 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Classification to Generation: An Open-Ended Paradigm for Adverse Drug Reaction Prediction Based on Graph-Motif Feature Fusion
Jan 04, 2026Computational biology offers immense potential for reducing the high costs and protracted cycles of new drug development through adverse drug reaction (ADR) prediction. However, current methods remain impeded by drug data scarcity-induced cold-start challenge, closed label sets, and inadequate modeling of label dependencies. Here we propose an open-ended ADR prediction paradigm based on Graph-Motif feature fusion and Multi-Label Generation (GM-MLG). Leveraging molecular structure as an intrinsic and inherent feature, GM-MLG constructs a dual-graph representation architecture spanning the atomic level, the local molecular level (utilizing fine-grained motifs dynamically extracted via the BRICS algorithm combined with additional fragmentation rules), and the global molecular level. Uniquely, GM-MLG pioneers transforming ADR prediction from multi-label classification into Transformer Decoder-based multi-label generation. By treating ADR labels as discrete token sequences, it employs positional embeddings to explicitly capture dependencies and co-occurrence relationships within large-scale label spaces, generating predictions via autoregressive decoding to dynamically expand the prediction space. Experiments demonstrate GM-MLG achieves up to 38% improvement and an average gain of 20%, expanding the prediction space from 200 to over 10,000 types. Furthermore, it elucidates non-linear structure-activity relationships between ADRs and motifs via retrosynthetic motif analysis, providing interpretable and innovative support for systematic risk reduction in drug safety.
Textual-Knowledge-Guided Numerical Feature Discovery Method for Power Demand Forecasting
Nov 30, 2023



Power demand forecasting is a crucial and challenging task for new power system and integrated energy system. However, as public feature databases and the theoretical mechanism of power demand changes are unavailable, the known features of power demand fluctuation are much limited. Recently, multimodal learning approaches have shown great vitality in machine learning and AIGC. In this paper, we interact two modal data and propose a textual-knowledge-guided numerical feature discovery (TKNFD) method for short-term power demand forecasting. TKNFD extensively accumulates qualitative textual knowledge, expands it into a candidate feature-type set, collects numerical data of these features, and eventually builds four-dimensional multivariate source-tracking databases (4DM-STDs). Next, TKNFD presents a two-level quantitative feature identification strategy independent of forecasting models, finds 43-48 features, and systematically analyses feature contribution and dependency correlation. Benchmark experiments in two different regions around the world demonstrate that the forecasting accuracy of TKNFD-discovered features reliably outperforms that of SoTA feature schemes by 16.84% to 36.36% MAPE. In particular, TKNFD reveals many unknown features, especially several dominant features in the unknown energy and astronomical dimensions, which extend the knowledge on the origin of strong randomness and non-linearity in power demand fluctuation. Besides, 4DM-STDs can serve as public baseline databases.
ACQ: Improving Generative Data-free Quantization Via Attention Correction
Jan 18, 2023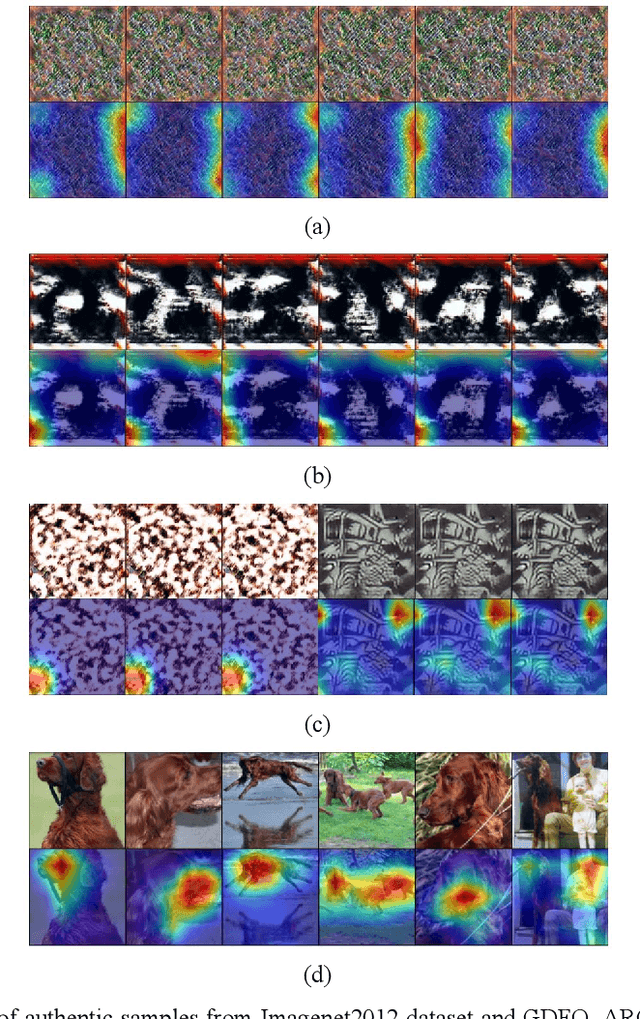

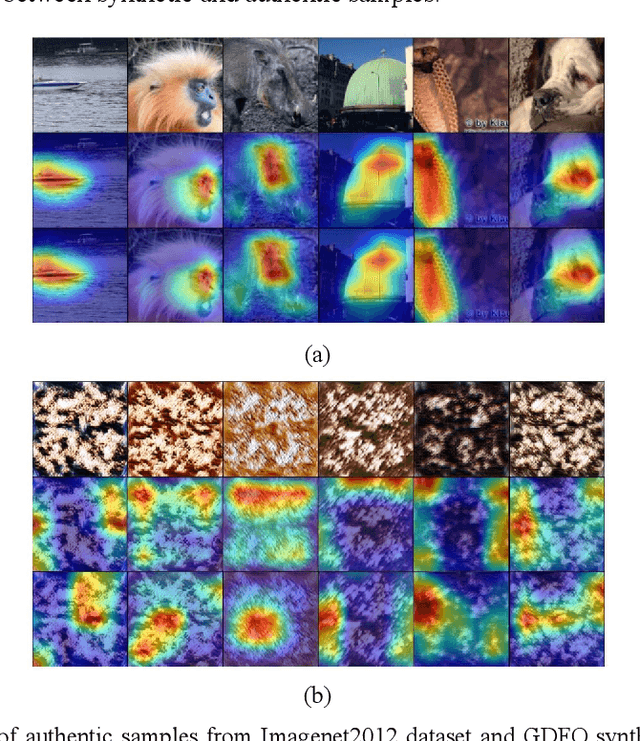
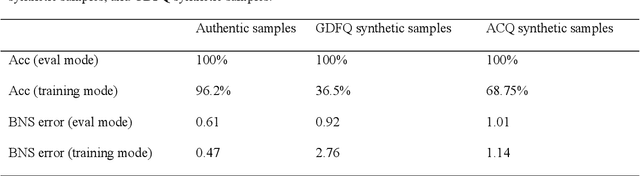
Data-free quantization aims to achieve model quantization without accessing any authentic sample. It is significant in an application-oriented context involving data privacy. Converting noise vectors into synthetic samples through a generator is a popular data-free quantization method, which is called generative data-free quantization. However, there is a difference in attention between synthetic samples and authentic samples. This is always ignored and restricts the quantization performance. First, since synthetic samples of the same class are prone to have homogenous attention, the quantized network can only learn limited modes of attention. Second, synthetic samples in eval mode and training mode exhibit different attention. Hence, the batch-normalization statistics matching tends to be inaccurate. ACQ is proposed in this paper to fix the attention of synthetic samples. An attention center position-condition generator is established regarding the homogenization of intra-class attention. Restricted by the attention center matching loss, the attention center position is treated as the generator's condition input to guide synthetic samples in obtaining diverse attention. Moreover, we design adversarial loss of paired synthetic samples under the same condition to prevent the generator from paying overmuch attention to the condition, which may result in mode collapse. To improve the attention similarity of synthetic samples in different network modes, we introduce a consistency penalty to guarantee accurate BN statistics matching. The experimental results demonstrate that ACQ effectively improves the attention problems of synthetic samples. Under various training settings, ACQ achieves the best quantization performance. For the 4-bit quantization of Resnet18 and Resnet50, ACQ reaches 67.55% and 72.23% accuracy, respectively.
Uncovering Dominant Features in Short-term Power Load Forecasting Based on Multi-source Feature
Mar 23, 2021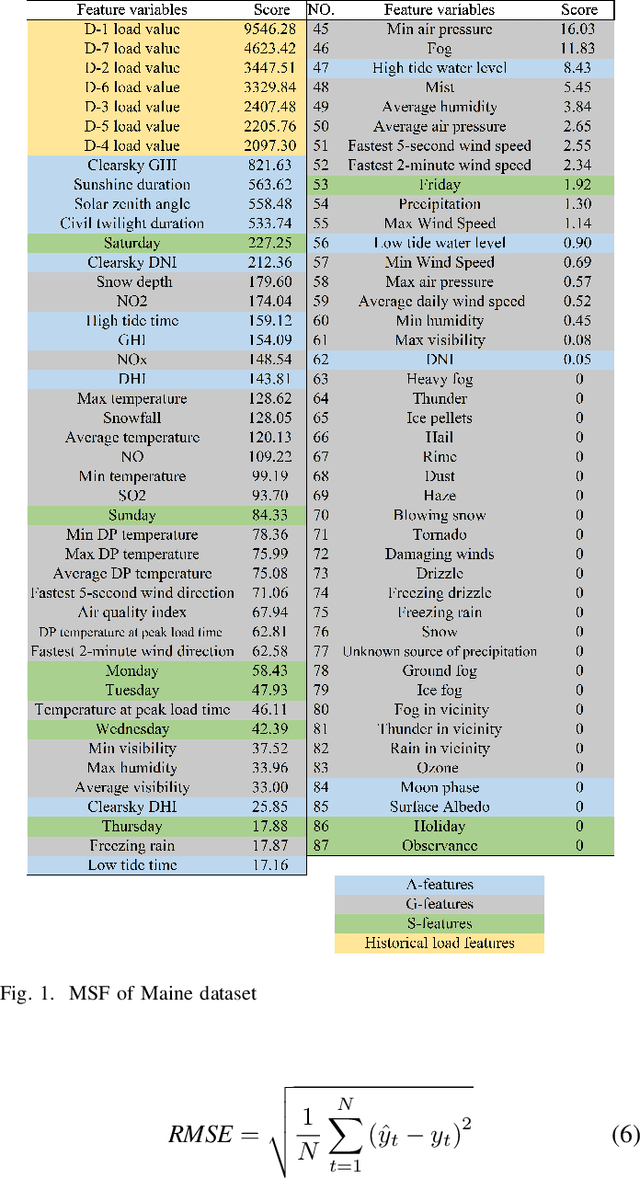

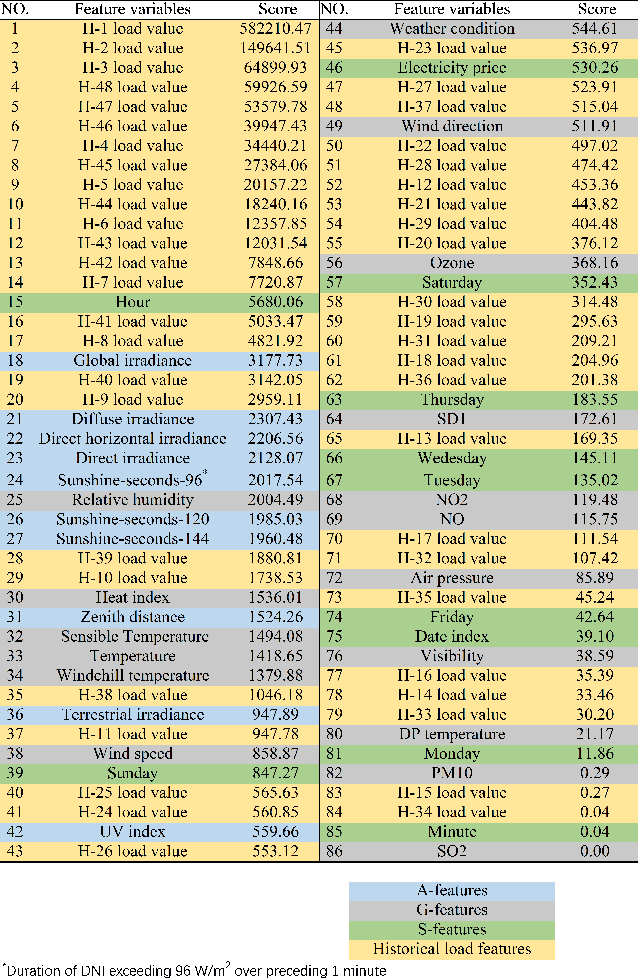

Due to the limitation of data availability, traditional power load forecasting methods focus more on studying the load variation pattern and the influence of only a few factors such as temperature and holidays, which fail to reveal the inner mechanism of load variation. This paper breaks the limitation and collects 80 potential features from astronomy, geography, and society to study the complex nexus between power load variation and influence factors, based on which a short-term power load forecasting method is proposed. Case studies show that, compared with the state-of-the-art methods, the proposed method improves the forecasting accuracy by 33.0% to 34.7%. The forecasting result reveals that geographical features have the most significant impact on improving the load forecasting accuracy, in which temperature is the dominant feature. Astronomical features have more significant influence than social features and features related to the sun play an important role, which are obviously ignored in previous research. Saturday and Monday are the most important social features. Temperature, solar zenith angle, civil twilight duration, and lagged clear sky global horizontal irradiance have a V-shape relationship with power load, indicating that there exist balance points for them. Global horizontal irradiance is negatively related to power load.
Deep Template Matching for Offline Handwritten Chinese Character Recognition
Nov 15, 2018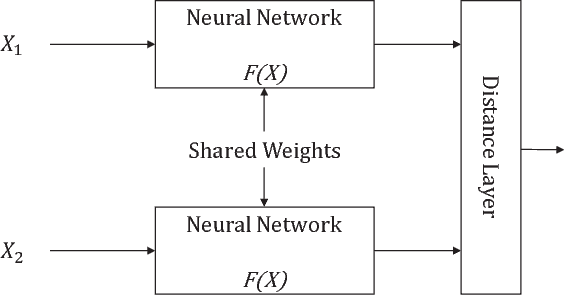

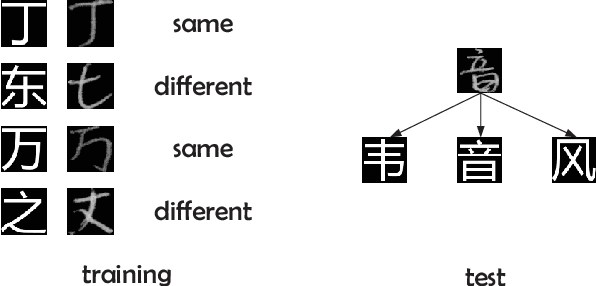

Just like its remarkable achievements in many computer vision tasks, the convolutional neural networks (CNN) provide an end-to-end solution in handwritten Chinese character recognition (HCCR) with great success. However, the process of learning discriminative features for image recognition is difficult in cases where little data is available. In this paper, we propose a novel method for learning siamese neural network which employ a special structure to predict the similarity between handwritten Chinese characters and template images. The optimization of siamese neural network can be treated as a simple binary classification problem. When the training process has been finished, the powerful discriminative features help us to generalize the predictive power not just to new data, but to entirely new classes that never appear in the training set. Experiments performed on the ICDAR-2013 offline HCCR datasets have shown that the proposed method has a very promising generalization ability to the new classes that never appear in the training set.
Building Efficient CNN Architecture for Offline Handwritten Chinese Character Recognition
Apr 08, 2018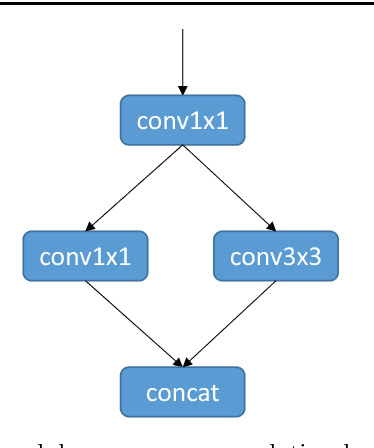
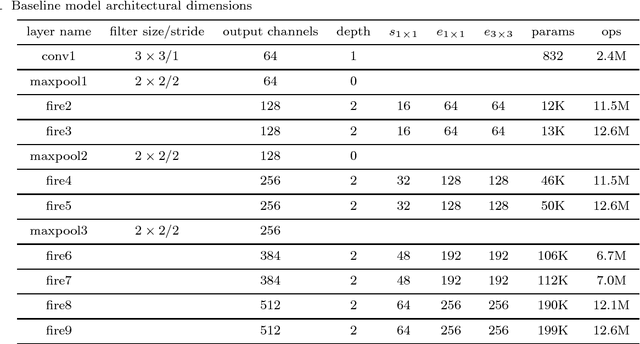
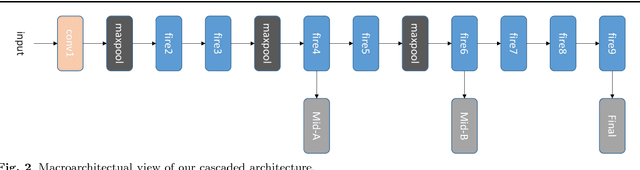
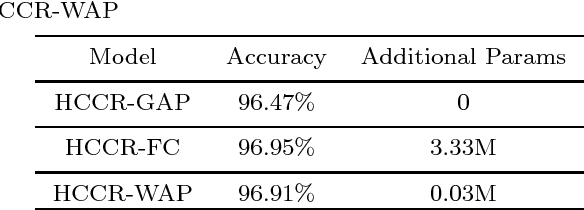
Deep convolutional networks based methods have brought great breakthrough in images classification, which provides an end-to-end solution for handwritten Chinese character recognition(HCCR) problem through learning discriminative features automatically. Nevertheless, state-of-the-art CNNs appear to incur huge computation cost, and require the storage of a large number of parameters especially in fully connected layers, which is difficult to deploy such networks into alternative hardware device with the limit of computation amount. To solve the storage problem, we propose a novel technique called Global Weighted Arverage Pooling for reducing the parameters in fully connected layer without loss in accuracy. Besides, we implement a cascaded model in single CNN by adding mid output layer to complete recognition as early as possible, which reduces average inference time significantly. Experiments were performed on the ICDAR-2013 offline HCCR dataset, and it is found that the proposed approach only needs 6.9ms for classfying a chracter image on average, and achieves the state-of-the-art accuracy of 97.1% while requiring only 3.3MB for storage.