 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
M-DocSum: Do LVLMs Genuinely Comprehend Interleaved Image-Text in Document Summarization?
Mar 27, 2025



We investigate a critical yet under-explored question in Large Vision-Language Models (LVLMs): Do LVLMs genuinely comprehend interleaved image-text in the document? Existing document understanding benchmarks often assess LVLMs using question-answer formats, which are information-sparse and difficult to guarantee the coverage of long-range dependencies. To address this issue, we introduce a novel and challenging Multimodal Document Summarization Benchmark (M-DocSum-Bench), which comprises 500 high-quality arXiv papers, along with interleaved multimodal summaries aligned with human preferences. M-DocSum-Bench is a reference-based generation task and necessitates the generation of interleaved image-text summaries using provided reference images, thereby simultaneously evaluating capabilities in understanding, reasoning, localization, and summarization within complex multimodal document scenarios. To facilitate this benchmark, we develop an automated framework to construct summaries and propose a fine-grained evaluation method called M-DocEval. Moreover, we further develop a robust summarization baseline, i.e., M-DocSum-7B, by progressive two-stage training with diverse instruction and preference data. The extensive results on our M-DocSum-Bench reveal that the leading LVLMs struggle to maintain coherence and accurately integrate information within long and interleaved contexts, often exhibiting confusion between similar images and a lack of robustness. Notably, M-DocSum-7B achieves state-of-the-art performance compared to larger and closed-source models (including GPT-4o, Gemini Pro, Claude-3.5-Sonnet and Qwen2.5-VL-72B, etc.), demonstrating the potential of LVLMs for improved interleaved image-text understanding. The code, data, and models are available at https://github.com/stepfun-ai/M-DocSum-Bench.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.
CheapNET: Improving Light-weight speech enhancement network by projected loss function
Nov 27, 2023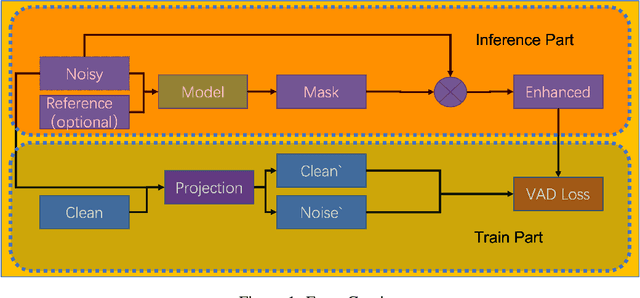
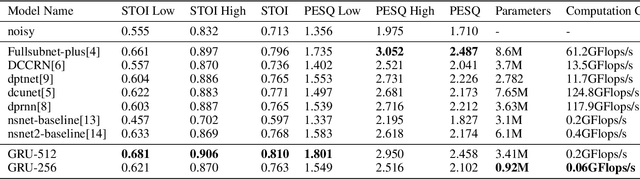
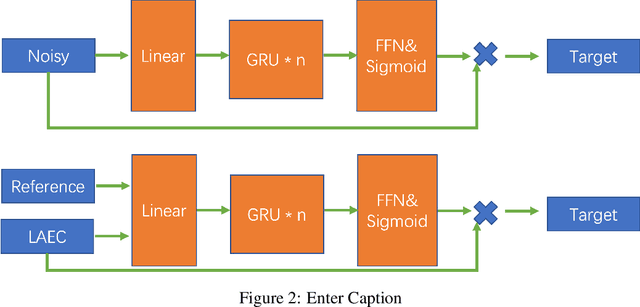
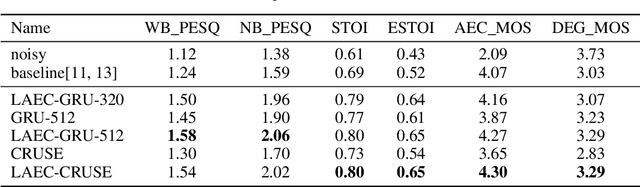
Noise suppression and echo cancellation are critical in speech enhancement and essential for smart devices and real-time communication. Deployed in voice processing front-ends and edge devices, these algorithms must ensure efficient real-time inference with low computational demands. Traditional edge-based noise suppression often uses MSE-based amplitude spectrum mask training, but this approach has limitations. We introduce a novel projection loss function, diverging from MSE, to enhance noise suppression. This method uses projection techniques to isolate key audio components from noise, significantly improving model performance. For echo cancellation, the function enables direct predictions on LAEC pre-processed outputs, substantially enhancing performance. Our noise suppression model achieves near state-of-the-art results with only 3.1M parameters and 0.4GFlops/s computational load. Moreover, our echo cancellation model outperforms replicated industry-leading models, introducing a new perspective in speech enhancement.