 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking Large Vision Language Models in Intelligent Transportation Systems
Nov 17, 2025Large Vision Language Models (LVLMs) demonstrate strong capabilities in multimodal reasoning and many real-world applications, such as visual question answering. However, LVLMs are highly vulnerable to jailbreaking attacks. This paper systematically analyzes the vulnerabilities of LVLMs integrated in Intelligent Transportation Systems (ITS) under carefully crafted jailbreaking attacks. First, we carefully construct a dataset with harmful queries relevant to transportation, following OpenAI's prohibited categories to which the LVLMs should not respond. Second, we introduce a novel jailbreaking attack that exploits the vulnerabilities of LVLMs through image typography manipulation and multi-turn prompting. Third, we propose a multi-layered response filtering defense technique to prevent the model from generating inappropriate responses. We perform extensive experiments with the proposed attack and defense on the state-of-the-art LVLMs (both open-source and closed-source). To evaluate the attack method and defense technique, we use GPT-4's judgment to determine the toxicity score of the generated responses, as well as manual verification. Further, we compare our proposed jailbreaking method with existing jailbreaking techniques and highlight severe security risks involved with jailbreaking attacks with image typography manipulation and multi-turn prompting in the LVLMs integrated in ITS.
Optimal Transport-based Domain Alignment as a Preprocessing Step for Federated Learning
Jun 04, 2025Federated learning (FL) is a subfield of machine learning that avoids sharing local data with a central server, which can enhance privacy and scalability. The inability to consolidate data leads to a unique problem called dataset imbalance, where agents in a network do not have equal representation of the labels one is trying to learn to predict. In FL, fusing locally-trained models with unbalanced datasets may deteriorate the performance of global model aggregation, and reduce the quality of updated local models and the accuracy of the distributed agents' decisions. In this work, we introduce an Optimal Transport-based preprocessing algorithm that aligns the datasets by minimizing the distributional discrepancy of data along the edge devices. We accomplish this by leveraging Wasserstein barycenters when computing channel-wise averages. These barycenters are collected in a trusted central server where they collectively generate a target RGB space. By projecting our dataset towards this target space, we minimize the distributional discrepancy on a global level, which facilitates the learning process due to a minimization of variance across the samples. We demonstrate the capabilities of the proposed approach over the CIFAR-10 dataset, where we show its capability of reaching higher degrees of generalization in fewer communication rounds.
Accurate and Efficient Two-Stage Gun Detection in Video
Mar 08, 2025Object detection in videos plays a crucial role in advancing applications such as public safety and anomaly detection. Existing methods have explored different techniques, including CNN, deep learning, and Transformers, for object detection and video classification. However, detecting tiny objects, e.g., guns, in videos remains challenging due to their small scale and varying appearances in complex scenes. Moreover, existing video analysis models for classification or detection often perform poorly in real-world gun detection scenarios due to limited labeled video datasets for training. Thus, developing efficient methods for effectively capturing tiny object features and designing models capable of accurate gun detection in real-world videos is imperative. To address these challenges, we make three original contributions in this paper. First, we conduct an empirical study of several existing video classification and object detection methods to identify guns in videos. Our extensive analysis shows that these methods may not accurately detect guns in videos. Second, we propose a novel two-stage gun detection method. In stage 1, we train an image-augmented model to effectively classify ``Gun'' videos. To make the detection more precise and efficient, stage 2 employs an object detection model to locate the exact region of the gun within video frames for videos classified as ``Gun'' by stage 1. Third, our experimental results demonstrate that the proposed domain-specific method achieves significant performance improvements and enhances efficiency compared with existing techniques. We also discuss challenges and future research directions in gun detection tasks in computer vision.
pMixFed: Efficient Personalized Federated Learning through Adaptive Layer-Wise Mixup
Jan 19, 2025



Traditional Federated Learning (FL) methods encounter significant challenges when dealing with heterogeneous data and providing personalized solutions for non-IID scenarios. Personalized Federated Learning (PFL) approaches aim to address these issues by balancing generalization and personalization, often through parameter decoupling or partial models that freeze some neural network layers for personalization while aggregating other layers globally. However, existing methods still face challenges of global-local model discrepancy, client drift, and catastrophic forgetting, which degrade model accuracy. To overcome these limitations, we propose pMixFed, a dynamic, layer-wise PFL approach that integrates mixup between shared global and personalized local models. Our method introduces an adaptive strategy for partitioning between personalized and shared layers, a gradual transition of personalization degree to enhance local client adaptation, improved generalization across clients, and a novel aggregation mechanism to mitigate catastrophic forgetting. Extensive experiments demonstrate that pMixFed outperforms state-of-the-art PFL methods, showing faster model training, increased robustness, and improved handling of data heterogeneity under different heterogeneous settings.
Blockchain-Empowered Cyber-Secure Federated Learning for Trustworthy Edge Computing
Dec 30, 2024



Federated Learning (FL) is a privacy-preserving distributed machine learning scheme, where each participant data remains on the participating devices and only the local model generated utilizing the local computational power is transmitted throughout the database. However, the distributed computational nature of FL creates the necessity to develop a mechanism that can remotely trigger any network agents, track their activities, and prevent threats to the overall process posed by malicious participants. Particularly, the FL paradigm may become vulnerable due to an active attack from the network participants, called a poisonous attack. In such an attack, the malicious participant acts as a benign agent capable of affecting the global model quality by uploading an obfuscated poisoned local model update to the server. This paper presents a cross-device FL model that ensures trustworthiness, fairness, and authenticity in the underlying FL training process. We leverage trustworthiness by constructing a reputation-based trust model based on contributions of agents toward model convergence. We ensure fairness by identifying and removing malicious agents from the training process through an outlier detection technique. Further, we establish authenticity by generating a token for each participating device through a distributed sensing mechanism and storing that unique token in a blockchain smart contract. Further, we insert the trust scores of all agents into a blockchain and validate their reputations using various consensus mechanisms that consider the computational task.
Hyper-parameter Optimization for Federated Learning with Step-wise Adaptive Mechanism
Nov 19, 2024Federated Learning (FL) is a decentralized learning approach that protects sensitive information by utilizing local model parameters rather than sharing clients' raw datasets. While this privacy-preserving method is widely employed across various applications, it still requires significant development and optimization. Automated Machine Learning (Auto-ML) has been adapted for reducing the need for manual adjustments. Previous studies have explored the integration of AutoML with different FL algorithms to evaluate their effectiveness in enhancing FL settings. However, Automated FL (Auto-FL) faces additional challenges due to the involvement of a large cohort of clients and global training rounds between clients and the server, rendering the tuning process time-consuming and nearly impossible on resource-constrained edge devices (e.g., IoT devices). This paper investigates the deployment and integration of two lightweight Hyper-Parameter Optimization (HPO) tools, Raytune and Optuna, within the context of FL settings. A step-wise feedback mechanism has also been designed to accelerate the hyper-parameter tuning process and coordinate AutoML toolkits with the FL server. To this end, both local and global feedback mechanisms are integrated to limit the search space and expedite the HPO process. Further, a novel client selection technique is introduced to mitigate the straggler effect in Auto-FL. The selected hyper-parameter tuning tools are evaluated using two benchmark datasets, FEMNIST, and CIFAR10. Further, the paper discusses the essential properties of successful HPO tools, the integration mechanism with the FL pipeline, and the challenges posed by the distributed and heterogeneous nature of FL environments.
QuanCrypt-FL: Quantized Homomorphic Encryption with Pruning for Secure Federated Learning
Nov 08, 2024Federated Learning has emerged as a leading approach for decentralized machine learning, enabling multiple clients to collaboratively train a shared model without exchanging private data. While FL enhances data privacy, it remains vulnerable to inference attacks, such as gradient inversion and membership inference, during both training and inference phases. Homomorphic Encryption provides a promising solution by encrypting model updates to protect against such attacks, but it introduces substantial communication overhead, slowing down training and increasing computational costs. To address these challenges, we propose QuanCrypt-FL, a novel algorithm that combines low-bit quantization and pruning techniques to enhance protection against attacks while significantly reducing computational costs during training. Further, we propose and implement mean-based clipping to mitigate quantization overflow or errors. By integrating these methods, QuanCrypt-FL creates a communication-efficient FL framework that ensures privacy protection with minimal impact on model accuracy, thereby improving both computational efficiency and attack resilience. We validate our approach on MNIST, CIFAR-10, and CIFAR-100 datasets, demonstrating superior performance compared to state-of-the-art methods. QuanCrypt-FL consistently outperforms existing method and matches Vanilla-FL in terms of accuracy across varying client. Further, QuanCrypt-FL achieves up to 9x faster encryption, 16x faster decryption, and 1.5x faster inference compared to BatchCrypt, with training time reduced by up to 3x.
In-depth Analysis of Privacy Threats in Federated Learning for Medical Data
Sep 27, 2024Federated learning is emerging as a promising machine learning technique in the medical field for analyzing medical images, as it is considered an effective method to safeguard sensitive patient data and comply with privacy regulations. However, recent studies have revealed that the default settings of federated learning may inadvertently expose private training data to privacy attacks. Thus, the intensity of such privacy risks and potential mitigation strategies in the medical domain remain unclear. In this paper, we make three original contributions to privacy risk analysis and mitigation in federated learning for medical data. First, we propose a holistic framework, MedPFL, for analyzing privacy risks in processing medical data in the federated learning environment and developing effective mitigation strategies for protecting privacy. Second, through our empirical analysis, we demonstrate the severe privacy risks in federated learning to process medical images, where adversaries can accurately reconstruct private medical images by performing privacy attacks. Third, we illustrate that the prevalent defense mechanism of adding random noises may not always be effective in protecting medical images against privacy attacks in federated learning, which poses unique and pressing challenges related to protecting the privacy of medical data. Furthermore, the paper discusses several unique research questions related to the privacy protection of medical data in the federated learning environment. We conduct extensive experiments on several benchmark medical image datasets to analyze and mitigate the privacy risks associated with federated learning for medical data.
Security and Privacy Challenges of Large Language Models: A Survey
Jan 30, 2024
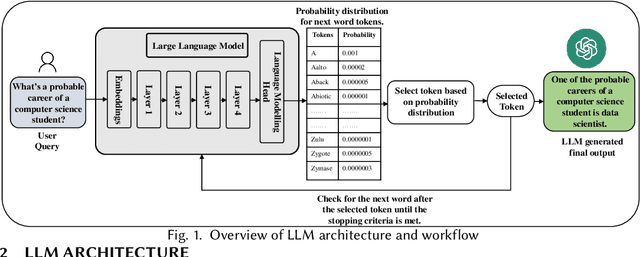


Large Language Models (LLMs) have demonstrated extraordinary capabilities and contributed to multiple fields, such as generating and summarizing text, language translation, and question-answering. Nowadays, LLM is becoming a very popular tool in computerized language processing tasks, with the capability to analyze complicated linguistic patterns and provide relevant and appropriate responses depending on the context. While offering significant advantages, these models are also vulnerable to security and privacy attacks, such as jailbreaking attacks, data poisoning attacks, and Personally Identifiable Information (PII) leakage attacks. This survey provides a thorough review of the security and privacy challenges of LLMs for both training data and users, along with the application-based risks in various domains, such as transportation, education, and healthcare. We assess the extent of LLM vulnerabilities, investigate emerging security and privacy attacks for LLMs, and review the potential defense mechanisms. Additionally, the survey outlines existing research gaps in this domain and highlights future research directions.
Privacy Risks Analysis and Mitigation in Federated Learning for Medical Images
Nov 11, 2023



Federated learning (FL) is gaining increasing popularity in the medical domain for analyzing medical images, which is considered an effective technique to safeguard sensitive patient data and comply with privacy regulations. However, several recent studies have revealed that the default settings of FL may leak private training data under privacy attacks. Thus, it is still unclear whether and to what extent such privacy risks of FL exist in the medical domain, and if so, ``how to mitigate such risks?''. In this paper, first, we propose a holistic framework for Medical data Privacy risk analysis and mitigation in Federated Learning (MedPFL) to analyze privacy risks and develop effective mitigation strategies in FL for protecting private medical data. Second, we demonstrate the substantial privacy risks of using FL to process medical images, where adversaries can easily perform privacy attacks to reconstruct private medical images accurately. Third, we show that the defense approach of adding random noises may not always work effectively to protect medical images against privacy attacks in FL, which poses unique and pressing challenges associated with medical data for privacy protection.