 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheapNET: Improving Light-weight speech enhancement network by projected loss function
Nov 27, 2023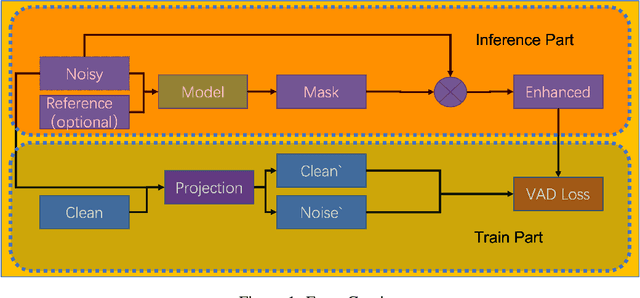
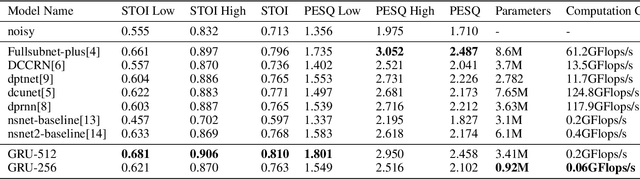
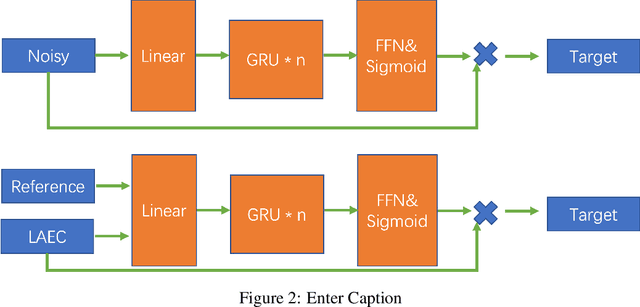
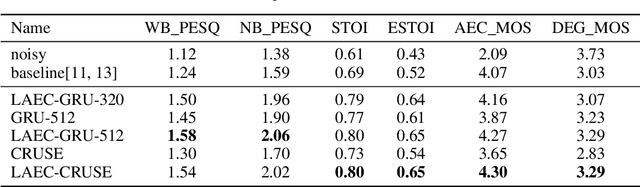
Noise suppression and echo cancellation are critical in speech enhancement and essential for smart devices and real-time communication. Deployed in voice processing front-ends and edge devices, these algorithms must ensure efficient real-time inference with low computational demands. Traditional edge-based noise suppression often uses MSE-based amplitude spectrum mask training, but this approach has limitations. We introduce a novel projection loss function, diverging from MSE, to enhance noise suppression. This method uses projection techniques to isolate key audio components from noise, significantly improving model performance. For echo cancellation, the function enables direct predictions on LAEC pre-processed outputs, substantially enhancing performance. Our noise suppression model achieves near state-of-the-art results with only 3.1M parameters and 0.4GFlops/s computational load. Moreover, our echo cancellation model outperforms replicated industry-leading models, introducing a new perspective in speech enhancement.
ACQ: Improving Generative Data-free Quantization Via Attention Correction
Jan 18, 2023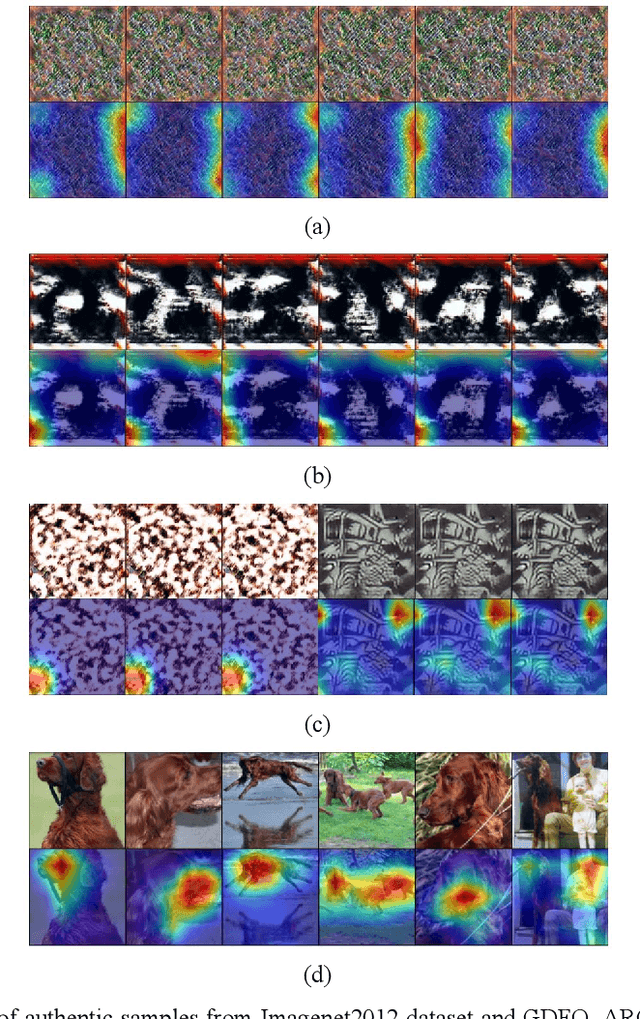

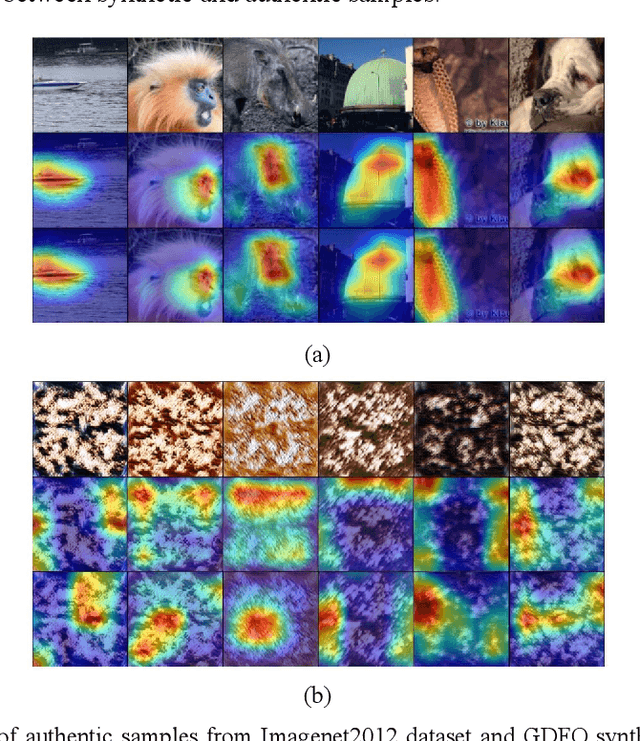
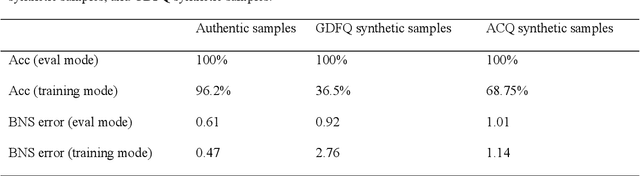
Data-free quantization aims to achieve model quantization without accessing any authentic sample. It is significant in an application-oriented context involving data privacy. Converting noise vectors into synthetic samples through a generator is a popular data-free quantization method, which is called generative data-free quantization. However, there is a difference in attention between synthetic samples and authentic samples. This is always ignored and restricts the quantization performance. First, since synthetic samples of the same class are prone to have homogenous attention, the quantized network can only learn limited modes of attention. Second, synthetic samples in eval mode and training mode exhibit different attention. Hence, the batch-normalization statistics matching tends to be inaccurate. ACQ is proposed in this paper to fix the attention of synthetic samples. An attention center position-condition generator is established regarding the homogenization of intra-class attention. Restricted by the attention center matching loss, the attention center position is treated as the generator's condition input to guide synthetic samples in obtaining diverse attention. Moreover, we design adversarial loss of paired synthetic samples under the same condition to prevent the generator from paying overmuch attention to the condition, which may result in mode collapse. To improve the attention similarity of synthetic samples in different network modes, we introduce a consistency penalty to guarantee accurate BN statistics matching. The experimental results demonstrate that ACQ effectively improves the attention problems of synthetic samples. Under various training settings, ACQ achieves the best quantization performance. For the 4-bit quantization of Resnet18 and Resnet50, ACQ reaches 67.55% and 72.23% accuracy, respectively.