GCNs and SNNs fail to fully utilize the temporal characteristics of skeletal sequences, leading to increased storage and computational costs. To address this issue, we propose a Signal-SGN(Spiking Graph Convolutional Network), which leverages the temporal dimension of skeletal sequences as the spiking timestep and treats features as discrete stochastic signals. The core of the network consists of a 1D Spiking Graph Convolutional Network (1D-SGN) and a Frequency Spiking Convolutional Network (FSN). The SGN performs graph convolution on single frames and incorporates spiking network characteristics to capture inter-frame temporal relationships, while the FSN uses Fast Fourier Transform (FFT) and complex convolution to extract temporal-frequency features. We also introduce a multi-scale wavelet transform feature fusion module(MWTF) to capture spectral features of temporal signals, enhancing the model's classification capability. We propose a pluggable temporal-frequency spatial semantic feature extraction module(TFSM) to enhance the model's ability to distinguish features without increasing inference-phase consumption. Our numerous experiments on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets demonstrate that the proposed models not only surpass existing SNN-based methods in accuracy but also reduce computational and storage costs during training. Furthermore, they achieve competitive accuracy compared to corresponding GCN-based methods, which is quite remarkable.
MK-SGN: A Spiking Graph Convolutional Network with Multimodal Fusion and Knowledge Distillation for Skeleton-based Action Recognition
Apr 16, 2024



In recent years, skeleton-based action recognition, leveraging multimodal Graph Convolutional Networks (GCN), has achieved remarkable results. However, due to their deep structure and reliance on continuous floating-point operations, GCN-based methods are energy-intensive. To address this issue, we propose an innovative Spiking Graph Convolutional Network with Multimodal Fusion and Knowledge Distillation (MK-SGN). By merging the energy efficiency of Spiking Neural Network (SNN) with the graph representation capability of GCN, the proposed MK-SGN reduces energy consumption while maintaining recognition accuracy. Firstly, we convert GCN into Spiking Graph Convolutional Network (SGN) and construct a foundational Base-SGN for skeleton-based action recognition, establishing a new benchmark and paving the way for future research exploration. Secondly, we further propose a Spiking Multimodal Fusion module (SMF), leveraging mutual information to process multimodal data more efficiently. Additionally, we introduce a spiking attention mechanism and design a Spatio Graph Convolution module with a Spatial Global Spiking Attention mechanism (SA-SGC), enhancing feature learning capability. Furthermore, we delve into knowledge distillation methods from multimodal GCN to SGN and propose a novel, integrated method that simultaneously focuses on both intermediate layer distillation and soft label distillation to improve the performance of SGN. On two challenging datasets for skeleton-based action recognition, MK-SGN outperforms the state-of-the-art GCN-like frameworks in reducing computational load and energy consumption. In contrast, typical GCN methods typically consume more than 35mJ per action sample, while MK-SGN reduces energy consumption by more than 98%.
Exploiting Offset-guided Network for Pose Estimation and Tracking
Jun 04, 2019
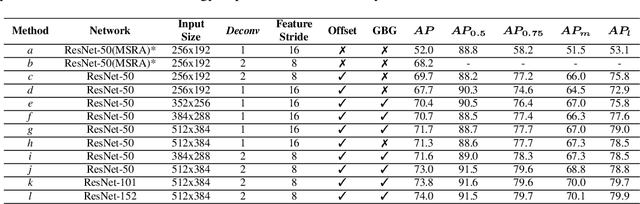
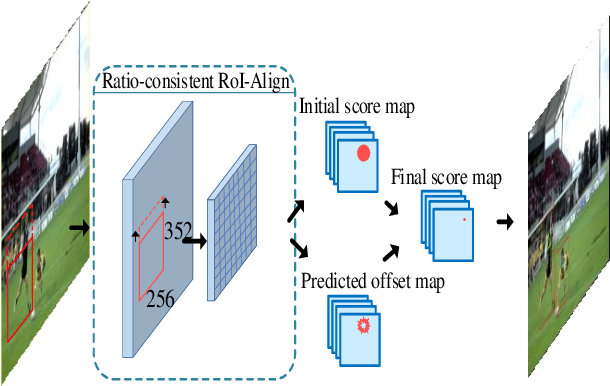

Human pose estimation has witnessed a significant advance thanks to the development of deep learning. Recent human pose estimation approaches tend to directly predict the location heatmaps, which causes quantization errors and inevitably deteriorates the performance within the reduced network output. Aim at solving it, we revisit the heatmap-offset aggregation method and propose the Offset-guided Network (OGN) with an intuitive but effective fusion strategy for both two-stages pose estimation and Mask R-CNN. For two-stages pose estimation, a greedy box generation strategy is also proposed to keep more necessary candidates while performing person detection. For mask R-CNN, ratio-consistent is adopted to improve the generalization ability of the network. State-of-the-art results on COCO and PoseTrack dataset verify the effectiveness of our offset-guided pose estimation and tracking.