 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtStructQA: A Denotation Threshold in Protein Structural Reasoning
May 30, 2026Protein-language systems are often evaluated by whether they generate plausible biological text, but a structural question has a sharper semantics: it denotes a measurement in a 3D coordinate system. We introduce ProtStructQA, an executable benchmark for protein structural question answering in which each natural-language question is generated from a hidden typed domain-specific language (DSL) program and the answer is obtained by executing that program on an AlphaFold-predicted structure. ProtStructQA releases 382.2K questions covering confidence, distances, predicted aligned error (PAE), solvent exposure, secondary structure, topology and contacts, and held-out compositions: a 330K active benchmark over 10K proteins from four species, plus a 52.2K hard-negative robustness pool. Without fine-tuning, we evaluate Qwen3 models from 0.6B to 8B under direct prompting, chain-of-thought, grammar-constrained executable voting, executable voting with chain-of-thought, and multi-turn ReAct-style tool use, and replicate the headline finding on Gemma-3-1B and Gemma-3-12B. We find a capability-dependent denotation threshold between Qwen3-1.7B and Qwen3-4B: below it, tool-mediated ReAct dominates because models often fail to produce executable denotations; above it, chain-of-thought flips from mostly harmful to strongly beneficial and becomes the strongest strategy on most splits. Parse-failure and family-level analyses show that the threshold is a transition from unparseable language to executable structural denotation, while grammar and execution remain selectively valuable for PAE and secondary-structure queries. ProtStructQA reframes scientific QA as compilation from language to measurement and provides a diagnostic testbed for when language models can map words to executable 3D structural measurements.
Transformation vs Tradition: Artificial General Intelligence (AGI) for Arts and Humanities
Oct 30, 2023
Recent advances in artificial general intelligence (AGI), particularly large language models and creative image generation systems have demonstrated impressive capabilities on diverse tasks spanning the arts and humanities. However, the swift evolution of AGI has also raised critical questions about its responsible deployment in these culturally significant domains traditionally seen as profoundly human. This paper provides a comprehensive analysis of the applications and implications of AGI for text, graphics, audio, and video pertaining to arts and the humanities. We survey cutting-edge systems and their usage in areas ranging from poetry to history, marketing to film, and communication to classical art. We outline substantial concerns pertaining to factuality, toxicity, biases, and public safety in AGI systems, and propose mitigation strategies. The paper argues for multi-stakeholder collaboration to ensure AGI promotes creativity, knowledge, and cultural values without undermining truth or human dignity. Our timely contribution summarizes a rapidly developing field, highlighting promising directions while advocating for responsible progress centering on human flourishing. The analysis lays the groundwork for further research on aligning AGI's technological capacities with enduring social goods.
Comparing Machine Learning Techniques for Alfalfa Biomass Yield Prediction
Oct 20, 2022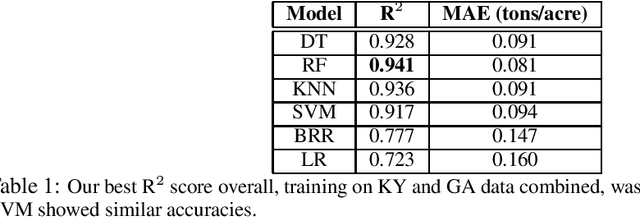
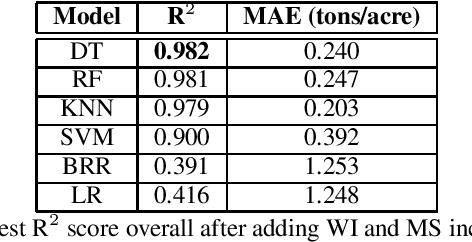
The alfalfa crop is globally important as livestock feed, so highly efficient planting and harvesting could benefit many industries, especially as the global climate changes and traditional methods become less accurate. Recent work using machine learning (ML) to predict yields for alfalfa and other crops has shown promise. Previous efforts used remote sensing, weather, planting, and soil data to train machine learning models for yield prediction. However, while remote sensing works well, the models require large amounts of data and cannot make predictions until the harvesting season begins. Using weather and planting data from alfalfa variety trials in Kentucky and Georgia, our previous work compared feature selection techniques to find the best technique and best feature set. In this work, we trained a variety of machine learning models, using cross validation for hyperparameter optimization, to predict biomass yields, and we showed better accuracy than similar work that employed more complex techniques. Our best individual model was a random forest with a mean absolute error of 0.081 tons/acre and R{$^2$} of 0.941. Next, we expanded this dataset to include Wisconsin and Mississippi, and we repeated our experiments, obtaining a higher best R{$^2$} of 0.982 with a regression tree. We then isolated our testing datasets by state to explore this problem's eligibility for domain adaptation (DA), as we trained on multiple source states and tested on one target state. This Trivial DA (TDA) approach leaves plenty of room for improvement through exploring more complex DA techniques in forthcoming work.
EXPANSE: A Deep Continual / Progressive Learning System for Deep Transfer Learning
May 24, 2022
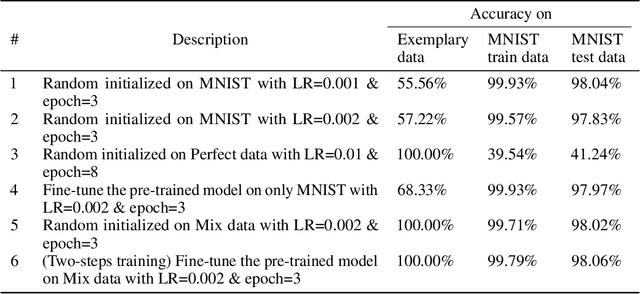
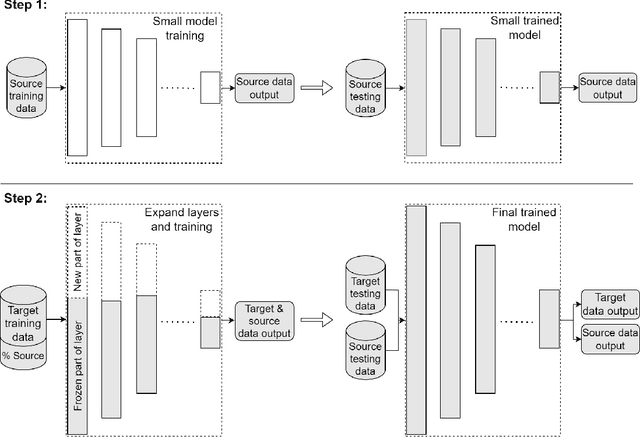
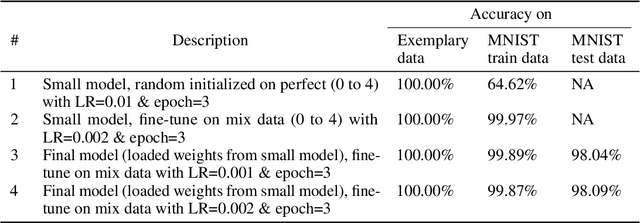
Deep transfer learning techniques try to tackle the limitations of deep learning, the dependency on extensive training data and the training costs, by reusing obtained knowledge. However, the current DTL techniques suffer from either catastrophic forgetting dilemma (losing the previously obtained knowledge) or overly biased pre-trained models (harder to adapt to target data) in finetuning pre-trained models or freezing a part of the pre-trained model, respectively. Progressive learning, a sub-category of DTL, reduces the effect of the overly biased model in the case of freezing earlier layers by adding a new layer to the end of a frozen pre-trained model. Even though it has been successful in many cases, it cannot yet handle distant source and target data. We propose a new continual/progressive learning approach for deep transfer learning to tackle these limitations. To avoid both catastrophic forgetting and overly biased-model problems, we expand the pre-trained model by expanding pre-trained layers (adding new nodes to each layer) in the model instead of only adding new layers. Hence the method is named EXPANSE. Our experimental results confirm that we can tackle distant source and target data using this technique. At the same time, the final model is still valid on the source data, achieving a promising deep continual learning approach. Moreover, we offer a new way of training deep learning models inspired by the human education system. We termed this two-step training: learning basics first, then adding complexities and uncertainties. The evaluation implies that the two-step training extracts more meaningful features and a finer basin on the error surface since it can achieve better accuracy in comparison to regular training. EXPANSE (model expansion and two-step training) is a systematic continual learning approach applicable to different problems and DL models.
The application of Evolutionary and Nature Inspired Algorithms in Data Science and Data Analytics
Feb 06, 2022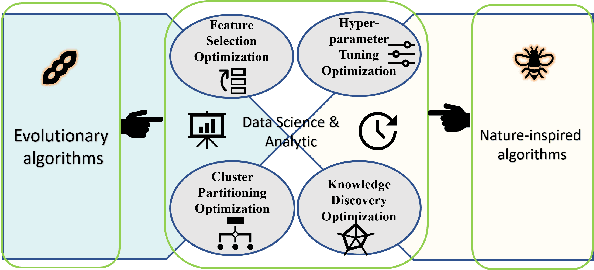

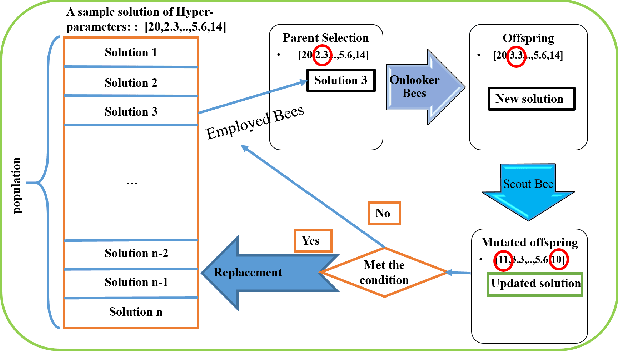
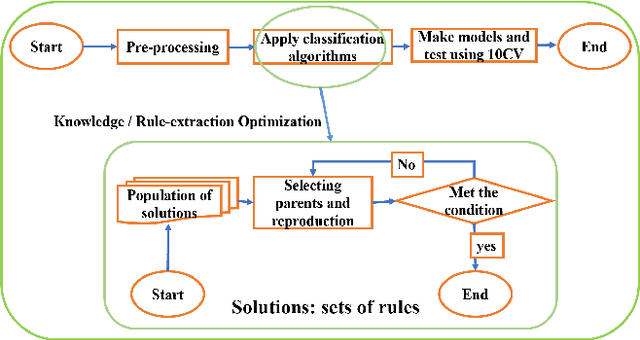
In the past 30 years, scientists have searched nature, including animals and insects, and biology in order to discover, understand, and model solutions for solving large-scale science challenges. The study of bionics reveals that how the biological structures, functions found in nature have improved our modern technologies. In this study, we present our discovery of evolutionary and nature-inspired algorithms applications in Data Science and Data Analytics in three main topics of pre-processing, supervised algorithms, and unsupervised algorithms. Among all applications, in this study, we aim to investigate four optimization algorithms that have been performed using the evolutionary and nature-inspired algorithms within data science and analytics. Feature selection optimization in pre-processing section, Hyper-parameter tuning optimization, and knowledge discovery optimization in supervised algorithms, and clustering optimization in the unsupervised algorithms.
An Integrated Approach for Video Captioning and Applications
Jan 23, 2022



Physical computing infrastructure, data gathering, and algorithms have recently had significant advances to extract information from images and videos. The growth has been especially outstanding in image captioning and video captioning. However, most of the advancements in video captioning still take place in short videos. In this research, we caption longer videos only by using the keyframes, which are a small subset of the total video frames. Instead of processing thousands of frames, only a few frames are processed depending on the number of keyframes. There is a trade-off between the computation of many frames and the speed of the captioning process. The approach in this research is to allow the user to specify the trade-off between execution time and accuracy. In addition, we argue that linking images, videos, and natural language offers many practical benefits and immediate practical applications. From the modeling perspective, instead of designing and staging explicit algorithms to process videos and generate captions in complex processing pipelines, our contribution lies in designing hybrid deep learning architectures to apply in long videos by captioning video keyframes. We consider the technology and the methodology that we have developed as steps toward the applications discussed in this research.
Generative Adversarial Network Applications in Creating a Meta-Universe
Jan 23, 2022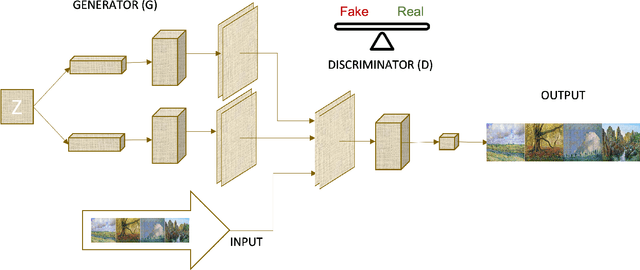


Generative Adversarial Networks (GANs) are machine learning methods that are used in many important and novel applications. For example, in imaging science, GANs are effectively utilized in generating image datasets, photographs of human faces, image and video captioning, image-to-image translation, text-to-image translation, video prediction, and 3D object generation to name a few. In this paper, we discuss how GANs can be used to create an artificial world. More specifically, we discuss how GANs help to describe an image utilizing image/video captioning methods and how to translate the image to a new image using image-to-image translation frameworks in a theme we desire. We articulate how GANs impact creating a customized world.
A Review of Deep Transfer Learning and Recent Advancements
Jan 19, 2022A successful deep learning model is dependent on extensive training data and processing power and time (known as training costs). There exist many tasks without enough number of labeled data to train a deep learning model. Further, the demand is rising for running deep learning models on edge devices with limited processing capacity and training time. Deep transfer learning (DTL) methods are the answer to tackle such limitations, e.g., fine-tuning a pre-trained model on a massive semi-related dataset proved to be a simple and effective method for many problems. DTLs handle limited target data concerns as well as drastically reduce the training costs. In this paper, the definition and taxonomy of deep transfer learning is reviewed. Then we focus on the sub-category of network-based DTLs since it is the most common types of DTLs that have been applied to various applications in the last decade.
DRDrV3: Complete Lesion Detection in Fundus Images Using Mask R-CNN, Transfer Learning, and LSTM
Aug 18, 2021

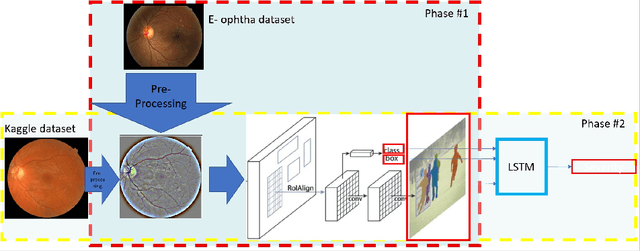

Medical Imaging is one of the growing fields in the world of computer vision. In this study, we aim to address the Diabetic Retinopathy (DR) problem as one of the open challenges in medical imaging. In this research, we propose a new lesion detection architecture, comprising of two sub-modules, which is an optimal solution to detect and find not only the type of lesions caused by DR, their corresponding bounding boxes, and their masks; but also the severity level of the overall case. Aside from traditional accuracy, we also use two popular evaluation criteria to evaluate the outputs of our models, which are intersection over union (IOU) and mean average precision (mAP). We hypothesize that this new solution enables specialists to detect lesions with high confidence and estimate the severity of the damage with high accuracy.
Sarcasm Detection: A Comparative Study
Jul 07, 2021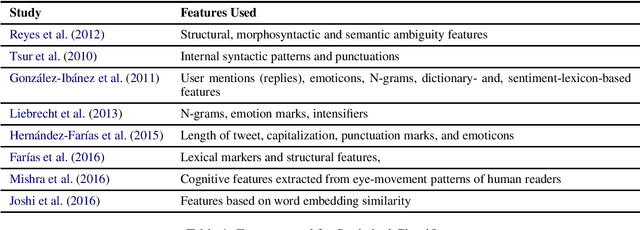
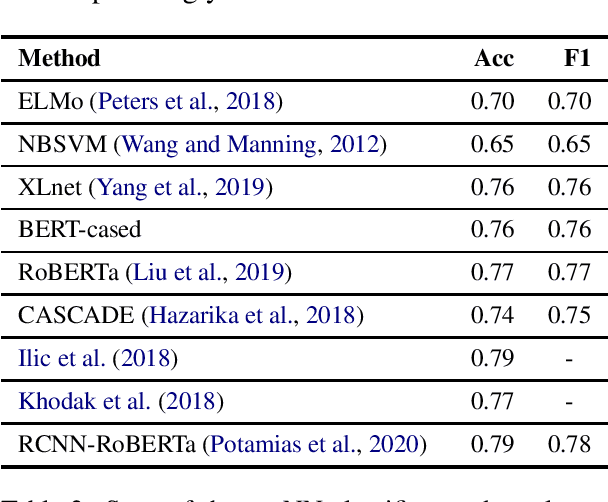
Sarcasm detection is the task of identifying irony containing utterances in sentiment-bearing text. However, the figurative and creative nature of sarcasm poses a great challenge for affective computing systems performing sentiment analysis. This article compiles and reviews the salient work in the literature of automatic sarcasm detection. Thus far, three main paradigm shifts have occurred in the way researchers have approached this task: 1) semi-supervised pattern extraction to identify implicit sentiment, 2) use of hashtag-based supervision, and 3) incorporation of context beyond target text. In this article, we provide a comprehensive review of the datasets, approaches, trends, and issues in sarcasm and irony detection.