 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark and Multi-Agent System for Instruction-driven Cinematic Video Compilation
Apr 12, 2026The surging demand for adapting long-form cinematic content into short videos has motivated the need for versatile automatic video compilation systems. However, existing compilation methods are limited to predefined tasks, and the community lacks a comprehensive benchmark to evaluate the cinematic compilation. To address this, we introduce CineBench, the first benchmark for instruction-driven cinematic video compilation, featuring diverse user instructions and high-quality ground-truth compilations annotated by professional editors. To overcome contextual collapse and temporal fragmentation, we present CineAgents, a multi-agent system that reformulates cinematic video compilation into ``design-and-compose'' paradigm. CineAgents performs script reverse-engineering to construct a hierarchical narrative memory to provide multi-level context and employs an iterative narrative planning process that refines a creative blueprint into a final compiled script. Extensive experiments demonstrate that CineAgents significantly outperforms existing methods, generating compilations with superior narrative coherence and logical coherence.
ReContraster: Making Your Posters Stand Out with Regional Contrast
Apr 12, 2026Effective poster design requires rapidly capturing attention and clearly conveying messages. Inspired by the ``contrast effects'' principle, we propose ReContraster, the first training-free model to leverage regional contrast to make posters stand out. By emulating the cognitive behaviors of a poster designer, ReContraster introduces the compositional multi-agent system to identify elements, organize layout, and evaluate generated poster candidates. To further ensure harmonious transitions across region boundaries, ReContraster integrates the hybrid denoising strategy during the diffusion process. We additionally contribute a new benchmark dataset for comprehensive evaluation. Seven quantitative metrics and four user studies confirm its superiority over relevant state-of-the-art methods, producing visually striking and aesthetically appealing posters.
Lighting-grounded Video Generation with Renderer-based Agent Reasoning
Apr 09, 2026Diffusion models have achieved remarkable progress in video generation, but their controllability remains a major limitation. Key scene factors such as layout, lighting, and camera trajectory are often entangled or only weakly modeled, restricting their applicability in domains like filmmaking and virtual production where explicit scene control is essential. We present LiVER, a diffusion-based framework for scene-controllable video generation. To achieve this, we introduce a novel framework that conditions video synthesis on explicit 3D scene properties, supported by a new large-scale dataset with dense annotations of object layout, lighting, and camera parameters. Our method disentangles these properties by rendering control signals from a unified 3D representation. We propose a lightweight conditioning module and a progressive training strategy to integrate these signals into a foundational video diffusion model, ensuring stable convergence and high fidelity. Our framework enables a wide range of applications, including image-to-video and video-to-video synthesis where the underlying 3D scene is fully editable. To further enhance usability, we develop a scene agent that automatically translates high-level user instructions into the required 3D control signals. Experiments show that LiVER achieves state-of-the-art photorealism and temporal consistency while enabling precise, disentangled control over scene factors, setting a new standard for controllable video generation.
PolGS++: Physically-Guided Polarimetric Gaussian Splatting for Fast Reflective Surface Reconstruction
Mar 11, 2026Accurate reconstruction of reflective surfaces remains a fundamental challenge in computer vision, with broad applications in real-time virtual reality and digital content creation. Although 3D Gaussian Splatting (3DGS) enables efficient novel-view rendering with explicit representations, its performance on reflective surfaces still lags behind implicit neural methods, especially in recovering fine geometry and surface normals. To address this gap, we propose PolGS++, a physically-guided polarimetric Gaussian Splatting framework for fast reflective surface reconstruction. Specifically, we integrate a polarized BRDF (pBRDF) model into 3DGS to explicitly decouple diffuse and specular components, providing physically grounded reflectance modeling and stronger geometric cues for reflective surface recovery. Furthermore, we introduce a depth-guided visibility mask acquisition mechanism that enables angle-of-polarization (AoP)-based tangent-space consistency constraints in Gaussian Splatting without costly ray-tracing intersections. This physically guided design improves reconstruction quality and efficiency, requiring only about 10 minutes of training. Extensive experiments on both synthetic and real-world datasets validate the effectiveness of our method.
Towards Deeper Emotional Reflection: Crafting Affective Image Filters with Generative Priors
Dec 19, 2025

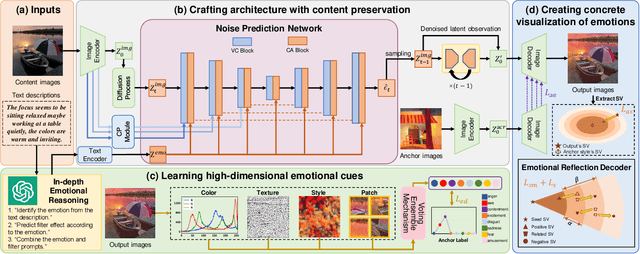

Social media platforms enable users to express emotions by posting text with accompanying images. In this paper, we propose the Affective Image Filter (AIF) task, which aims to reflect visually-abstract emotions from text into visually-concrete images, thereby creating emotionally compelling results. We first introduce the AIF dataset and the formulation of the AIF models. Then, we present AIF-B as an initial attempt based on a multi-modal transformer architecture. After that, we propose AIF-D as an extension of AIF-B towards deeper emotional reflection, effectively leveraging generative priors from pre-trained large-scale diffusion models. Quantitative and qualitative experiments demonstrate that AIF models achieve superior performance for both content consistency and emotional fidelity compared to state-of-the-art methods. Extensive user study experiments demonstrate that AIF models are significantly more effective at evoking specific emotions. Based on the presented results, we comprehensively discuss the value and potential of AIF models.
STAGE: Storyboard-Anchored Generation for Cinematic Multi-shot Narrative
Dec 13, 2025



While recent advancements in generative models have achieved remarkable visual fidelity in video synthesis, creating coherent multi-shot narratives remains a significant challenge. To address this, keyframe-based approaches have emerged as a promising alternative to computationally intensive end-to-end methods, offering the advantages of fine-grained control and greater efficiency. However, these methods often fail to maintain cross-shot consistency and capture cinematic language. In this paper, we introduce STAGE, a SToryboard-Anchored GEneration workflow to reformulate the keyframe-based multi-shot video generation task. Instead of using sparse keyframes, we propose STEP2 to predict a structural storyboard composed of start-end frame pairs for each shot. We introduce the multi-shot memory pack to ensure long-range entity consistency, the dual-encoding strategy for intra-shot coherence, and the two-stage training scheme to learn cinematic inter-shot transition. We also contribute the large-scale ConStoryBoard dataset, including high-quality movie clips with fine-grained annotations for story progression, cinematic attributes, and human preferences. Extensive experiments demonstrate that STAGE achieves superior performance in structured narrative control and cross-shot coherence.
PolarAnything: Diffusion-based Polarimetric Image Synthesis
Jul 24, 2025Polarization images facilitate image enhancement and 3D reconstruction tasks, but the limited accessibility of polarization cameras hinders their broader application. This gap drives the need for synthesizing photorealistic polarization images. The existing polarization simulator Mitsuba relies on a parametric polarization image formation model and requires extensive 3D assets covering shape and PBR materials, preventing it from generating large-scale photorealistic images. To address this problem, we propose PolarAnything, capable of synthesizing polarization images from a single RGB input with both photorealism and physical accuracy, eliminating the dependency on 3D asset collections. Drawing inspiration from the zero-shot performance of pretrained diffusion models, we introduce a diffusion-based generative framework with an effective representation strategy that preserves the fidelity of polarization properties. Experiments show that our model generates high-quality polarization images and supports downstream tasks like shape from polarization.
Audio-Sync Video Generation with Multi-Stream Temporal Control
Jun 09, 2025



Audio is inherently temporal and closely synchronized with the visual world, making it a naturally aligned and expressive control signal for controllable video generation (e.g., movies). Beyond control, directly translating audio into video is essential for understanding and visualizing rich audio narratives (e.g., Podcasts or historical recordings). However, existing approaches fall short in generating high-quality videos with precise audio-visual synchronization, especially across diverse and complex audio types. In this work, we introduce MTV, a versatile framework for audio-sync video generation. MTV explicitly separates audios into speech, effects, and music tracks, enabling disentangled control over lip motion, event timing, and visual mood, respectively -- resulting in fine-grained and semantically aligned video generation. To support the framework, we additionally present DEMIX, a dataset comprising high-quality cinematic videos and demixed audio tracks. DEMIX is structured into five overlapped subsets, enabling scalable multi-stage training for diverse generation scenarios. Extensive experiments demonstrate that MTV achieves state-of-the-art performance across six standard metrics spanning video quality, text-video consistency, and audio-video alignment. Project page: https://hjzheng.net/projects/MTV/.
Affective Image Editing: Shaping Emotional Factors via Text Descriptions
May 24, 2025In daily life, images as common affective stimuli have widespread applications. Despite significant progress in text-driven image editing, there is limited work focusing on understanding users' emotional requests. In this paper, we introduce AIEdiT for Affective Image Editing using Text descriptions, which evokes specific emotions by adaptively shaping multiple emotional factors across the entire images. To represent universal emotional priors, we build the continuous emotional spectrum and extract nuanced emotional requests. To manipulate emotional factors, we design the emotional mapper to translate visually-abstract emotional requests to visually-concrete semantic representations. To ensure that editing results evoke specific emotions, we introduce an MLLM to supervise the model training. During inference, we strategically distort visual elements and subsequently shape corresponding emotional factors to edit images according to users' instructions. Additionally, we introduce a large-scale dataset that includes the emotion-aligned text and image pair set for training and evaluation. Extensive experiments demonstrate that AIEdiT achieves superior performance, effectively reflecting users' emotional requests.
M-DocSum: Do LVLMs Genuinely Comprehend Interleaved Image-Text in Document Summarization?
Mar 27, 2025



We investigate a critical yet under-explored question in Large Vision-Language Models (LVLMs): Do LVLMs genuinely comprehend interleaved image-text in the document? Existing document understanding benchmarks often assess LVLMs using question-answer formats, which are information-sparse and difficult to guarantee the coverage of long-range dependencies. To address this issue, we introduce a novel and challenging Multimodal Document Summarization Benchmark (M-DocSum-Bench), which comprises 500 high-quality arXiv papers, along with interleaved multimodal summaries aligned with human preferences. M-DocSum-Bench is a reference-based generation task and necessitates the generation of interleaved image-text summaries using provided reference images, thereby simultaneously evaluating capabilities in understanding, reasoning, localization, and summarization within complex multimodal document scenarios. To facilitate this benchmark, we develop an automated framework to construct summaries and propose a fine-grained evaluation method called M-DocEval. Moreover, we further develop a robust summarization baseline, i.e., M-DocSum-7B, by progressive two-stage training with diverse instruction and preference data. The extensive results on our M-DocSum-Bench reveal that the leading LVLMs struggle to maintain coherence and accurately integrate information within long and interleaved contexts, often exhibiting confusion between similar images and a lack of robustness. Notably, M-DocSum-7B achieves state-of-the-art performance compared to larger and closed-source models (including GPT-4o, Gemini Pro, Claude-3.5-Sonnet and Qwen2.5-VL-72B, etc.), demonstrating the potential of LVLMs for improved interleaved image-text understanding. The code, data, and models are available at https://github.com/stepfun-ai/M-DocSum-Bench.