 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComponent-Level Lesioning of Language Models Reveals Clinically Aligned Aphasia Phenotypes
Jan 27, 2026Large language models (LLMs) increasingly exhibit human-like linguistic behaviors and internal representations that they could serve as computational simulators of language cognition. We ask whether LLMs can be systematically manipulated to reproduce language-production impairments characteristic of aphasia following focal brain lesions. Such models could provide scalable proxies for testing rehabilitation hypotheses, and offer a controlled framework for probing the functional organization of language. We introduce a clinically grounded, component-level framework that simulates aphasia by selectively perturbing functional components in LLMs, and apply it to both modular Mixture-of-Experts models and dense Transformers using a unified intervention interface. Our pipeline (i) identifies subtype-linked components for Broca's and Wernicke's aphasia, (ii) interprets these components with linguistic probing tasks, and (iii) induces graded impairments by progressively perturbing the top-k subtype-linked components, evaluating outcomes with Western Aphasia Battery (WAB) subtests summarized by Aphasia Quotient (AQ). Across architectures and lesioning strategies, subtype-targeted perturbations yield more systematic, aphasia-like regressions than size-matched random perturbations, and MoE modularity supports more localized and interpretable phenotype-to-component mappings. These findings suggest that modular LLMs, combined with clinically informed component perturbations, provide a promising platform for simulating aphasic language production and studying how distinct language functions degrade under targeted disruptions.
Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
Apr 06, 2024
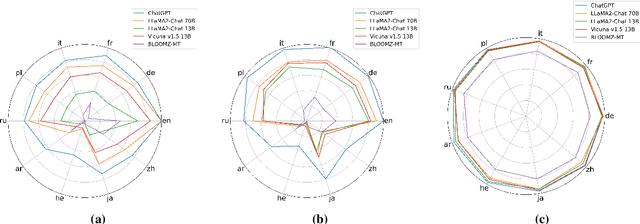


Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.
Measuring Meaning Composition in the Human Brain with Composition Scores from Large Language Models
Mar 07, 2024The process of meaning composition, wherein smaller units like morphemes or words combine to form the meaning of phrases and sentences, is essential for human sentence comprehension. Despite extensive neurolinguistic research into the brain regions involved in meaning composition, a computational metric to quantify the extent of composition is still lacking. Drawing on the key-value memory interpretation of transformer feed-forward network blocks, we introduce the Composition Score, a novel model-based metric designed to quantify the degree of meaning composition during sentence comprehension. Experimental findings show that this metric correlates with brain clusters associated with word frequency, structural processing, and general sensitivity to words, suggesting the multifaceted nature of meaning composition during human sentence comprehension.
Roles of Scaling and Instruction Tuning in Language Perception: Model vs. Human Attention
Oct 29, 2023



Recent large language models (LLMs) have revealed strong abilities to understand natural language. Since most of them share the same basic structure, i.e. the transformer block, possible contributors to their success in the training process are scaling and instruction tuning. However, how these factors affect the models' language perception is unclear. This work compares the self-attention of several existing LLMs (LLaMA, Alpaca and Vicuna) in different sizes (7B, 13B, 30B, 65B), together with eye saccade, an aspect of human reading attention, to assess the effect of scaling and instruction tuning on language perception. Results show that scaling enhances the human resemblance and improves the effective attention by reducing the trivial pattern reliance, while instruction tuning does not. However, instruction tuning significantly enhances the models' sensitivity to instructions. We also find that current LLMs are consistently closer to non-native than native speakers in attention, suggesting a sub-optimal language perception of all models. Our code and data used in the analysis is available on GitHub.
ACQ: Improving Generative Data-free Quantization Via Attention Correction
Jan 18, 2023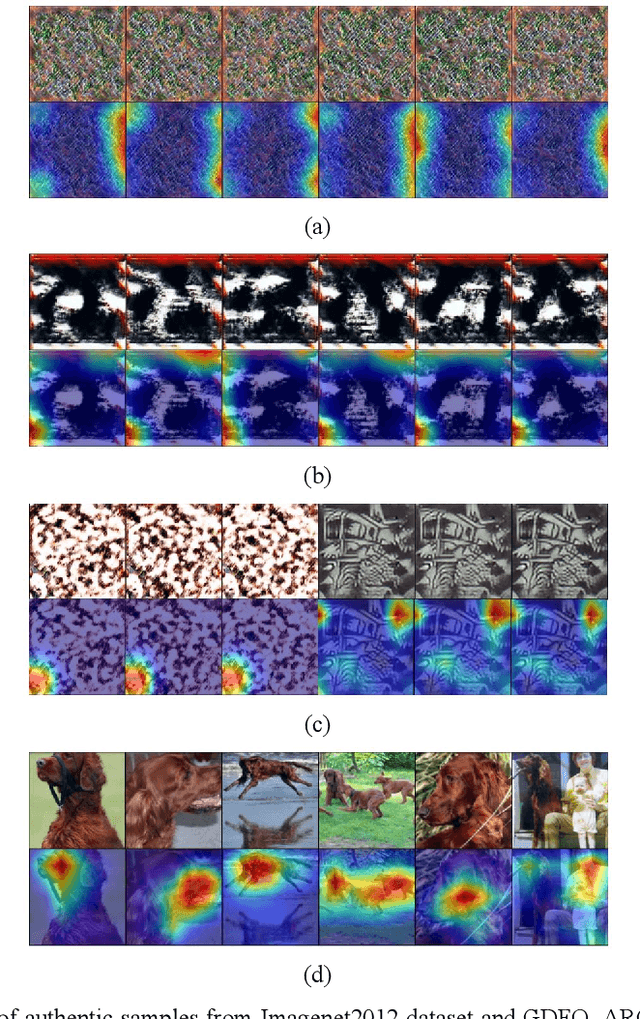

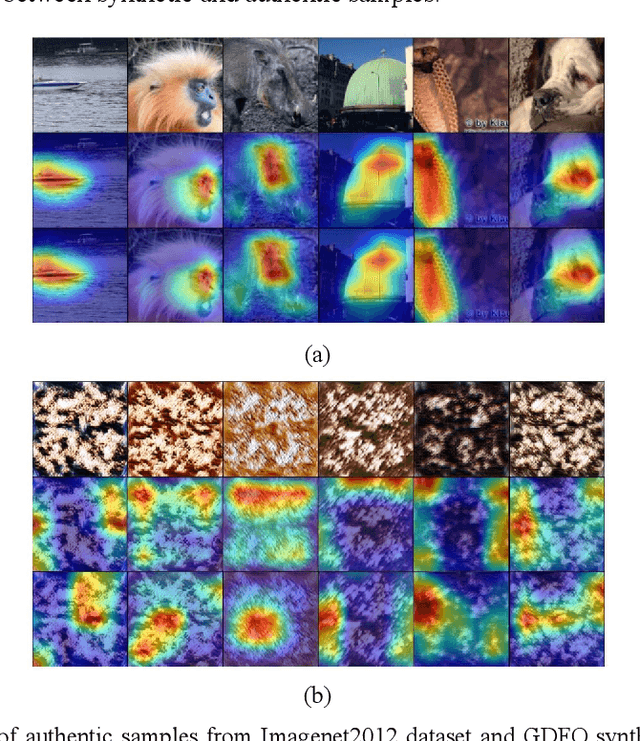
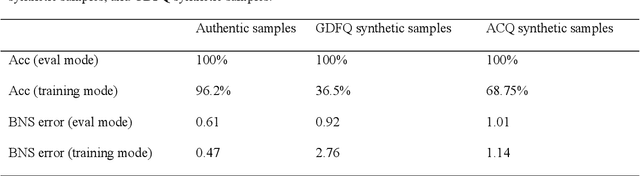
Data-free quantization aims to achieve model quantization without accessing any authentic sample. It is significant in an application-oriented context involving data privacy. Converting noise vectors into synthetic samples through a generator is a popular data-free quantization method, which is called generative data-free quantization. However, there is a difference in attention between synthetic samples and authentic samples. This is always ignored and restricts the quantization performance. First, since synthetic samples of the same class are prone to have homogenous attention, the quantized network can only learn limited modes of attention. Second, synthetic samples in eval mode and training mode exhibit different attention. Hence, the batch-normalization statistics matching tends to be inaccurate. ACQ is proposed in this paper to fix the attention of synthetic samples. An attention center position-condition generator is established regarding the homogenization of intra-class attention. Restricted by the attention center matching loss, the attention center position is treated as the generator's condition input to guide synthetic samples in obtaining diverse attention. Moreover, we design adversarial loss of paired synthetic samples under the same condition to prevent the generator from paying overmuch attention to the condition, which may result in mode collapse. To improve the attention similarity of synthetic samples in different network modes, we introduce a consistency penalty to guarantee accurate BN statistics matching. The experimental results demonstrate that ACQ effectively improves the attention problems of synthetic samples. Under various training settings, ACQ achieves the best quantization performance. For the 4-bit quantization of Resnet18 and Resnet50, ACQ reaches 67.55% and 72.23% accuracy, respectively.
Quantifying Discourse Support for Omitted Pronouns
Sep 16, 2022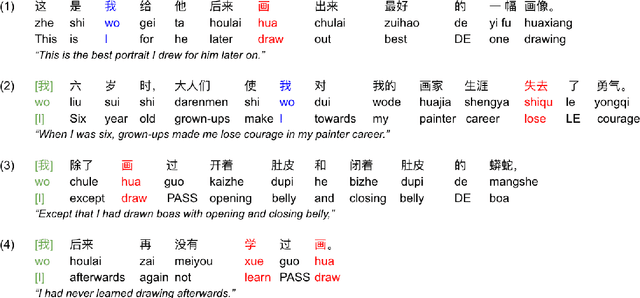
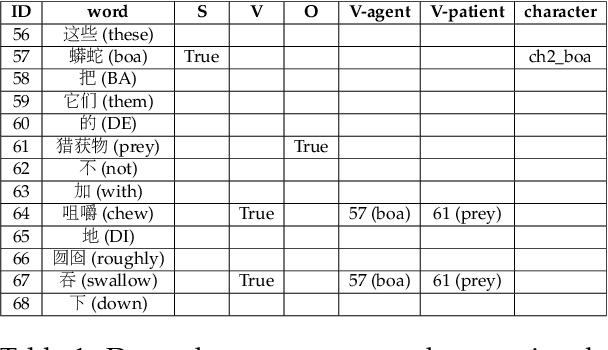
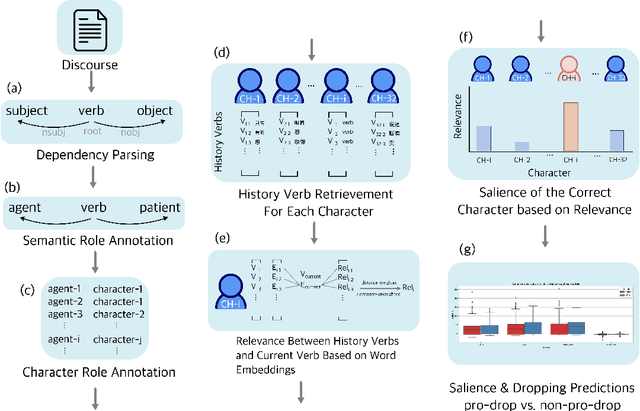
Pro-drop is commonly seen in many languages, but its discourse motivations have not been well characterized. Inspired by the topic chain theory in Chinese, this study shows how character-verb usage continuity distinguishes dropped pronouns from overt references to story characters. We model the choice to drop vs. not drop as a function of character-verb continuity. The results show that omitted subjects have higher character history-current verb continuity salience than non-omitted subjects. This is consistent with the idea that discourse coherence with a particular topic, such as a story character, indeed facilitates the omission of pronouns in languages and contexts where they are optional.