 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-model ShapeNet Core Classification using Meta-Semantic Learning
Paper and Code
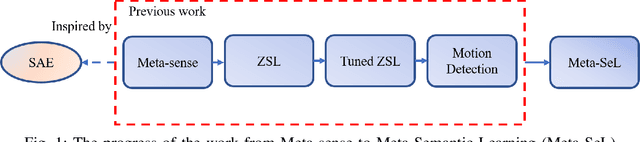
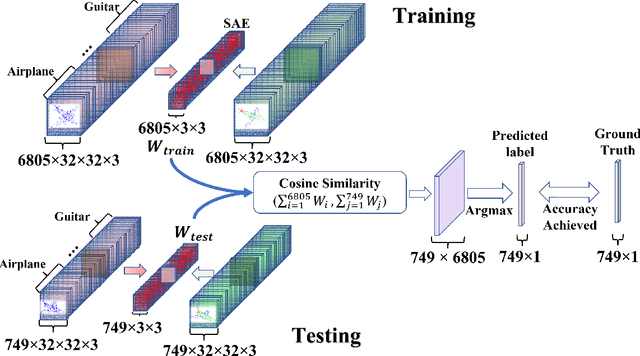

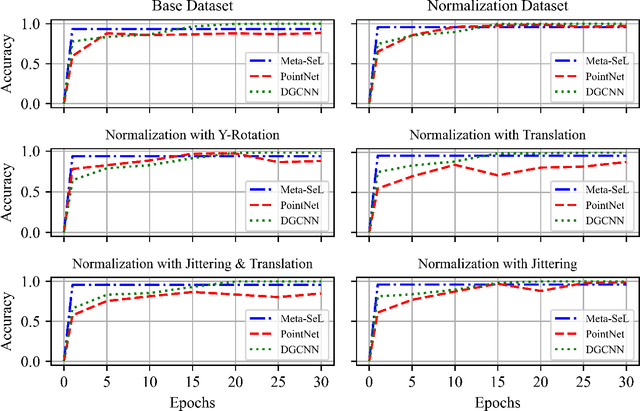
Understanding 3D point cloud models for learning purposes has become an imperative challenge for real-world identification such as autonomous driving systems. A wide variety of solutions using deep learning have been proposed for point cloud segmentation, object detection, and classification. These methods, however, often require a considerable number of model parameters and are computationally expensive. We study a semantic dimension of given 3D data points and propose an efficient method called Meta-Semantic Learning (Meta-SeL). Meta-SeL is an integrated framework that leverages two input 3D local points (input 3D models and part-segmentation labels), providing a time and cost-efficient, and precise projection model for a number of 3D recognition tasks. The results indicate that Meta-SeL yields competitive performance in comparison with other complex state-of-the-art work. Moreover, being random shuffle invariant, Meta-SeL is resilient to translation as well as jittering noise.