 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Deep Learning and Foundation Models for Time Series Forecasting
Jan 25, 2024Deep Learning has been successfully applied to many application domains, yet its advantages have been slow to emerge for time series forecasting. For example, in the well-known Makridakis (M) Competitions, hybrids of traditional statistical or machine learning techniques have only recently become the top performers. With the recent architectural advances in deep learning being applied to time series forecasting (e.g., encoder-decoders with attention, transformers, and graph neural networks), deep learning has begun to show significant advantages. Still, in the area of pandemic prediction, there remain challenges for deep learning models: the time series is not long enough for effective training, unawareness of accumulated scientific knowledge, and interpretability of the model. To this end, the development of foundation models (large deep learning models with extensive pre-training) allows models to understand patterns and acquire knowledge that can be applied to new related problems before extensive training data becomes available. Furthermore, there is a vast amount of knowledge available that deep learning models can tap into, including Knowledge Graphs and Large Language Models fine-tuned with scientific domain knowledge. There is ongoing research examining how to utilize or inject such knowledge into deep learning models. In this survey, several state-of-the-art modeling techniques are reviewed, and suggestions for further work are provided.
EXPANSE: A Deep Continual / Progressive Learning System for Deep Transfer Learning
May 24, 2022
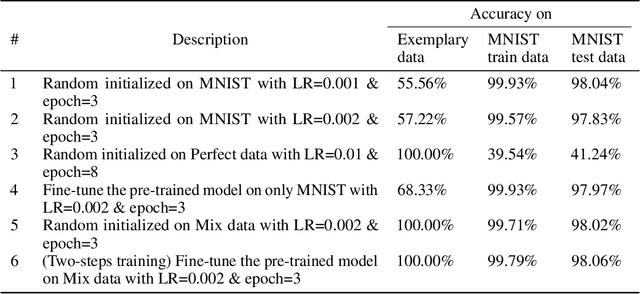
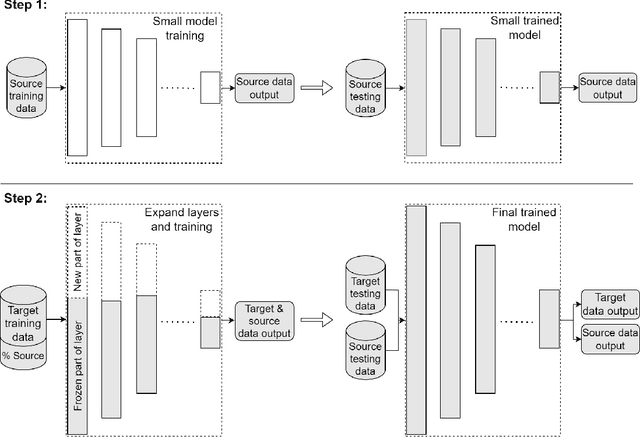
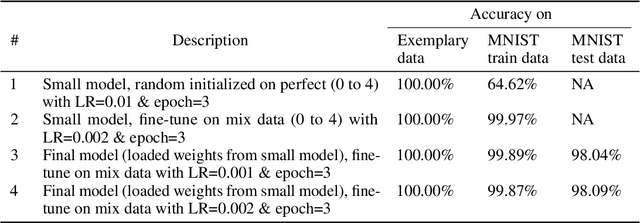
Deep transfer learning techniques try to tackle the limitations of deep learning, the dependency on extensive training data and the training costs, by reusing obtained knowledge. However, the current DTL techniques suffer from either catastrophic forgetting dilemma (losing the previously obtained knowledge) or overly biased pre-trained models (harder to adapt to target data) in finetuning pre-trained models or freezing a part of the pre-trained model, respectively. Progressive learning, a sub-category of DTL, reduces the effect of the overly biased model in the case of freezing earlier layers by adding a new layer to the end of a frozen pre-trained model. Even though it has been successful in many cases, it cannot yet handle distant source and target data. We propose a new continual/progressive learning approach for deep transfer learning to tackle these limitations. To avoid both catastrophic forgetting and overly biased-model problems, we expand the pre-trained model by expanding pre-trained layers (adding new nodes to each layer) in the model instead of only adding new layers. Hence the method is named EXPANSE. Our experimental results confirm that we can tackle distant source and target data using this technique. At the same time, the final model is still valid on the source data, achieving a promising deep continual learning approach. Moreover, we offer a new way of training deep learning models inspired by the human education system. We termed this two-step training: learning basics first, then adding complexities and uncertainties. The evaluation implies that the two-step training extracts more meaningful features and a finer basin on the error surface since it can achieve better accuracy in comparison to regular training. EXPANSE (model expansion and two-step training) is a systematic continual learning approach applicable to different problems and DL models.
Improving Neural Networks for Time Series Forecasting using Data Augmentation and AutoML
Mar 05, 2021
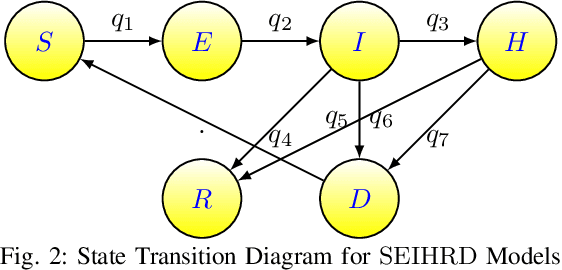
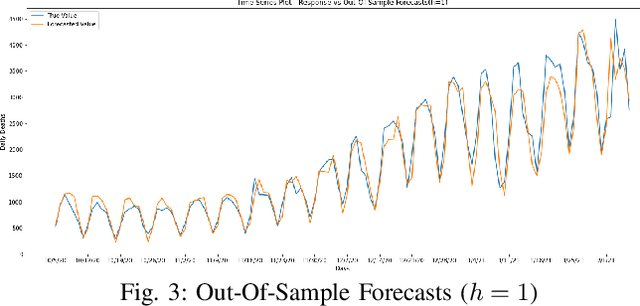
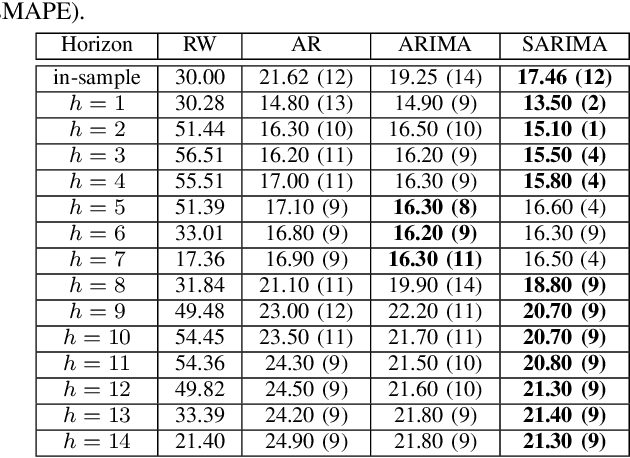
Statistical methods such as the Box-Jenkins method for time-series forecasting have been prominent since their development in 1970. Many researchers rely on such models as they can be efficiently estimated and also provide interpretability. However, advances in machine learning research indicate that neural networks can be powerful data modeling techniques, as they can give higher accuracy for a plethora of learning problems and datasets. In the past, they have been tried on time-series forecasting as well, but their overall results have not been significantly better than the statistical models especially for intermediate length times series data. Their modeling capacities are limited in cases where enough data may not be available to estimate the large number of parameters that these non-linear models require. This paper presents an easy to implement data augmentation method to significantly improve the performance of such networks. Our method, Augmented-Neural-Network, which involves using forecasts from statistical models, can help unlock the power of neural networks on intermediate length time-series and produces competitive results. It shows that data augmentation, when paired with Automated Machine Learning techniques such as Neural Architecture Search, can help to find the best neural architecture for a given time-series. Using the combination of these, demonstrates significant enhancement for two configurations of our technique for a COVID-19 dataset, improving forecasting accuracy by 19.90% and 11.43%, respectively, over the neural networks that do not use augmented data.
Video Contents Understanding using Deep Neural Networks
Apr 29, 2020
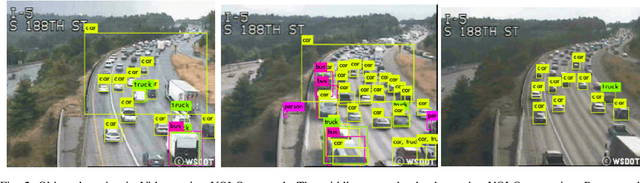

We propose a novel application of Transfer Learning to classify video-frame sequences over multiple classes. This is a pre-weighted model that does not require to train a fresh CNN. This representation is achieved with the advent of "deep neural network" (DNN), which is being studied these days by many researchers. We utilize the classical approaches for video classification task using object detection techniques for comparison, such as "Google Video Intelligence API" and this study will run experiments as to how those architectures would perform in foggy or rainy weather conditions. Experimental evaluation on video collections shows that the new proposed classifier achieves superior performance over existing solutions.
Stereotype-Free Classification of Fictitious Faces
Apr 29, 2020

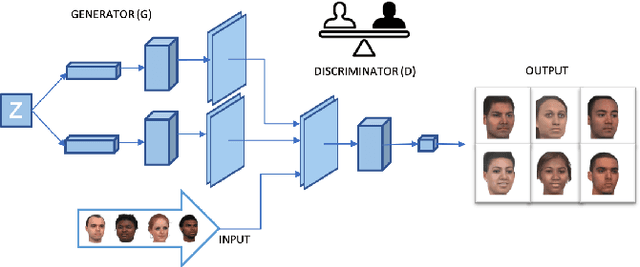
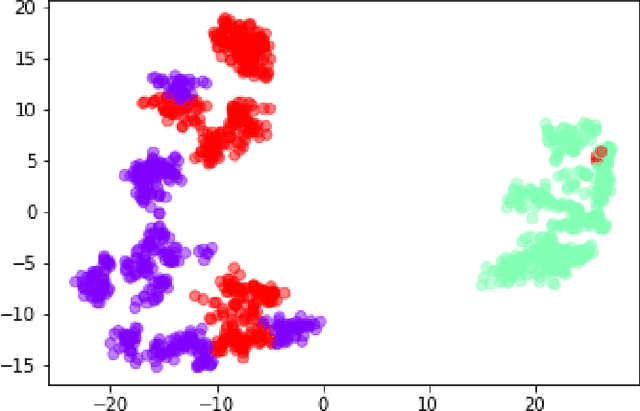
Equal Opportunity and Fairness are receiving increasing attention in artificial intelligence. Stereotyping is another source of discrimination, which yet has been unstudied in literature. GAN-made faces would be exposed to such discrimination, if they are classified by human perception. It is possible to eliminate the human impact on fictitious faces classification task by the use of statistical approaches. We present a novel approach through penalized regression to label stereotype-free GAN-generated synthetic unlabeled images. The proposed approach aids labeling new data (fictitious output images) by minimizing a penalized version of the least squares cost function between realistic pictures and target pictures.
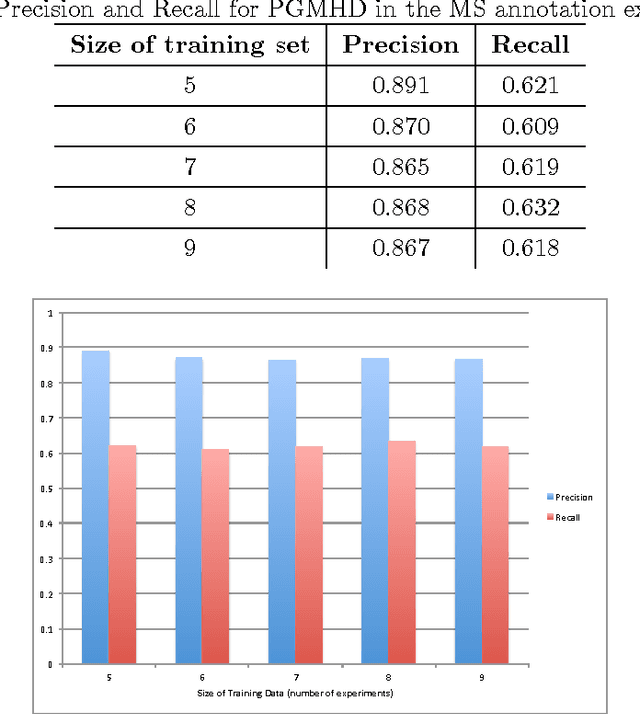
GELATO and SAGE: An Integrated Framework for MS Annotation
Jan 08, 2016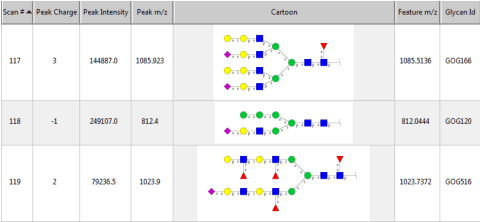
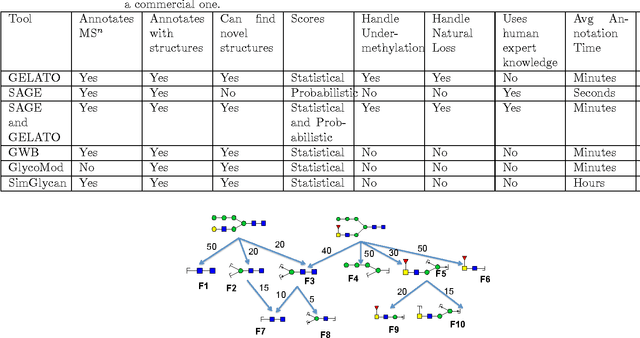
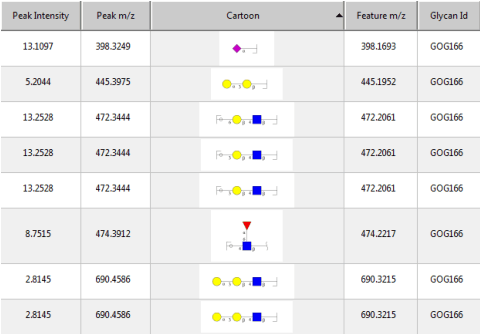
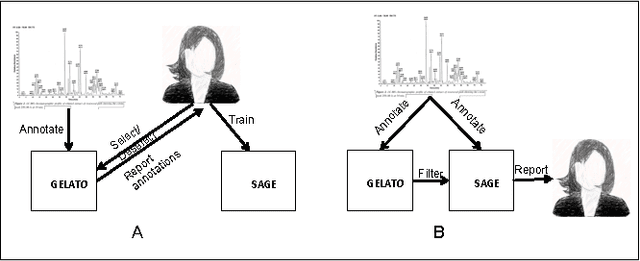
Several algorithms and tools have been developed to (semi) automate the process of glycan identification by interpreting Mass Spectrometric data. However, each has limitations when annotating MSn data with thousands of MS spectra using uncurated public databases. Moreover, the existing tools are not designed to manage MSn data where n > 2. We propose a novel software package to automate the annotation of tandem MS data. This software consists of two major components. The first, is a free, semi-automated MSn data interpreter called the Glycomic Elucidation and Annotation Tool (GELATO). This tool extends and automates the functionality of existing open source projects, namely, GlycoWorkbench (GWB) and GlycomeDB. The second is a machine learning model called Smart Anotation Enhancement Graph (SAGE), which learns the behavior of glycoanalysts to select annotations generated by GELATO that emulate human interpretation of the spectra.
Mining Massive Hierarchical Data Using a Scalable Probabilistic Graphical Model
Dec 28, 2015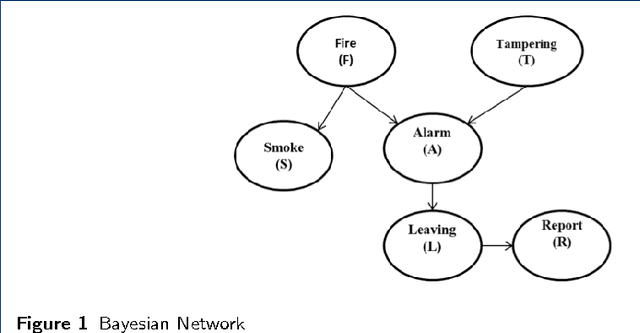

Probabilistic Graphical Models (PGM) are very useful in the fields of machine learning and data mining. The crucial limitation of those models,however, is the scalability. The Bayesian Network, which is one of the most common PGMs used in machine learning and data mining, demonstrates this limitation when the training data consists of random variables, each of them has a large set of possible values. In the big data era, one would expect new extensions to the existing PGMs to handle the massive amount of data produced these days by computers, sensors and other electronic devices. With hierarchical data - data that is arranged in a treelike structure with several levels - one would expect to see hundreds of thousands or millions of values distributed over even just a small number of levels. When modeling this kind of hierarchical data across large data sets, Bayesian Networks become infeasible for representing the probability distributions. In this paper we introduce an extension to Bayesian Networks to handle massive sets of hierarchical data in a reasonable amount of time and space. The proposed model achieves perfect precision of 1.0 and high recall of 0.93 when it is used as multi-label classifier for the annotation of mass spectrometry data. On another data set of 1.5 billion search logs provided by CareerBuilder.com the model was able to predict latent semantic relationships between search keywords with accuracy up to 0.80.
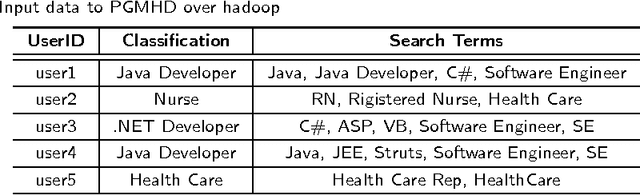
PGMHD: A Scalable Probabilistic Graphical Model for Massive Hierarchical Data Problems
Aug 19, 2014
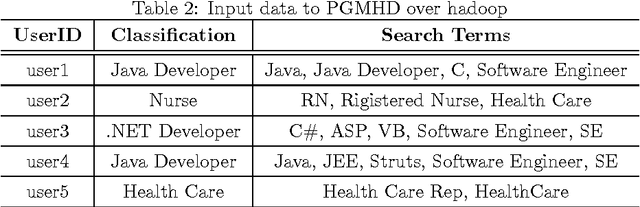
In the big data era, scalability has become a crucial requirement for any useful computational model. Probabilistic graphical models are very useful for mining and discovering data insights, but they are not scalable enough to be suitable for big data problems. Bayesian Networks particularly demonstrate this limitation when their data is represented using few random variables while each random variable has a massive set of values. With hierarchical data - data that is arranged in a treelike structure with several levels - one would expect to see hundreds of thousands or millions of values distributed over even just a small number of levels. When modeling this kind of hierarchical data across large data sets, Bayesian networks become infeasible for representing the probability distributions for the following reasons: i) Each level represents a single random variable with hundreds of thousands of values, ii) The number of levels is usually small, so there are also few random variables, and iii) The structure of the network is predefined since the dependency is modeled top-down from each parent to each of its child nodes, so the network would contain a single linear path for the random variables from each parent to each child node. In this paper we present a scalable probabilistic graphical model to overcome these limitations for massive hierarchical data. We believe the proposed model will lead to an easily-scalable, more readable, and expressive implementation for problems that require probabilistic-based solutions for massive amounts of hierarchical data. We successfully applied this model to solve two different challenging probabilistic-based problems on massive hierarchical data sets for different domains, namely, bioinformatics and latent semantic discovery over search logs.