 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Lesions in Multilingual Language Models Separate Shared and Language-specific Brain Alignment
Apr 12, 2026How the brain supports language across different languages is a basic question in neuroscience and a useful test for multilingual artificial intelligence. Neuroimaging has identified language-responsive brain regions across languages, but it cannot by itself show whether the underlying processing is shared or language-specific. Here we use six multilingual large language models (LLMs) as controllable systems and create targeted ``computational lesions'' by zeroing small parameter sets that are important across languages or especially important for one language. We then compare intact and lesioned models in predicting functional magnetic resonance imaging (fMRI) responses during 100 minutes of naturalistic story listening in native English, Chinese and French (112 participants). Lesioning a compact shared core reduces whole-brain encoding correlation by 60.32% relative to intact models, whereas language-specific lesions preserve cross-language separation in embedding space but selectively weaken brain predictivity for the matched native language. These results support a shared backbone with embedded specializations and provide a causal framework for studying multilingual brain-model alignment.
Transformation vs Tradition: Artificial General Intelligence (AGI) for Arts and Humanities
Oct 30, 2023
Recent advances in artificial general intelligence (AGI), particularly large language models and creative image generation systems have demonstrated impressive capabilities on diverse tasks spanning the arts and humanities. However, the swift evolution of AGI has also raised critical questions about its responsible deployment in these culturally significant domains traditionally seen as profoundly human. This paper provides a comprehensive analysis of the applications and implications of AGI for text, graphics, audio, and video pertaining to arts and the humanities. We survey cutting-edge systems and their usage in areas ranging from poetry to history, marketing to film, and communication to classical art. We outline substantial concerns pertaining to factuality, toxicity, biases, and public safety in AGI systems, and propose mitigation strategies. The paper argues for multi-stakeholder collaboration to ensure AGI promotes creativity, knowledge, and cultural values without undermining truth or human dignity. Our timely contribution summarizes a rapidly developing field, highlighting promising directions while advocating for responsible progress centering on human flourishing. The analysis lays the groundwork for further research on aligning AGI's technological capacities with enduring social goods.
Quantifying Discourse Support for Omitted Pronouns
Sep 16, 2022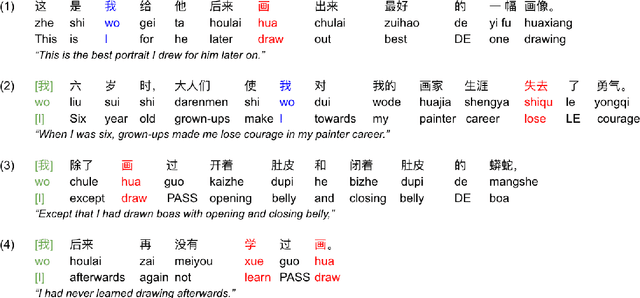
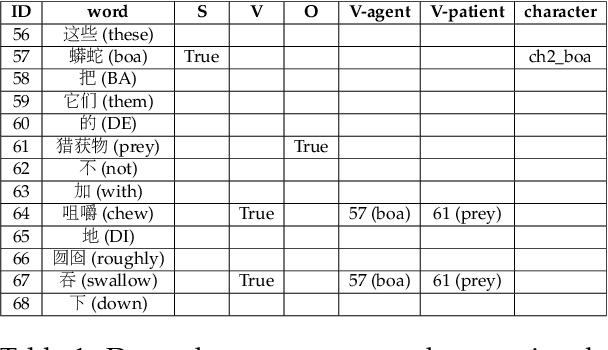
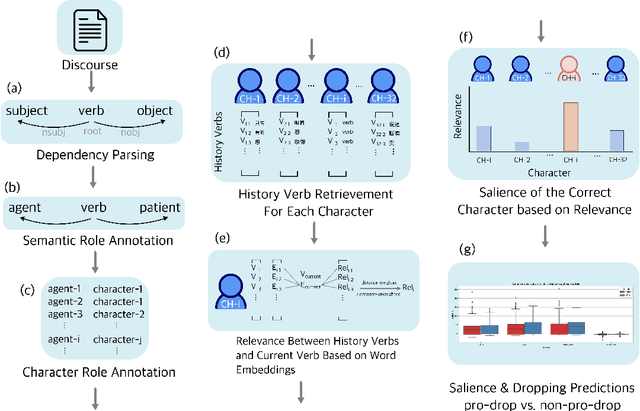
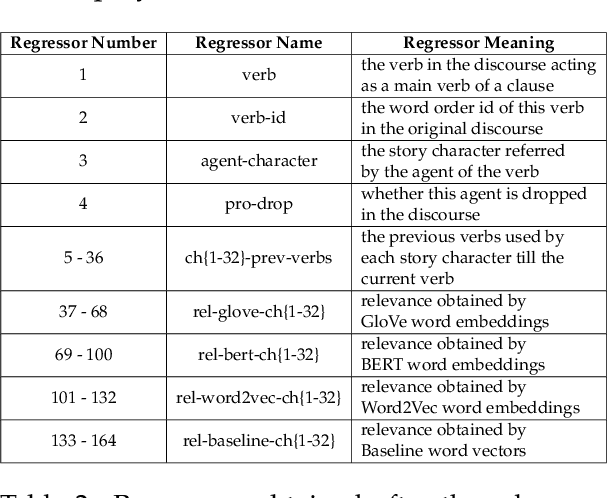
Pro-drop is commonly seen in many languages, but its discourse motivations have not been well characterized. Inspired by the topic chain theory in Chinese, this study shows how character-verb usage continuity distinguishes dropped pronouns from overt references to story characters. We model the choice to drop vs. not drop as a function of character-verb continuity. The results show that omitted subjects have higher character history-current verb continuity salience than non-omitted subjects. This is consistent with the idea that discourse coherence with a particular topic, such as a story character, indeed facilitates the omission of pronouns in languages and contexts where they are optional.
Neural Language Models are not Born Equal to Fit Brain Data, but Training Helps
Jul 07, 2022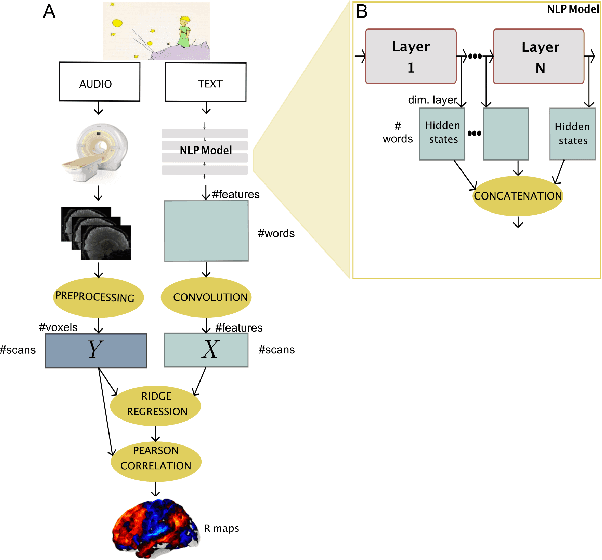
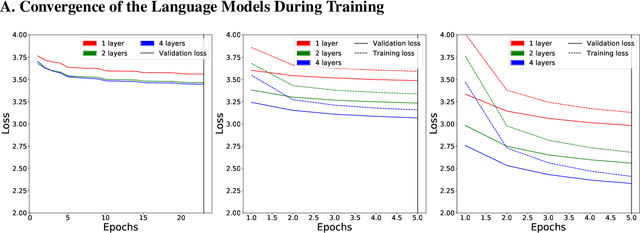
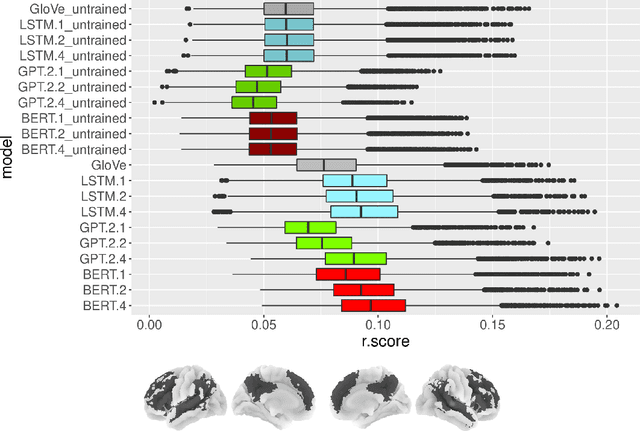
Neural Language Models (NLMs) have made tremendous advances during the last years, achieving impressive performance on various linguistic tasks. Capitalizing on this, studies in neuroscience have started to use NLMs to study neural activity in the human brain during language processing. However, many questions remain unanswered regarding which factors determine the ability of a neural language model to capture brain activity (aka its 'brain score'). Here, we make first steps in this direction and examine the impact of test loss, training corpus and model architecture (comparing GloVe, LSTM, GPT-2 and BERT), on the prediction of functional Magnetic Resonance Imaging timecourses of participants listening to an audiobook. We find that (1) untrained versions of each model already explain significant amount of signal in the brain by capturing similarity in brain responses across identical words, with the untrained LSTM outperforming the transformerbased models, being less impacted by the effect of context; (2) that training NLP models improves brain scores in the same brain regions irrespective of the model's architecture; (3) that Perplexity (test loss) is not a good predictor of brain score; (4) that training data have a strong influence on the outcome and, notably, that off-the-shelf models may lack statistical power to detect brain activations. Overall, we outline the impact of modeltraining choices, and suggest good practices for future studies aiming at explaining the human language system using neural language models.
Finding Syntax in Human Encephalography with Beam Search
Jun 11, 2018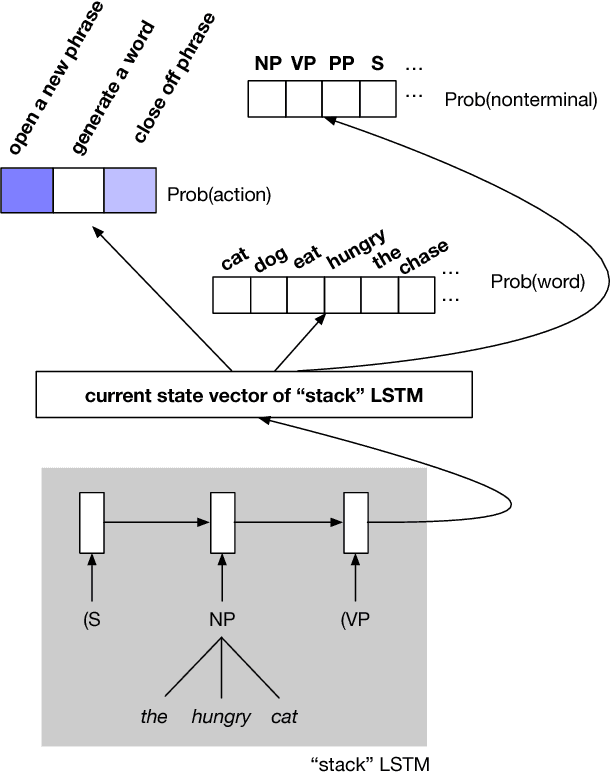

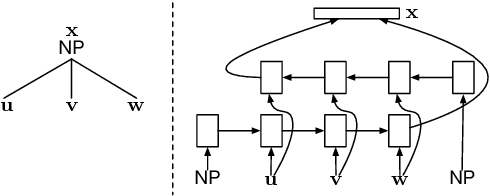

Recurrent neural network grammars (RNNGs) are generative models of (tree,string) pairs that rely on neural networks to evaluate derivational choices. Parsing with them using beam search yields a variety of incremental complexity metrics such as word surprisal and parser action count. When used as regressors against human electrophysiological responses to naturalistic text, they derive two amplitude effects: an early peak and a P600-like later peak. By contrast, a non-syntactic neural language model yields no reliable effects. Model comparisons attribute the early peak to syntactic composition within the RNNG. This pattern of results recommends the RNNG+beam search combination as a mechanistic model of the syntactic processing that occurs during normal human language comprehension.