 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning in Healthcare: An In-Depth Analysis
Feb 12, 2023Deep learning (DL) along with never-ending advancements in computational processing and cloud technologies have bestowed us powerful analyzing tools and techniques in the past decade and enabled us to use and apply them in various fields of study. Health informatics is not an exception, and conversely, is the discipline that generates the most amount of data in today's era and can benefit from DL the most. Extracting features and finding complex patterns from a huge amount of raw data and transforming them into knowledge is a challenging task. Besides, various DL architectures have been proposed by researchers throughout the years to tackle different problems. In this paper, we provide a review of DL models and their broad application in bioinformatics and healthcare categorized by their architecture. In addition, we also go over some of the key challenges that still exist and can show up while conducting DL research.
Word Embedding Neural Networks to Advance Knee Osteoarthritis Research
Dec 22, 2022Osteoarthritis (OA) is the most prevalent chronic joint disease worldwide, where knee OA takes more than 80% of commonly affected joints. Knee OA is not a curable disease yet, and it affects large columns of patients, making it costly to patients and healthcare systems. Etiology, diagnosis, and treatment of knee OA might be argued by variability in its clinical and physical manifestations. Although knee OA carries a list of well-known terminology aiming to standardize the nomenclature of the diagnosis, prognosis, treatment, and clinical outcomes of the chronic joint disease, in practice there is a wide range of terminology associated with knee OA across different data sources, including but not limited to biomedical literature, clinical notes, healthcare literacy, and health-related social media. Among these data sources, the scientific articles published in the biomedical literature usually make a principled pipeline to study disease. Rapid yet, accurate text mining on large-scale scientific literature may discover novel knowledge and terminology to better understand knee OA and to improve the quality of knee OA diagnosis, prevention, and treatment. The present works aim to utilize artificial neural network strategies to automatically extract vocabularies associated with knee OA diseases. Our finding indicates the feasibility of developing word embedding neural networks for autonomous keyword extraction and abstraction of knee OA.
3D-model ShapeNet Core Classification using Meta-Semantic Learning
May 28, 2022
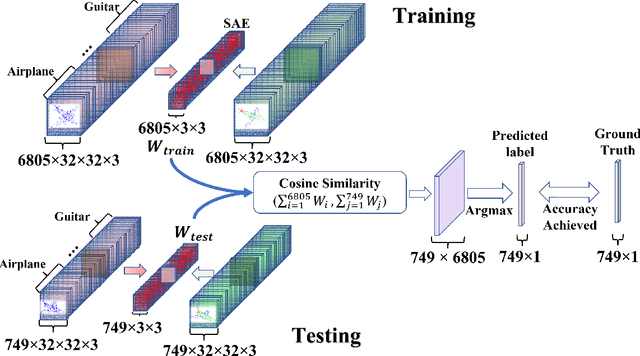

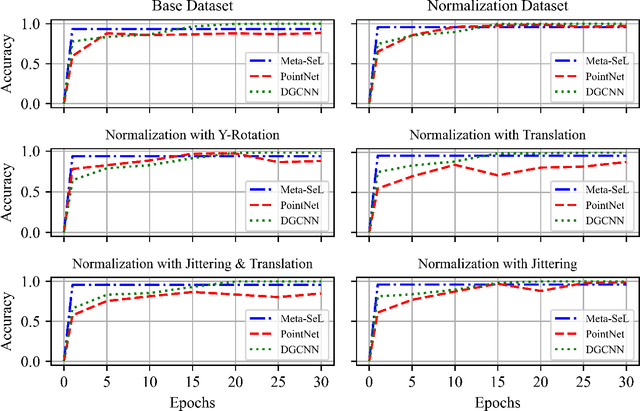
Understanding 3D point cloud models for learning purposes has become an imperative challenge for real-world identification such as autonomous driving systems. A wide variety of solutions using deep learning have been proposed for point cloud segmentation, object detection, and classification. These methods, however, often require a considerable number of model parameters and are computationally expensive. We study a semantic dimension of given 3D data points and propose an efficient method called Meta-Semantic Learning (Meta-SeL). Meta-SeL is an integrated framework that leverages two input 3D local points (input 3D models and part-segmentation labels), providing a time and cost-efficient, and precise projection model for a number of 3D recognition tasks. The results indicate that Meta-SeL yields competitive performance in comparison with other complex state-of-the-art work. Moreover, being random shuffle invariant, Meta-SeL is resilient to translation as well as jittering noise.
EXPANSE: A Deep Continual / Progressive Learning System for Deep Transfer Learning
May 24, 2022
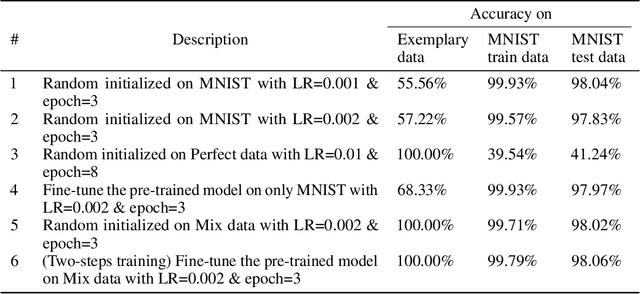
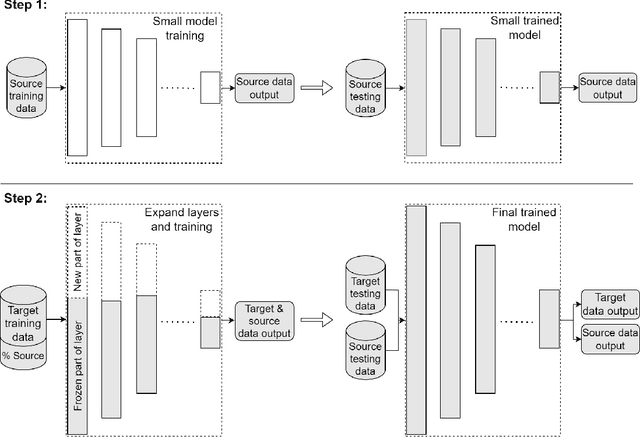
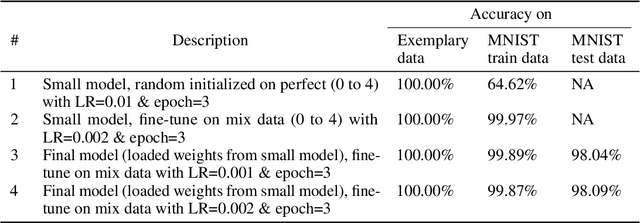
Deep transfer learning techniques try to tackle the limitations of deep learning, the dependency on extensive training data and the training costs, by reusing obtained knowledge. However, the current DTL techniques suffer from either catastrophic forgetting dilemma (losing the previously obtained knowledge) or overly biased pre-trained models (harder to adapt to target data) in finetuning pre-trained models or freezing a part of the pre-trained model, respectively. Progressive learning, a sub-category of DTL, reduces the effect of the overly biased model in the case of freezing earlier layers by adding a new layer to the end of a frozen pre-trained model. Even though it has been successful in many cases, it cannot yet handle distant source and target data. We propose a new continual/progressive learning approach for deep transfer learning to tackle these limitations. To avoid both catastrophic forgetting and overly biased-model problems, we expand the pre-trained model by expanding pre-trained layers (adding new nodes to each layer) in the model instead of only adding new layers. Hence the method is named EXPANSE. Our experimental results confirm that we can tackle distant source and target data using this technique. At the same time, the final model is still valid on the source data, achieving a promising deep continual learning approach. Moreover, we offer a new way of training deep learning models inspired by the human education system. We termed this two-step training: learning basics first, then adding complexities and uncertainties. The evaluation implies that the two-step training extracts more meaningful features and a finer basin on the error surface since it can achieve better accuracy in comparison to regular training. EXPANSE (model expansion and two-step training) is a systematic continual learning approach applicable to different problems and DL models.
Applications of Machine Learning in Healthcare and Internet of Things : A Comprehensive Review
Feb 06, 2022


In recent years, smart healthcare IoT devices have become ubiquitous, but they work in isolated networks due to their policy. Having these devices connected in a network enables us to perform medical distributed data analysis. However, the presence of diverse IoT devices in terms of technology, structure, and network policy, makes it a challenging issue while applying traditional centralized learning algorithms on decentralized data collected from the IoT devices. In this study, we present an extensive review of the state-of-the-art machine learning applications particularly in healthcare, challenging issues in IoT, and corresponding promising solutions. Finally, we highlight some open-ended issues of IoT in healthcare that leaves further research studies and investigation for scientists.
The application of Evolutionary and Nature Inspired Algorithms in Data Science and Data Analytics
Feb 06, 2022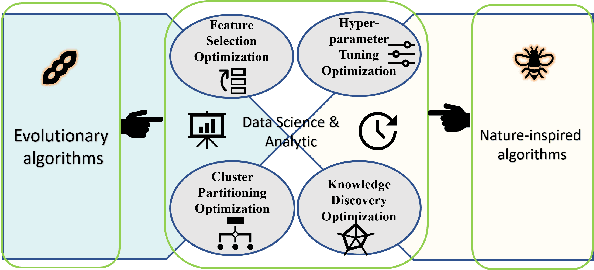

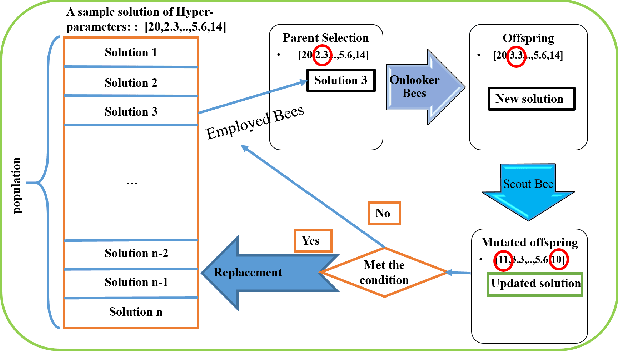
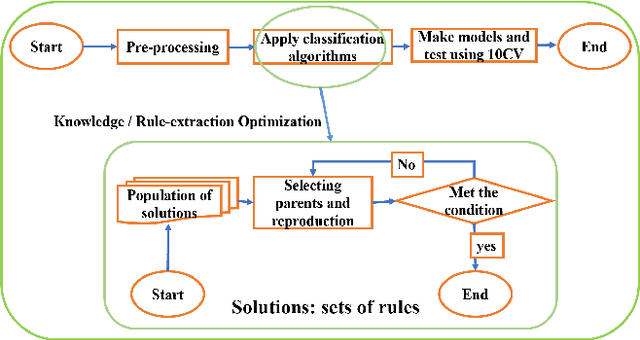
In the past 30 years, scientists have searched nature, including animals and insects, and biology in order to discover, understand, and model solutions for solving large-scale science challenges. The study of bionics reveals that how the biological structures, functions found in nature have improved our modern technologies. In this study, we present our discovery of evolutionary and nature-inspired algorithms applications in Data Science and Data Analytics in three main topics of pre-processing, supervised algorithms, and unsupervised algorithms. Among all applications, in this study, we aim to investigate four optimization algorithms that have been performed using the evolutionary and nature-inspired algorithms within data science and analytics. Feature selection optimization in pre-processing section, Hyper-parameter tuning optimization, and knowledge discovery optimization in supervised algorithms, and clustering optimization in the unsupervised algorithms.
An Integrated Approach for Video Captioning and Applications
Jan 23, 2022



Physical computing infrastructure, data gathering, and algorithms have recently had significant advances to extract information from images and videos. The growth has been especially outstanding in image captioning and video captioning. However, most of the advancements in video captioning still take place in short videos. In this research, we caption longer videos only by using the keyframes, which are a small subset of the total video frames. Instead of processing thousands of frames, only a few frames are processed depending on the number of keyframes. There is a trade-off between the computation of many frames and the speed of the captioning process. The approach in this research is to allow the user to specify the trade-off between execution time and accuracy. In addition, we argue that linking images, videos, and natural language offers many practical benefits and immediate practical applications. From the modeling perspective, instead of designing and staging explicit algorithms to process videos and generate captions in complex processing pipelines, our contribution lies in designing hybrid deep learning architectures to apply in long videos by captioning video keyframes. We consider the technology and the methodology that we have developed as steps toward the applications discussed in this research.
Generative Adversarial Network Applications in Creating a Meta-Universe
Jan 23, 2022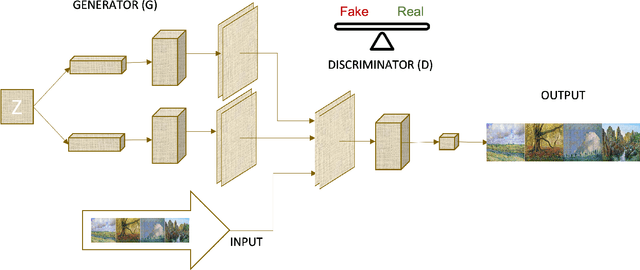


Generative Adversarial Networks (GANs) are machine learning methods that are used in many important and novel applications. For example, in imaging science, GANs are effectively utilized in generating image datasets, photographs of human faces, image and video captioning, image-to-image translation, text-to-image translation, video prediction, and 3D object generation to name a few. In this paper, we discuss how GANs can be used to create an artificial world. More specifically, we discuss how GANs help to describe an image utilizing image/video captioning methods and how to translate the image to a new image using image-to-image translation frameworks in a theme we desire. We articulate how GANs impact creating a customized world.
A Review of Deep Transfer Learning and Recent Advancements
Jan 19, 2022A successful deep learning model is dependent on extensive training data and processing power and time (known as training costs). There exist many tasks without enough number of labeled data to train a deep learning model. Further, the demand is rising for running deep learning models on edge devices with limited processing capacity and training time. Deep transfer learning (DTL) methods are the answer to tackle such limitations, e.g., fine-tuning a pre-trained model on a massive semi-related dataset proved to be a simple and effective method for many problems. DTLs handle limited target data concerns as well as drastically reduce the training costs. In this paper, the definition and taxonomy of deep transfer learning is reviewed. Then we focus on the sub-category of network-based DTLs since it is the most common types of DTLs that have been applied to various applications in the last decade.
Data Analytics for Smart cities: Challenges and Promises
Sep 12, 2021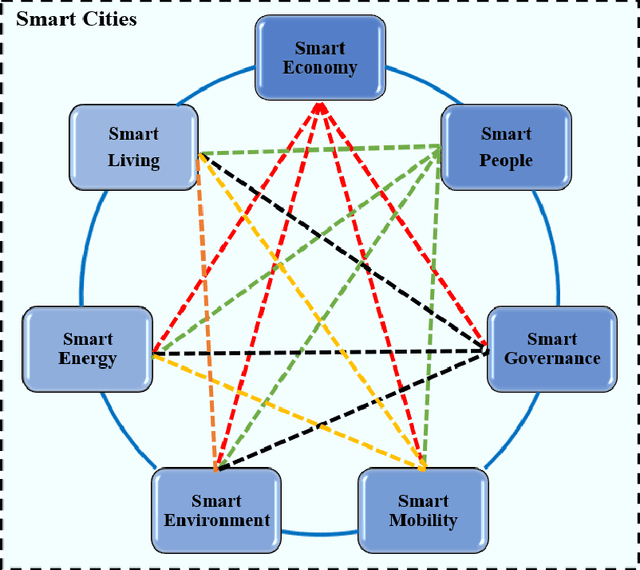
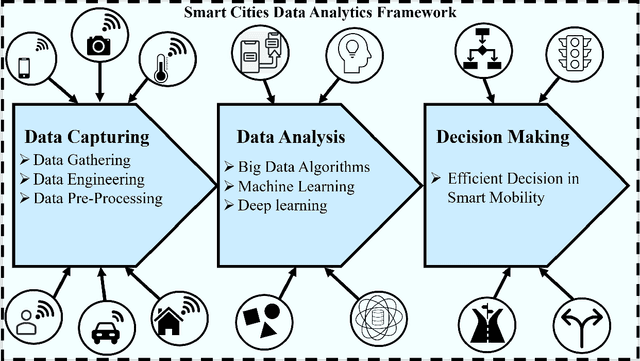
The explosion of advancements in artificial intelligence, sensor technologies, and wireless communication activates ubiquitous sensing through distributed sensors. These sensors are various domains of networks that lead us to smart systems in healthcare, transportation, environment, and other relevant branches/networks. Having collaborative interaction among the smart systems connects end-user devices to each other which enables achieving a new integrated entity called Smart Cities. The goal of this study is to provide a comprehensive survey of data analytics in smart cities. In this paper, we aim to focus on one of the smart cities important branches, namely Smart Mobility, and its positive ample impact on the smart cities decision-making process. Intelligent decision-making systems in smart mobility offer many advantages such as saving energy, relaying city traffic, and more importantly, reducing air pollution by offering real-time useful information and imperative knowledge. Making a decision in smart cities in time is challenging due to various and high dimensional factors and parameters, which are not frequently collected. In this paper, we first address current challenges in smart cities and provide an overview of potential solutions to these challenges. Then, we offer a framework of these solutions, called universal smart cities decision making, with three main sections of data capturing, data analysis, and decision making to optimize the smart mobility within smart cities. With this framework, we elaborate on fundamental concepts of big data, machine learning, and deep leaning algorithms that have been applied to smart cities and discuss the role of these algorithms in decision making for smart mobility in smart cities.