 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning in Healthcare: An In-Depth Analysis
Feb 12, 2023Deep learning (DL) along with never-ending advancements in computational processing and cloud technologies have bestowed us powerful analyzing tools and techniques in the past decade and enabled us to use and apply them in various fields of study. Health informatics is not an exception, and conversely, is the discipline that generates the most amount of data in today's era and can benefit from DL the most. Extracting features and finding complex patterns from a huge amount of raw data and transforming them into knowledge is a challenging task. Besides, various DL architectures have been proposed by researchers throughout the years to tackle different problems. In this paper, we provide a review of DL models and their broad application in bioinformatics and healthcare categorized by their architecture. In addition, we also go over some of the key challenges that still exist and can show up while conducting DL research.
3D-model ShapeNet Core Classification using Meta-Semantic Learning
May 28, 2022
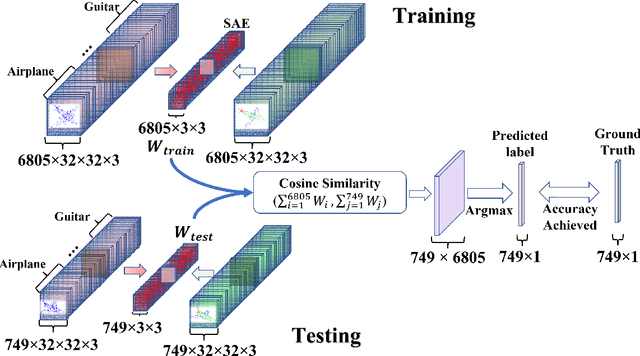

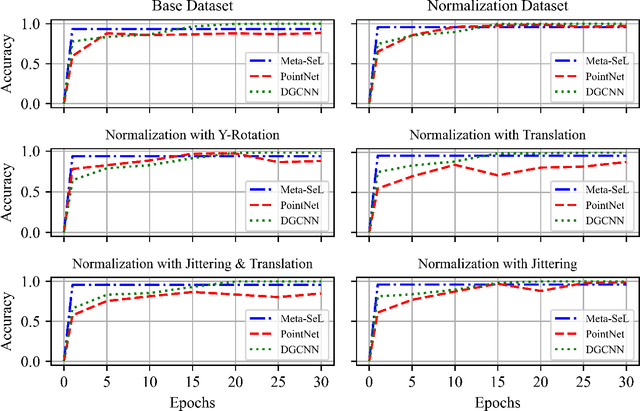
Understanding 3D point cloud models for learning purposes has become an imperative challenge for real-world identification such as autonomous driving systems. A wide variety of solutions using deep learning have been proposed for point cloud segmentation, object detection, and classification. These methods, however, often require a considerable number of model parameters and are computationally expensive. We study a semantic dimension of given 3D data points and propose an efficient method called Meta-Semantic Learning (Meta-SeL). Meta-SeL is an integrated framework that leverages two input 3D local points (input 3D models and part-segmentation labels), providing a time and cost-efficient, and precise projection model for a number of 3D recognition tasks. The results indicate that Meta-SeL yields competitive performance in comparison with other complex state-of-the-art work. Moreover, being random shuffle invariant, Meta-SeL is resilient to translation as well as jittering noise.
Applications of Machine Learning in Healthcare and Internet of Things : A Comprehensive Review
Feb 06, 2022


In recent years, smart healthcare IoT devices have become ubiquitous, but they work in isolated networks due to their policy. Having these devices connected in a network enables us to perform medical distributed data analysis. However, the presence of diverse IoT devices in terms of technology, structure, and network policy, makes it a challenging issue while applying traditional centralized learning algorithms on decentralized data collected from the IoT devices. In this study, we present an extensive review of the state-of-the-art machine learning applications particularly in healthcare, challenging issues in IoT, and corresponding promising solutions. Finally, we highlight some open-ended issues of IoT in healthcare that leaves further research studies and investigation for scientists.
The application of Evolutionary and Nature Inspired Algorithms in Data Science and Data Analytics
Feb 06, 2022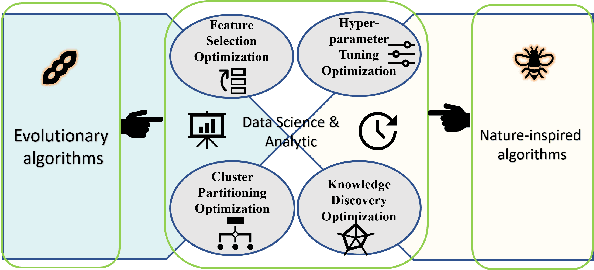

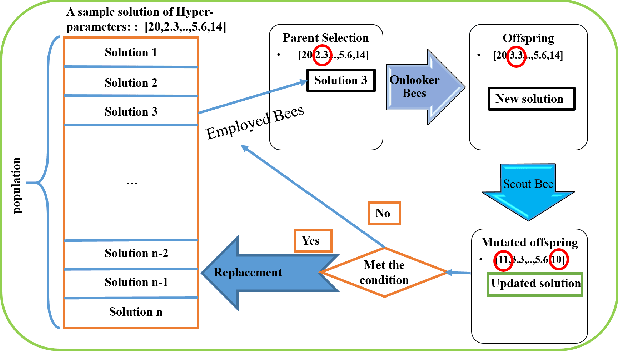
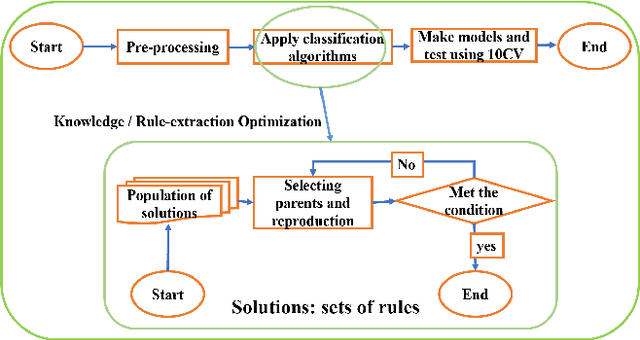
In the past 30 years, scientists have searched nature, including animals and insects, and biology in order to discover, understand, and model solutions for solving large-scale science challenges. The study of bionics reveals that how the biological structures, functions found in nature have improved our modern technologies. In this study, we present our discovery of evolutionary and nature-inspired algorithms applications in Data Science and Data Analytics in three main topics of pre-processing, supervised algorithms, and unsupervised algorithms. Among all applications, in this study, we aim to investigate four optimization algorithms that have been performed using the evolutionary and nature-inspired algorithms within data science and analytics. Feature selection optimization in pre-processing section, Hyper-parameter tuning optimization, and knowledge discovery optimization in supervised algorithms, and clustering optimization in the unsupervised algorithms.
Data Analytics for Smart cities: Challenges and Promises
Sep 12, 2021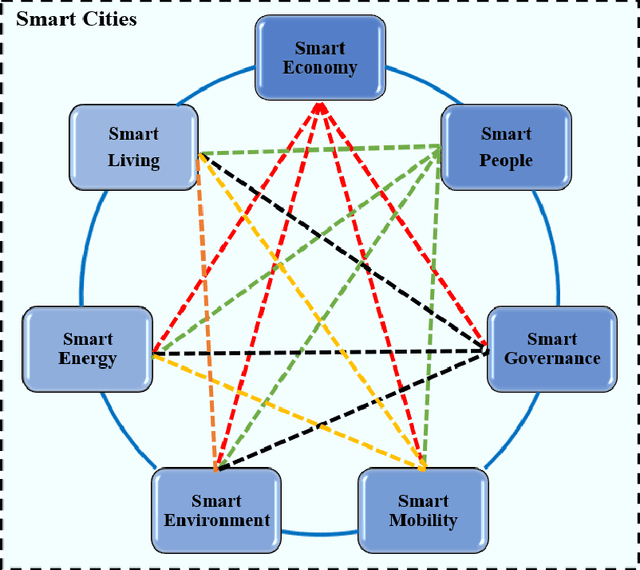
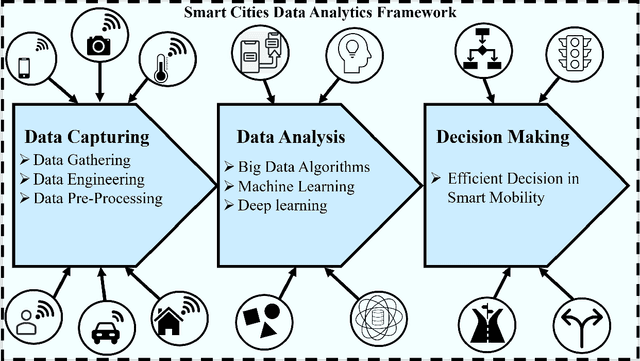
The explosion of advancements in artificial intelligence, sensor technologies, and wireless communication activates ubiquitous sensing through distributed sensors. These sensors are various domains of networks that lead us to smart systems in healthcare, transportation, environment, and other relevant branches/networks. Having collaborative interaction among the smart systems connects end-user devices to each other which enables achieving a new integrated entity called Smart Cities. The goal of this study is to provide a comprehensive survey of data analytics in smart cities. In this paper, we aim to focus on one of the smart cities important branches, namely Smart Mobility, and its positive ample impact on the smart cities decision-making process. Intelligent decision-making systems in smart mobility offer many advantages such as saving energy, relaying city traffic, and more importantly, reducing air pollution by offering real-time useful information and imperative knowledge. Making a decision in smart cities in time is challenging due to various and high dimensional factors and parameters, which are not frequently collected. In this paper, we first address current challenges in smart cities and provide an overview of potential solutions to these challenges. Then, we offer a framework of these solutions, called universal smart cities decision making, with three main sections of data capturing, data analysis, and decision making to optimize the smart mobility within smart cities. With this framework, we elaborate on fundamental concepts of big data, machine learning, and deep leaning algorithms that have been applied to smart cities and discuss the role of these algorithms in decision making for smart mobility in smart cities.
Embodied AI-Driven Operation of Smart Cities: A Concise Review
Aug 22, 2021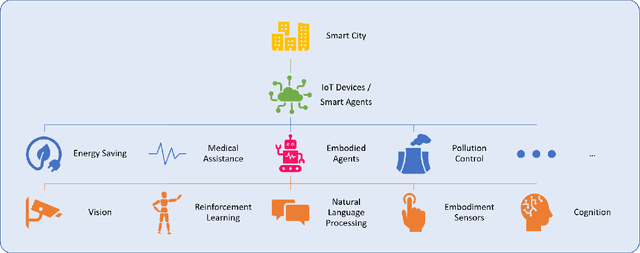
A smart city can be seen as a framework, comprised of Information and Communication Technologies (ICT). An intelligent network of connected devices that collect data with their sensors and transmit them using cloud technologies in order to communicate with other assets in the ecosystem plays a pivotal role in this framework. Maximizing the quality of life of citizens, making better use of resources, cutting costs, and improving sustainability are the ultimate goals that a smart city is after. Hence, data collected from connected devices will continuously get thoroughly analyzed to gain better insights into the services that are being offered across the city; with this goal in mind that they can be used to make the whole system more efficient. Robots and physical machines are inseparable parts of a smart city. Embodied AI is the field of study that takes a deeper look into these and explores how they can fit into real-world environments. It focuses on learning through interaction with the surrounding environment, as opposed to Internet AI which tries to learn from static datasets. Embodied AI aims to train an agent that can See (Computer Vision), Talk (NLP), Navigate and Interact with its environment (Reinforcement Learning), and Reason (General Intelligence), all at the same time. Autonomous driving cars and personal companions are some of the examples that benefit from Embodied AI nowadays. In this paper, we attempt to do a concise review of this field. We will go through its definitions, its characteristics, and its current achievements along with different algorithms, approaches, and solutions that are being used in different components of it (e.g. Vision, NLP, RL). We will then explore all the available simulators and 3D interactable databases that will make the research in this area feasible. Finally, we will address its challenges and identify its potentials for future research.
DRDrV3: Complete Lesion Detection in Fundus Images Using Mask R-CNN, Transfer Learning, and LSTM
Aug 18, 2021

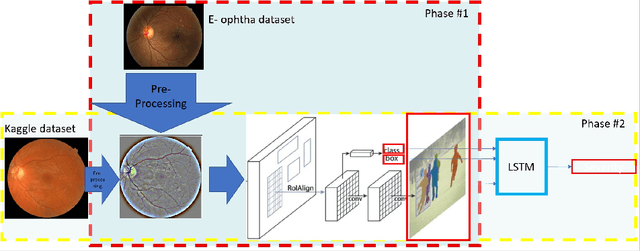

Medical Imaging is one of the growing fields in the world of computer vision. In this study, we aim to address the Diabetic Retinopathy (DR) problem as one of the open challenges in medical imaging. In this research, we propose a new lesion detection architecture, comprising of two sub-modules, which is an optimal solution to detect and find not only the type of lesions caused by DR, their corresponding bounding boxes, and their masks; but also the severity level of the overall case. Aside from traditional accuracy, we also use two popular evaluation criteria to evaluate the outputs of our models, which are intersection over union (IOU) and mean average precision (mAP). We hypothesize that this new solution enables specialists to detect lesions with high confidence and estimate the severity of the damage with high accuracy.
Malware Detection using Artificial Bee Colony Algorithm
Dec 01, 2020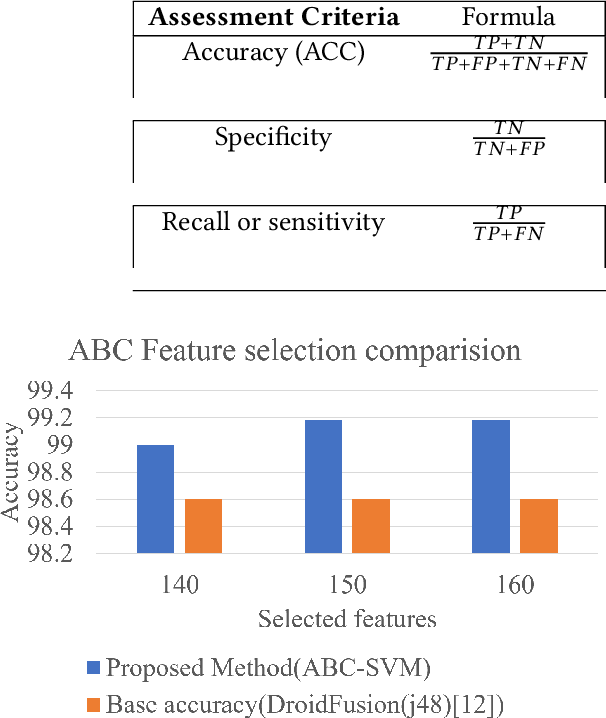

Malware detection has become a challenging task due to the increase in the number of malware families. Universal malware detection algorithms that can detect all the malware families are needed to make the whole process feasible. However, the more universal an algorithm is, the higher number of feature dimensions it needs to work with, and that inevitably causes the emerging problem of Curse of Dimensionality (CoD). Besides, it is also difficult to make this solution work due to the real-time behavior of malware analysis. In this paper, we address this problem and aim to propose a feature selection based malware detection algorithm using an evolutionary algorithm that is referred to as Artificial Bee Colony (ABC). The proposed algorithm enables researchers to decrease the feature dimension and as a result, boost the process of malware detection. The experimental results reveal that the proposed method outperforms the state-of-the-art.
DRDr II: Detecting the Severity Level of Diabetic Retinopathy Using Mask RCNN and Transfer Learning
Nov 30, 2020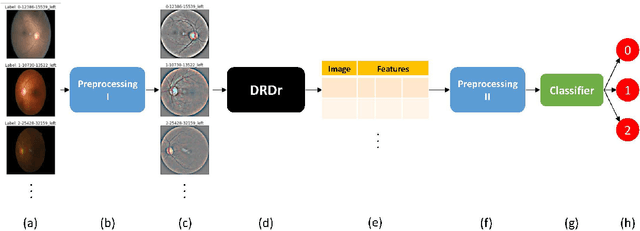
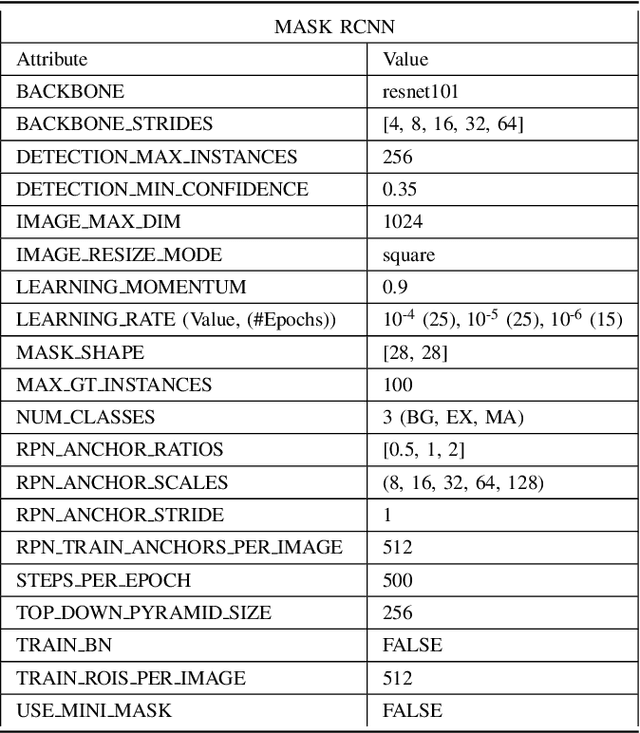
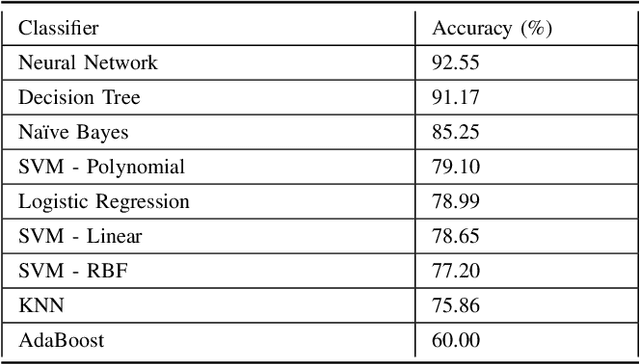
DRDr II is a hybrid of machine learning and deep learning worlds. It builds on the successes of its antecedent, namely, DRDr, that was trained to detect, locate, and create segmentation masks for two types of lesions (exudates and microaneurysms) that can be found in the eyes of the Diabetic Retinopathy (DR) patients; and uses the entire model as a solid feature extractor in the core of its pipeline to detect the severity level of the DR cases. We employ a big dataset with over 35 thousand fundus images collected from around the globe and after 2 phases of preprocessing alongside feature extraction, we succeed in predicting the correct severity levels with over 92% accuracy.
DeepMSRF: A novel Deep Multimodal Speaker Recognition framework with Feature selection
Jul 21, 2020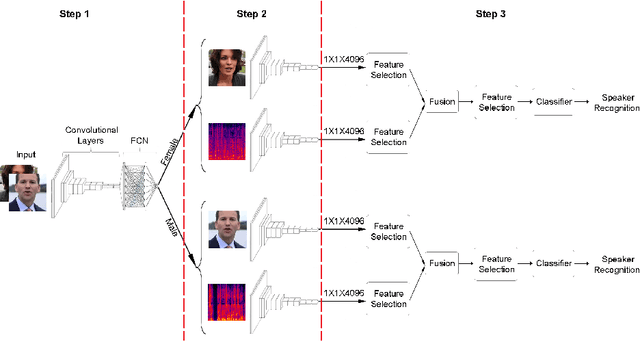
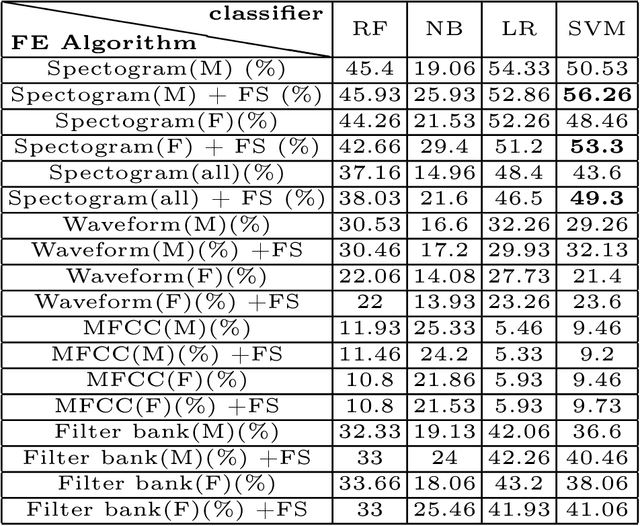
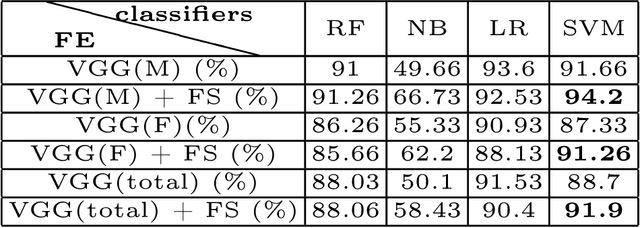
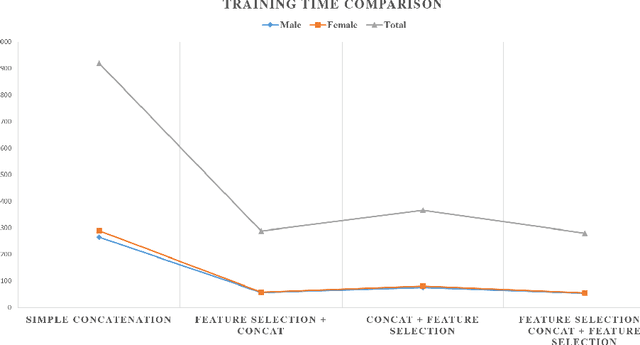
For recognizing speakers in video streams, significant research studies have been made to obtain a rich machine learning model by extracting high-level speaker's features such as facial expression, emotion, and gender. However, generating such a model is not feasible by using only single modality feature extractors that exploit either audio signals or image frames, extracted from video streams. In this paper, we address this problem from a different perspective and propose an unprecedented multimodality data fusion framework called DeepMSRF, Deep Multimodal Speaker Recognition with Feature selection. We execute DeepMSRF by feeding features of the two modalities, namely speakers' audios and face images. DeepMSRF uses a two-stream VGGNET to train on both modalities to reach a comprehensive model capable of accurately recognizing the speaker's identity. We apply DeepMSRF on a subset of VoxCeleb2 dataset with its metadata merged with VGGFace2 dataset. The goal of DeepMSRF is to identify the gender of the speaker first, and further to recognize his or her name for any given video stream. The experimental results illustrate that DeepMSRF outperforms single modality speaker recognition methods with at least 3 percent accuracy.