 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-World VLA: Interleaved World Modeling and Planning for Autonomous Driving
Mar 28, 2026Autonomous driving requires reasoning about how the environment evolves and planning actions accordingly. Existing world-model-based approaches typically predict future scenes first and plan afterwards, resulting in open-loop imagination that may drift from the actual decision process. In this paper, we present Uni-World VLA, a unified vision-language-action (VLA) model that tightly interleaves future frame prediction and trajectory planning. Instead of generating a full world rollout before planning, our model alternates between predicting future frames and ego actions step by step, allowing planning decisions to be continuously conditioned on the imagined future observations. This interleaved generation forms a closed-loop interaction between world modeling and control, enabling more adaptive decision-making in dynamic traffic scenarios. In addition, we incorporate monocular depth information into frames to provide stronger geometric cues for world modeling, improving long-horizon scene prediction. Experiments on the NAVSIM benchmark show that our approach achieves competitive closed-loop planning performance while producing high-fidelity future frame predictions. These results demonstrate that tightly coupling world prediction and planning is a promising direction for scalable VLA driving systems.
Vec-QMDP: Vectorized POMDP Planning on CPUs for Real-Time Autonomous Driving
Feb 09, 2026Planning under uncertainty for real-world robotics tasks, such as autonomous driving, requires reasoning in enormous high-dimensional belief spaces, rendering the problem computationally intensive. While parallelization offers scalability, existing hybrid CPU-GPU solvers face critical bottlenecks due to host-device synchronization latency and branch divergence on SIMT architectures, limiting their utility for real-time planning and hindering real-robot deployment. We present Vec-QMDP, a CPU-native parallel planner that aligns POMDP search with modern CPUs' SIMD architecture, achieving $227\times$--$1073\times$ speedup over state-of-the-art serial planners. Vec-QMDP adopts a Data-Oriented Design (DOD), refactoring scattered, pointer-based data structures into contiguous, cache-efficient memory layouts. We further introduce a hierarchical parallelism scheme: distributing sub-trees across independent CPU cores and SIMD lanes, enabling fully vectorized tree expansion and collision checking. Efficiency is maximized with the help of UCB load balancing across trees and a vectorized STR-tree for coarse-level collision checking. Evaluated on large-scale autonomous driving benchmarks, Vec-QMDP achieves state-of-the-art planning performance with millisecond-level latency, establishing CPUs as a high-performance computing platform for large-scale planning under uncertainty.
STAGE: A Symbolic Tensor grAph GEnerator for distributed AI system co-design
Nov 14, 2025Optimizing the performance of large language models (LLMs) on large-scale AI training and inference systems requires a scalable and expressive mechanism to model distributed workload execution. Such modeling is essential for pre-deployment system-level optimizations (e.g., parallelization strategies) and design-space explorations. While recent efforts have proposed collecting execution traces from real systems, access to large-scale infrastructure remains limited to major cloud providers. Moreover, traces obtained from existing platforms cannot be easily adapted to study future larger-scale system configurations. We introduce Symbolic Tensor grAph GEnerator(STAGE), a framework that synthesizes high-fidelity execution traces to accurately model LLM workloads. STAGE supports a comprehensive set of parallelization strategies, allowing users to systematically explore a wide spectrum of LLM architectures and system configurations. STAGE demonstrates its scalability by synthesizing high-fidelity LLM traces spanning over 32K GPUs, while preserving tensor-level accuracy in compute, memory, and communication. STAGE is publicly available to facilitate further research in distributed machine learning systems: https://github.com/astra-sim/symbolic tensor graph
OuroMamba: A Data-Free Quantization Framework for Vision Mamba Models
Mar 13, 2025We present OuroMamba, the first data-free post-training quantization (DFQ) method for vision Mamba-based models (VMMs). We identify two key challenges in enabling DFQ for VMMs, (1) VMM's recurrent state transitions restricts capturing of long-range interactions and leads to semantically weak synthetic data, (2) VMM activations exhibit dynamic outlier variations across time-steps, rendering existing static PTQ techniques ineffective. To address these challenges, OuroMamba presents a two-stage framework: (1) OuroMamba-Gen to generate semantically rich and meaningful synthetic data. It applies contrastive learning on patch level VMM features generated through neighborhood interactions in the latent state space, (2) OuroMamba-Quant to employ mixed-precision quantization with lightweight dynamic outlier detection during inference. In specific, we present a thresholding based outlier channel selection strategy for activations that gets updated every time-step. Extensive experiments across vision and generative tasks show that our data-free OuroMamba surpasses existing data-driven PTQ techniques, achieving state-of-the-art performance across diverse quantization settings. Additionally, we implement efficient GPU kernels to achieve practical latency speedup of up to 2.36x. Code will be released soon.
Deep Learning in Single-Cell and Spatial Transcriptomics Data Analysis: Advances and Challenges from a Data Science Perspective
Dec 04, 2024



The development of single-cell and spatial transcriptomics has revolutionized our capacity to investigate cellular properties, functions, and interactions in both cellular and spatial contexts. However, the analysis of single-cell and spatial omics data remains challenging. First, single-cell sequencing data are high-dimensional and sparse, often contaminated by noise and uncertainty, obscuring the underlying biological signals. Second, these data often encompass multiple modalities, including gene expression, epigenetic modifications, and spatial locations. Integrating these diverse data modalities is crucial for enhancing prediction accuracy and biological interpretability. Third, while the scale of single-cell sequencing has expanded to millions of cells, high-quality annotated datasets are still limited. Fourth, the complex correlations of biological tissues make it difficult to accurately reconstruct cellular states and spatial contexts. Traditional feature engineering-based analysis methods struggle to deal with the various challenges presented by intricate biological networks. Deep learning has emerged as a powerful tool capable of handling high-dimensional complex data and automatically identifying meaningful patterns, offering significant promise in addressing these challenges. This review systematically analyzes these challenges and discusses related deep learning approaches. Moreover, we have curated 21 datasets from 9 benchmarks, encompassing 58 computational methods, and evaluated their performance on the respective modeling tasks. Finally, we highlight three areas for future development from a technical, dataset, and application perspective. This work will serve as a valuable resource for understanding how deep learning can be effectively utilized in single-cell and spatial transcriptomics analyses, while inspiring novel approaches to address emerging challenges.
Topological Symmetry Enhanced Graph Convolution for Skeleton-Based Action Recognition
Nov 20, 2024
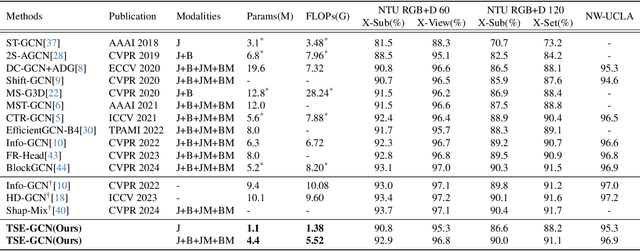

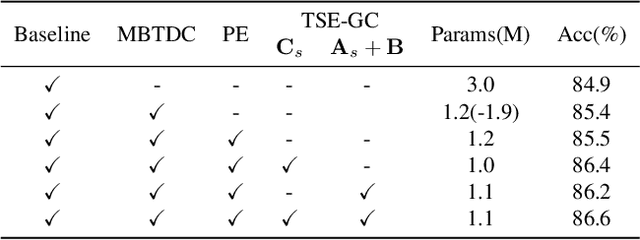
Skeleton-based action recognition has achieved remarkable performance with the development of graph convolutional networks (GCNs). However, most of these methods tend to construct complex topology learning mechanisms while neglecting the inherent symmetry of the human body. Additionally, the use of temporal convolutions with certain fixed receptive fields limits their capacity to effectively capture dependencies in time sequences. To address the issues, we (1) propose a novel Topological Symmetry Enhanced Graph Convolution (TSE-GC) to enable distinct topology learning across different channel partitions while incorporating topological symmetry awareness and (2) construct a Multi-Branch Deformable Temporal Convolution (MBDTC) for skeleton-based action recognition. The proposed TSE-GC emphasizes the inherent symmetry of the human body while enabling efficient learning of dynamic topologies. Meanwhile, the design of MBDTC introduces the concept of deformable modeling, leading to more flexible receptive fields and stronger modeling capacity of temporal dependencies. Combining TSE-GC with MBDTC, our final model, TSE-GCN, achieves competitive performance with fewer parameters compared with state-of-the-art methods on three large datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. On the cross-subject and cross-set evaluations of NTU RGB+D 120, the accuracies of our model reach 90.0\% and 91.1\%, with 1.1M parameters and 1.38 GFLOPS for one stream.
Smart Audit System Empowered by LLM
Oct 10, 2024



Manufacturing quality audits are pivotal for ensuring high product standards in mass production environments. Traditional auditing processes, however, are labor-intensive and reliant on human expertise, posing challenges in maintaining transparency, accountability, and continuous improvement across complex global supply chains. To address these challenges, we propose a smart audit system empowered by large language models (LLMs). Our approach introduces three innovations: a dynamic risk assessment model that streamlines audit procedures and optimizes resource allocation; a manufacturing compliance copilot that enhances data processing, retrieval, and evaluation for a self-evolving manufacturing knowledge base; and a Re-act framework commonality analysis agent that provides real-time, customized analysis to empower engineers with insights for supplier improvement. These enhancements elevate audit efficiency and effectiveness, with testing scenarios demonstrating an improvement of over 24%.
Bundle Adjustment in the Eager Mode
Sep 18, 2024



Bundle adjustment (BA) is a critical technique in various robotic applications, such as simultaneous localization and mapping (SLAM), augmented reality (AR), and photogrammetry. BA optimizes parameters such as camera poses and 3D landmarks to align them with observations. With the growing importance of deep learning in perception systems, there is an increasing need to integrate BA with deep learning frameworks for enhanced reliability and performance. However, widely-used C++-based BA frameworks, such as GTSAM, g$^2$o, and Ceres, lack native integration with modern deep learning libraries like PyTorch. This limitation affects their flexibility, adaptability, ease of debugging, and overall implementation efficiency. To address this gap, we introduce an eager-mode BA framework seamlessly integrated with PyPose, providing PyTorch-compatible interfaces with high efficiency. Our approach includes GPU-accelerated, differentiable, and sparse operations designed for 2nd-order optimization, Lie group and Lie algebra operations, and linear solvers. Our eager-mode BA on GPU demonstrates substantial runtime efficiency, achieving an average speedup of 18.5$\times$, 22$\times$, and 23$\times$ compared to GTSAM, g$^2$o, and Ceres, respectively.
MROVSeg: Breaking the Resolution Curse of Vision-Language Models in Open-Vocabulary Semantic Segmentation
Aug 27, 2024
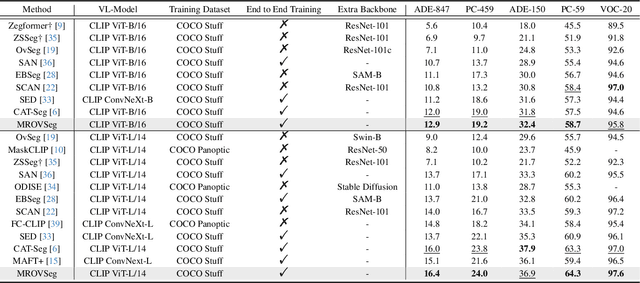

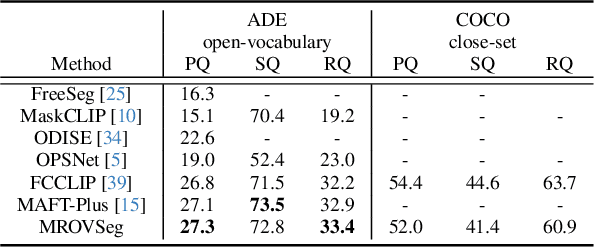
Open-vocabulary semantic segmentation aims to segment and recognize semantically meaningful regions based on text-based descriptions during inference. A typical solution to address this task is to leverage powerful vision-language models (VLMs), such as CLIP, to bridge the gap between open- and close-vocabulary recognition. As VLMs are usually pretrained with low-resolution images (e.g. $224\times224$), most previous methods operate only on downscaled images. We question this design as low resolution features often fail to preserve fine details. Although employing additional image backbones for high-resolution inputs can mitigate this issue, it may also introduce significant computation overhead. Therefore, we propose MROVSeg, a multi-resolution training framework for open-vocabulary semantic segmentation with a single pretrained CLIP backbone, that uses sliding windows to slice the high-resolution input into uniform patches, each matching the input size of the well-trained image encoder. Its key components include a Multi-Res Adapter, which restores the spatial geometry and grasps local-global correspondences across patches by learnable convolutional and scale attention layers. To achieve accurate segmentation, we introduce Multi-grained Masked Attention scheme to aggregate multi-grained semantics by performing cross-attention between object queries and multi-resolution CLIP features within the region of interests. Through comprehensive experiments, we demonstrate the superiority of MROVSeg on well-established open-vocabulary semantic segmentation benchmarks, particularly for high-resolution inputs, establishing new standards for open-vocabulary semantic segmentation.
Transforming Surgical Interventions with Embodied Intelligence for Ultrasound Robotics
Jun 18, 2024



Ultrasonography has revolutionized non-invasive diagnostic methodologies, significantly enhancing patient outcomes across various medical domains. Despite its advancements, integrating ultrasound technology with robotic systems for automated scans presents challenges, including limited command understanding and dynamic execution capabilities. To address these challenges, this paper introduces a novel Ultrasound Embodied Intelligence system that synergistically combines ultrasound robots with large language models (LLMs) and domain-specific knowledge augmentation, enhancing ultrasound robots' intelligence and operational efficiency. Our approach employs a dual strategy: firstly, integrating LLMs with ultrasound robots to interpret doctors' verbal instructions into precise motion planning through a comprehensive understanding of ultrasound domain knowledge, including APIs and operational manuals; secondly, incorporating a dynamic execution mechanism, allowing for real-time adjustments to scanning plans based on patient movements or procedural errors. We demonstrate the effectiveness of our system through extensive experiments, including ablation studies and comparisons across various models, showcasing significant improvements in executing medical procedures from verbal commands. Our findings suggest that the proposed system improves the efficiency and quality of ultrasound scans and paves the way for further advancements in autonomous medical scanning technologies, with the potential to transform non-invasive diagnostics and streamline medical workflows.