 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual IRL for Human-Like Robotic Manipulation
Dec 16, 2024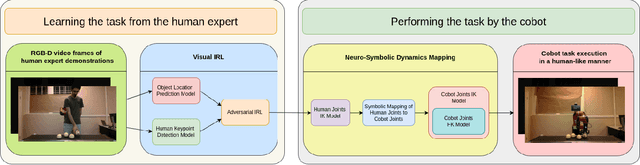

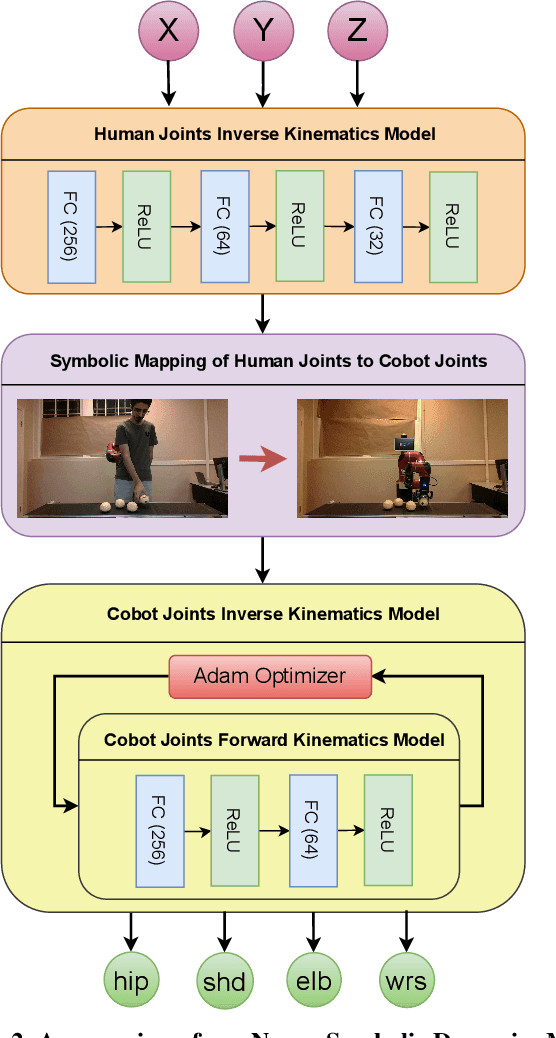
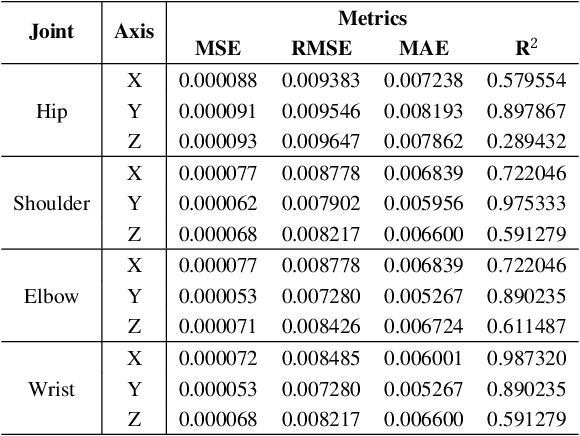
We present a novel method for collaborative robots (cobots) to learn manipulation tasks and perform them in a human-like manner. Our method falls under the learn-from-observation (LfO) paradigm, where robots learn to perform tasks by observing human actions, which facilitates quicker integration into industrial settings compared to programming from scratch. We introduce Visual IRL that uses the RGB-D keypoints in each frame of the observed human task performance directly as state features, which are input to inverse reinforcement learning (IRL). The inversely learned reward function, which maps keypoints to reward values, is transferred from the human to the cobot using a novel neuro-symbolic dynamics model, which maps human kinematics to the cobot arm. This model allows similar end-effector positioning while minimizing joint adjustments, aiming to preserve the natural dynamics of human motion in robotic manipulation. In contrast with previous techniques that focus on end-effector placement only, our method maps multiple joint angles of the human arm to the corresponding cobot joints. Moreover, it uses an inverse kinematics model to then minimally adjust the joint angles, for accurate end-effector positioning. We evaluate the performance of this approach on two different realistic manipulation tasks. The first task is produce processing, which involves picking, inspecting, and placing onions based on whether they are blemished. The second task is liquid pouring, where the robot picks up bottles, pours the contents into designated containers, and disposes of the empty bottles. Our results demonstrate advances in human-like robotic manipulation, leading to more human-robot compatibility in manufacturing applications.
MVSA-Net: Multi-View State-Action Recognition for Robust and Deployable Trajectory Generation
Nov 18, 2023The learn-from-observation (LfO) paradigm is a human-inspired mode for a robot to learn to perform a task simply by watching it being performed. LfO can facilitate robot integration on factory floors by minimizing disruption and reducing tedious programming. A key component of the LfO pipeline is a transformation of the depth camera frames to the corresponding task state and action pairs, which are then relayed to learning techniques such as imitation or inverse reinforcement learning for understanding the task parameters. While several existing computer vision models analyze videos for activity recognition, SA-Net specifically targets robotic LfO from RGB-D data. However, SA-Net and many other models analyze frame data captured from a single viewpoint. Their analysis is therefore highly sensitive to occlusions of the observed task, which are frequent in deployments. An obvious way of reducing occlusions is to simultaneously observe the task from multiple viewpoints and synchronously fuse the multiple streams in the model. Toward this, we present multi-view SA-Net, which generalizes the SA-Net model to allow the perception of multiple viewpoints of the task activity, integrate them, and better recognize the state and action in each frame. Performance evaluations on two distinct domains establish that MVSA-Net recognizes the state-action pairs under occlusion more accurately compared to single-view MVSA-Net and other baselines. Our ablation studies further evaluate its performance under different ambient conditions and establish the contribution of the architecture components. As such, MVSA-Net offers a significantly more robust and deployable state-action trajectory generation compared to previous methods.
Curious Exploration and Return-based Memory Restoration for Deep Reinforcement Learning
May 02, 2021
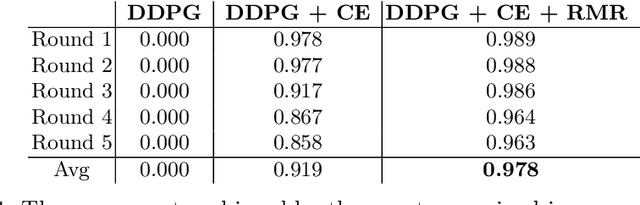


Reward engineering and designing an incentive reward function are non-trivial tasks to train agents in complex environments. Furthermore, an inaccurate reward function may lead to a biased behaviour which is far from an efficient and optimised behaviour. In this paper, we focus on training a single agent to score goals with binary success/failure reward function in Half Field Offense domain. As the major advantage of this research, the agent has no presumption about the environment which means it only follows the original formulation of reinforcement learning agents. The main challenge of using such a reward function is the high sparsity of positive reward signals. To address this problem, we use a simple prediction-based exploration strategy (called Curious Exploration) along with a Return-based Memory Restoration (RMR) technique which tends to remember more valuable memories. The proposed method can be utilized to train agents in environments with fairly complex state and action spaces. Our experimental results show that many recent solutions including our baseline method fail to learn and perform in complex soccer domain. However, the proposed method can converge easily to the nearly optimal behaviour. The video presenting the performance of our trained agent is available at http://bit.ly/HFO_Binary_Reward.
DeepMSRF: A novel Deep Multimodal Speaker Recognition framework with Feature selection
Jul 21, 2020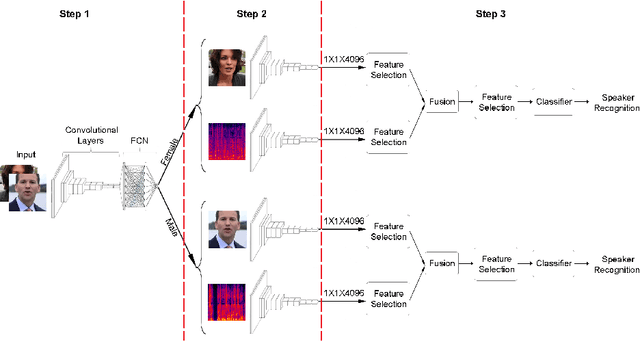
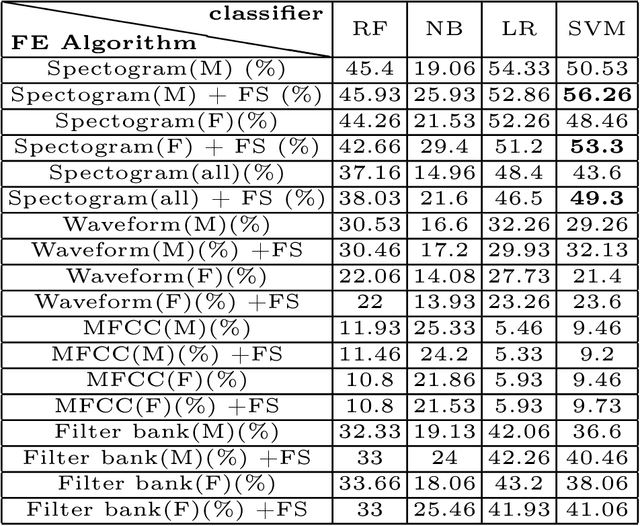
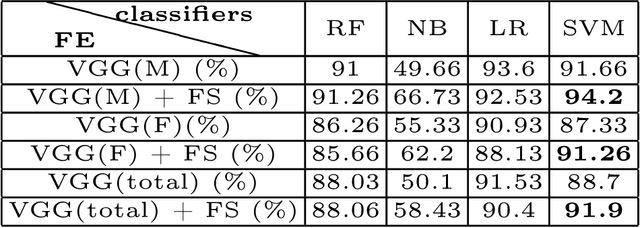
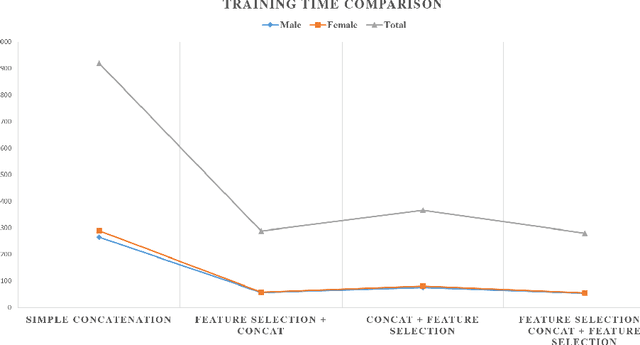
For recognizing speakers in video streams, significant research studies have been made to obtain a rich machine learning model by extracting high-level speaker's features such as facial expression, emotion, and gender. However, generating such a model is not feasible by using only single modality feature extractors that exploit either audio signals or image frames, extracted from video streams. In this paper, we address this problem from a different perspective and propose an unprecedented multimodality data fusion framework called DeepMSRF, Deep Multimodal Speaker Recognition with Feature selection. We execute DeepMSRF by feeding features of the two modalities, namely speakers' audios and face images. DeepMSRF uses a two-stream VGGNET to train on both modalities to reach a comprehensive model capable of accurately recognizing the speaker's identity. We apply DeepMSRF on a subset of VoxCeleb2 dataset with its metadata merged with VGGFace2 dataset. The goal of DeepMSRF is to identify the gender of the speaker first, and further to recognize his or her name for any given video stream. The experimental results illustrate that DeepMSRF outperforms single modality speaker recognition methods with at least 3 percent accuracy.
Namira Soccer 2D Simulation Team Description Paper 2020
Jun 24, 2020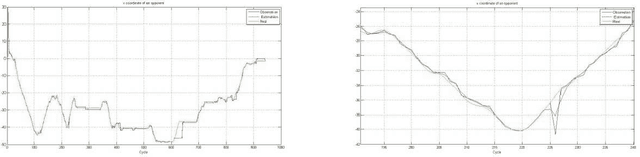
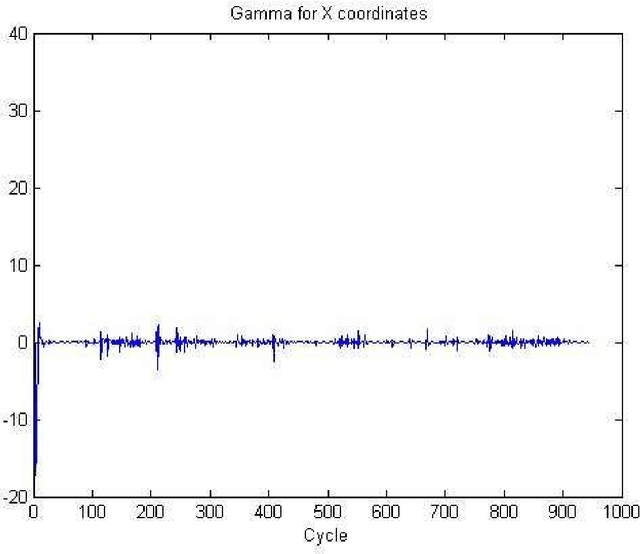
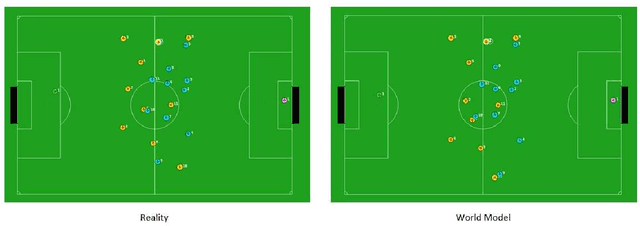
In this article, we will discuss methods and ideas which are implemented on Namira 2D Soccer Simulation team in the recent year. Numerous scientific and programming activities were done in the process of code development, but we will mention the most outstanding ones in details. A Kalman filtering method for localization and two helpful software packages will be discussed here. Namira uses agent2d-3.1.1 as base code and librcsc-4.1.0 as library with some deliberate changes.